TIL that the web pages for digitised works (like books and journal issues) on @TroveAustralia embed a lot of useful metadata that you can’t get through the API. Here’s how to extract it.
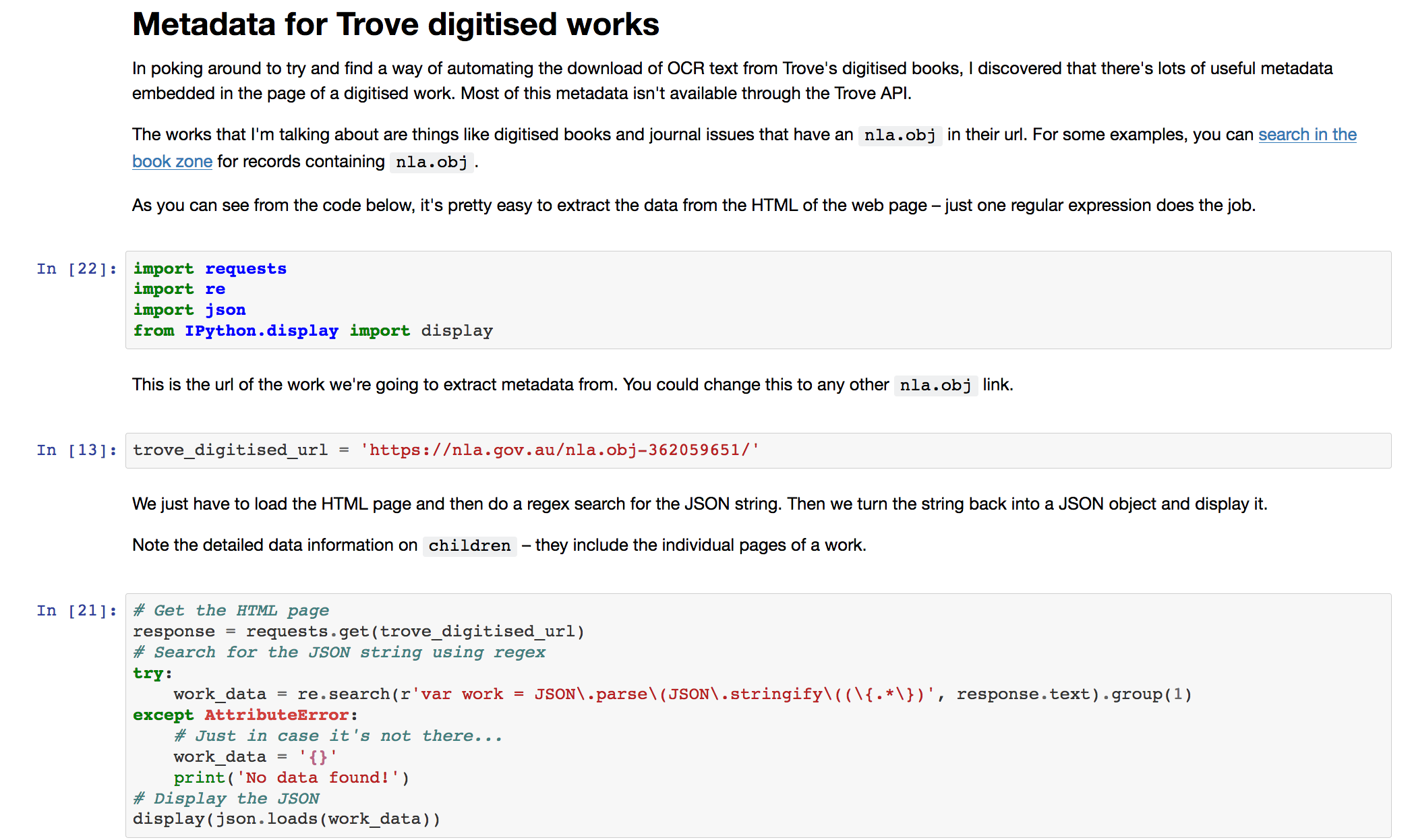
TIL that the web pages for digitised works (like books and journal issues) on @TroveAustralia embed a lot of useful metadata that you can’t get through the API. Here’s how to extract it.