New GLAM Workbench section on web archives!
We tend to think of a web archive as a site we go to when links are broken – a useful fallback, rather than a source of new research data. But web archives don’t just store old web pages, they capture multiple versions of web resources over time. Using web archives we can observe change – we can ask historical questions. But web archives store huge amounts of data, and access is often limited for legal reasons. Just knowing what data is available and how to get to it can be difficult. Where do you start?
The GLAM Workbench’s new web archives section can help! Here you’ll find a collection of Jupyter notebooks that document web archive data sources and standards, and walk through methods of harvesting, analysing, and visualising that data. It’s a mix of examples, explorations, apps and tools. The notebooks use existing APIs to get data in manageable chunks, but many of the examples demonstrated can also be scaled up to build substantial datasets for research – you just have to be patient!
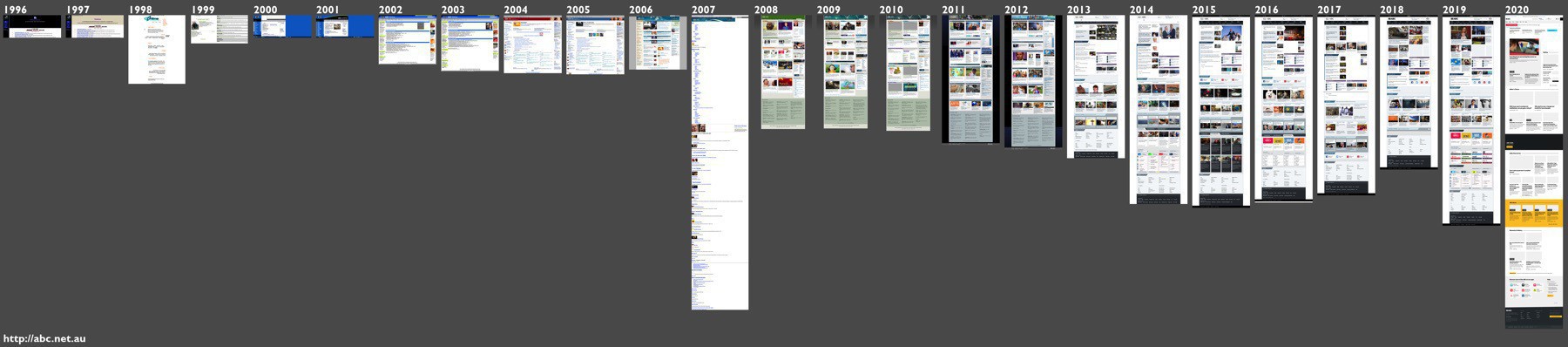
Have you ever wanted to find when a particular fragment of text first appeared in a web page? Or compare full-page screenshots of archived sites? Perhaps you want to explore how the text content of a page has changed over time, or create a side-by-side comparison of web archive captures. There are notebooks to help you with all of these.
To dig deeper you might want to assemble a dataset of text extracted from archived web pages, construct your own database of archived Powerpoint files, or explore patterns within a whole domain. The notebooks provide a range of approaches that can be extended or modified according to your research questions.
The development of these notebooks was supported by the International Internet Preservation Consortium’s Discretionary Funding Programme 2019-2020, with the participation of the British Library, the National Library of Australia, and the National Library of New Zealand. #dhhacks