Download & explore 1,499,259 rows of open data from NSW State Archives Online Indexes
NSW State Archives publishes a number of detailed indexes containing data manually extracted from their records. These provide additional entry points to the records, such as a person’s name, or a place. But they also provide useful data for analysis. However, to explore the index data we need to get it out of the web interface and into a form that can be easily downloaded and manipulated.
I’ve created a series of Jupyter notebooks to harvest the all the indexes and save the data in a series of CSV-formatted files. I’ve also updated my repository containing all the harvested CSV files. It’s available from the new NSW State Archives section of my GLAM Workbench. There are currently 64 different index datasets, containing 1,499,259 rows of data.
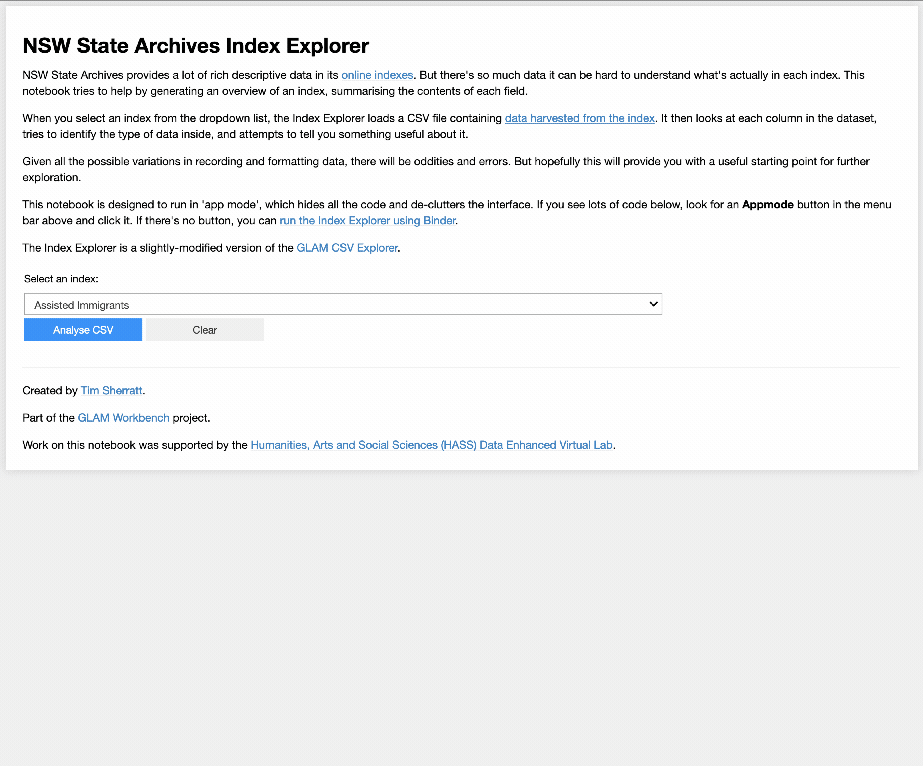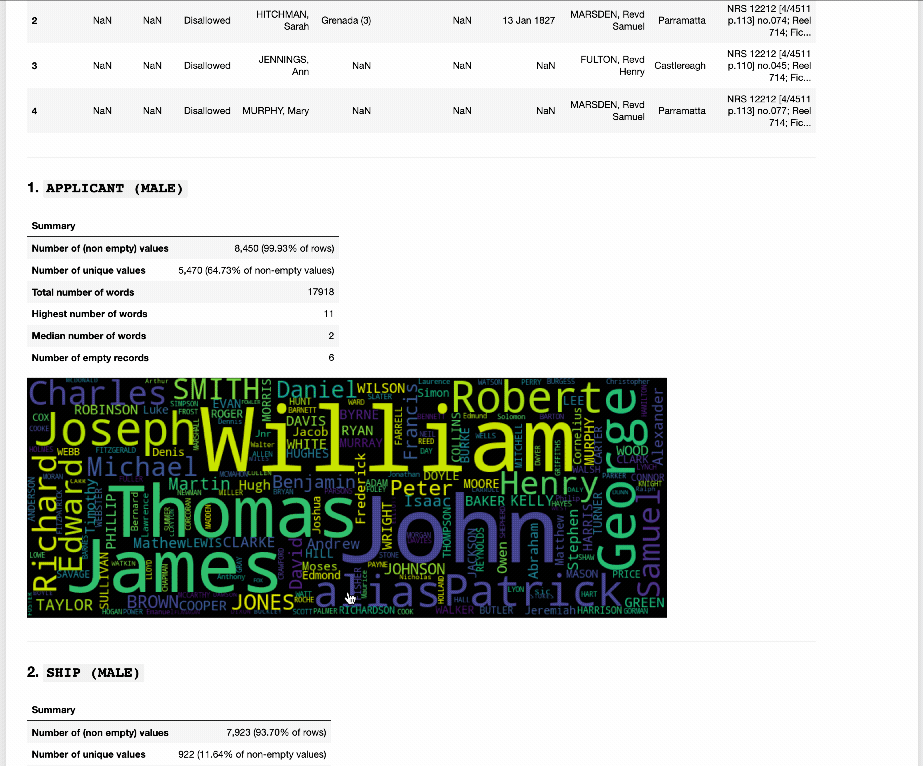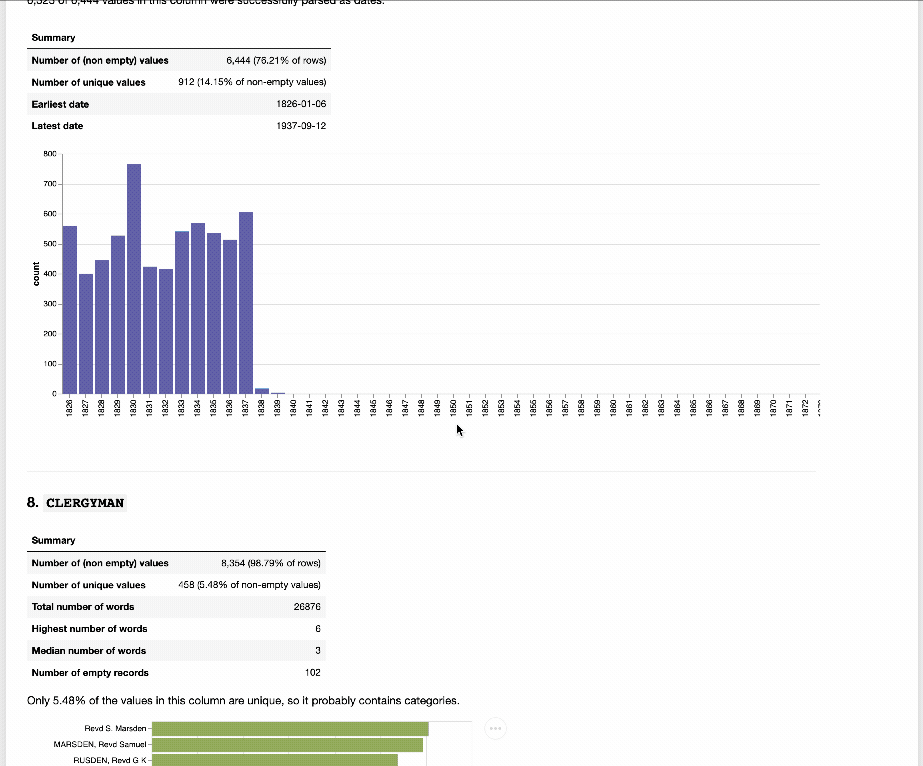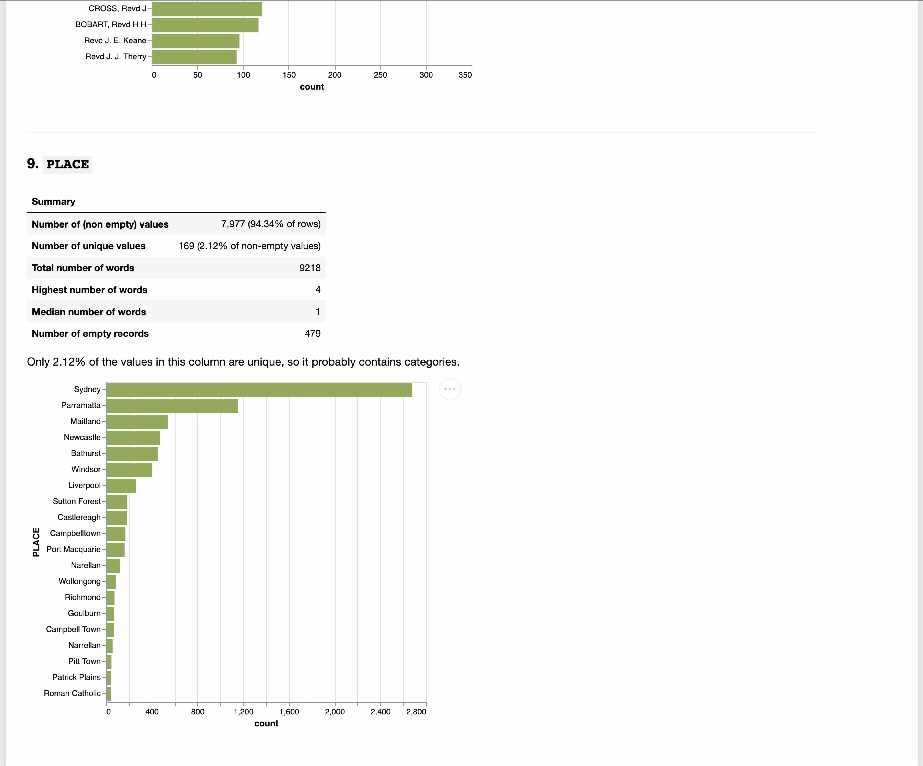
And to help you get a sense of what’s actually in all those CSV files, I’ve created an interactive Index Explorer. Just select an index from the list, and the Index Explorer will generate a series of tables and visualisations that provide an overview of the data. Try running it live on Binder.
Thanks to the State Archives staff and volunteers for preparing all this most excellent data. #dhhacks