New dataset and notebooks – twenty years of ABC Radio National
There’s a new GLAM Workbench section for working with data from Trove’s Music & Sound zone!
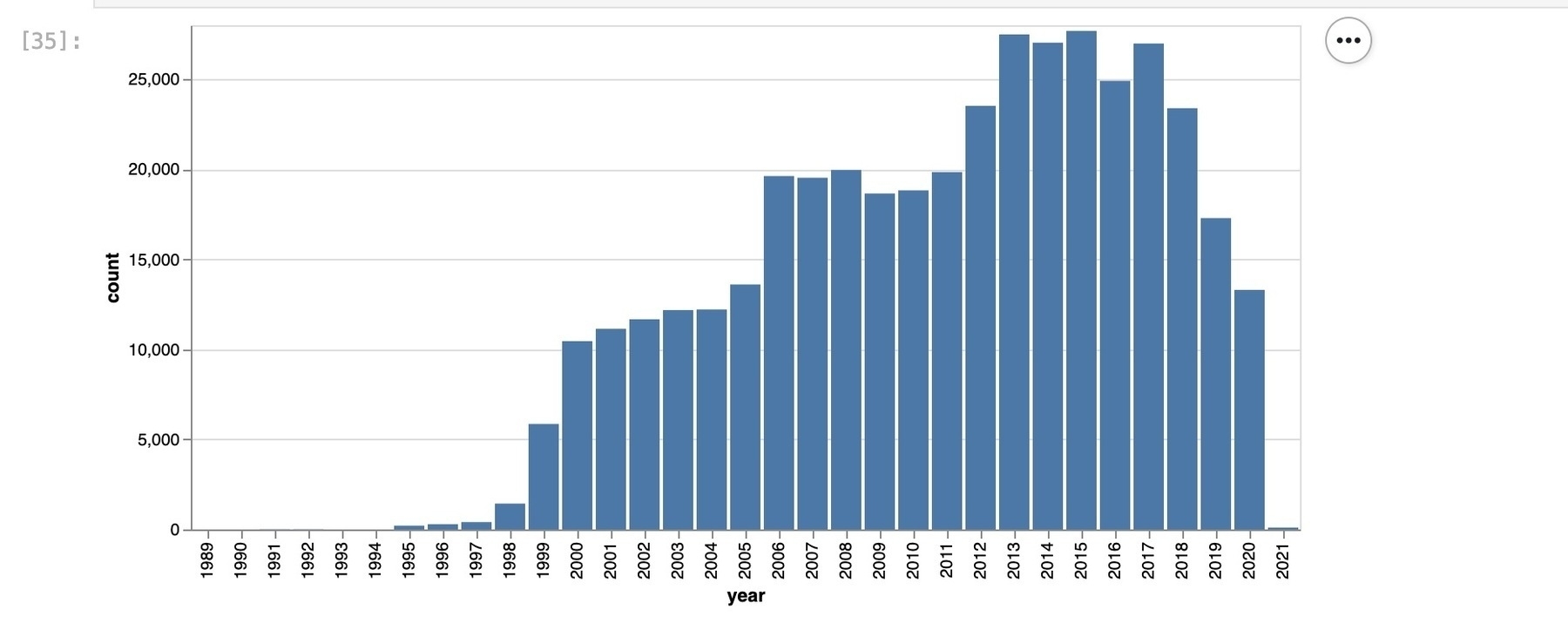
Inside you’ll find out how to harvest all the metadata from ABC Radio National program records – that’s 400,000+ records, from 160 Radio National programs, over more than 20 years.
It’s metadata only, so not full transcripts or audio, though there are links back to the ABC site where you might find transcripts. Most records should at least have a title, a date, the name of the program it was broadcast on, a list of contributors, and perhaps a brief abstract/summary. It’s also worth noting that many of these records, particularly those from the main current affairs programs, represent individual stories or segments – so they provide a detailed record of the major news stories for the last couple of decades!
The harvesting notebook shows you how to get the data from the Trove API. There are a number of duplicate records, and some inconsistencies in the way the data is formatted, so the harvesting code tries to clean things up a bit. You can of course adjust this to meet your own needs.
If you don’t want to do the harvesting yourself, there’s pre-harvested datasets that you can download immediately from Cloudstor and start exploring. The complete harvest of all 400,000+ records is available both in JSONL (newline separated JSON) and CSV formats. There’s also a series of separate datasets for the most frequently occurring programs: RN Breakfast, RN Drive, AM, PM, The World Today, Late Night Live, Life Matters, and the Science Show.
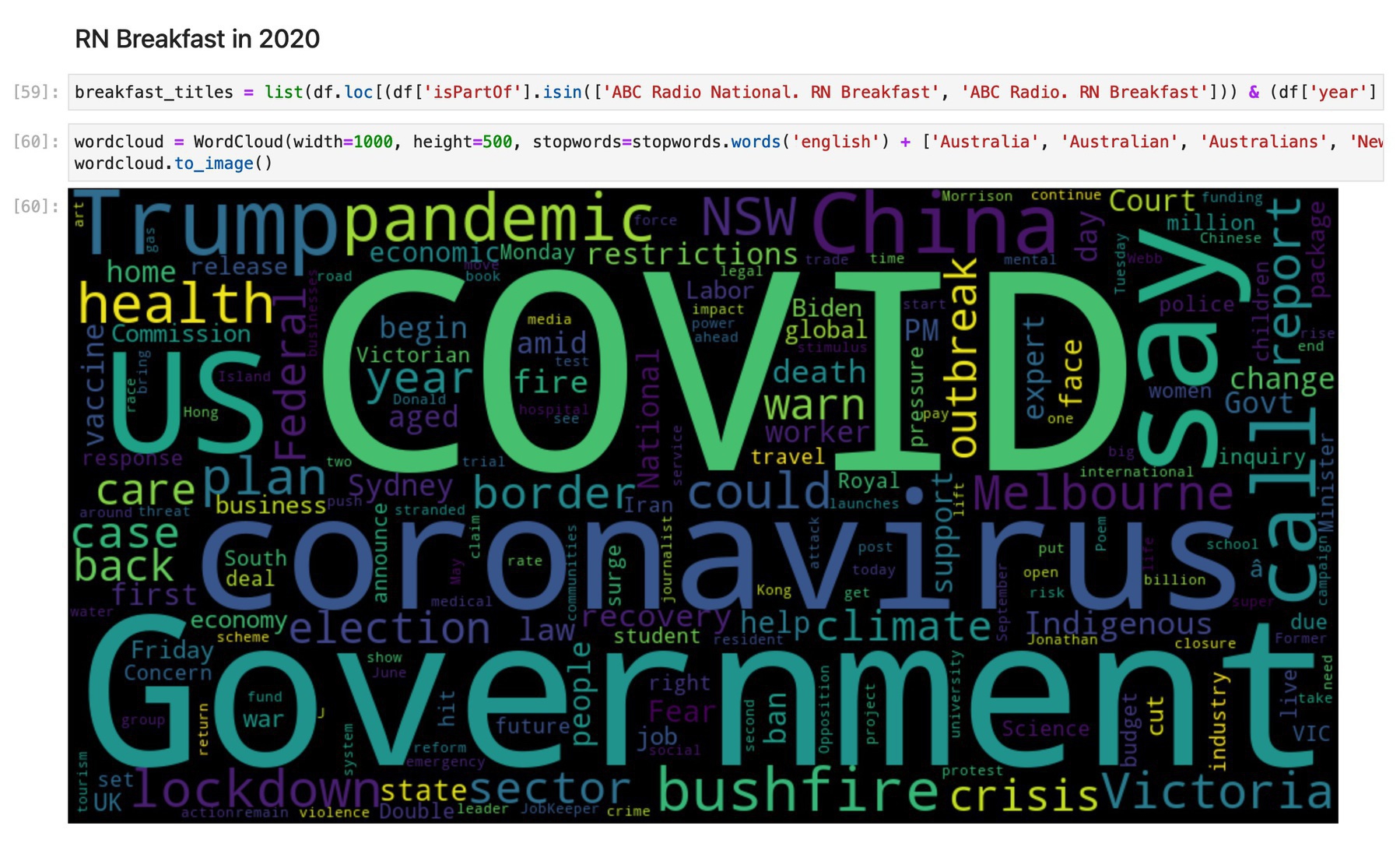
There’s also a notebook that demonstrates a few possible ways you might start to play with the data – looking at the range of programs, the distribution of records over time, the people involved in each story, and words in the titles of each segment.
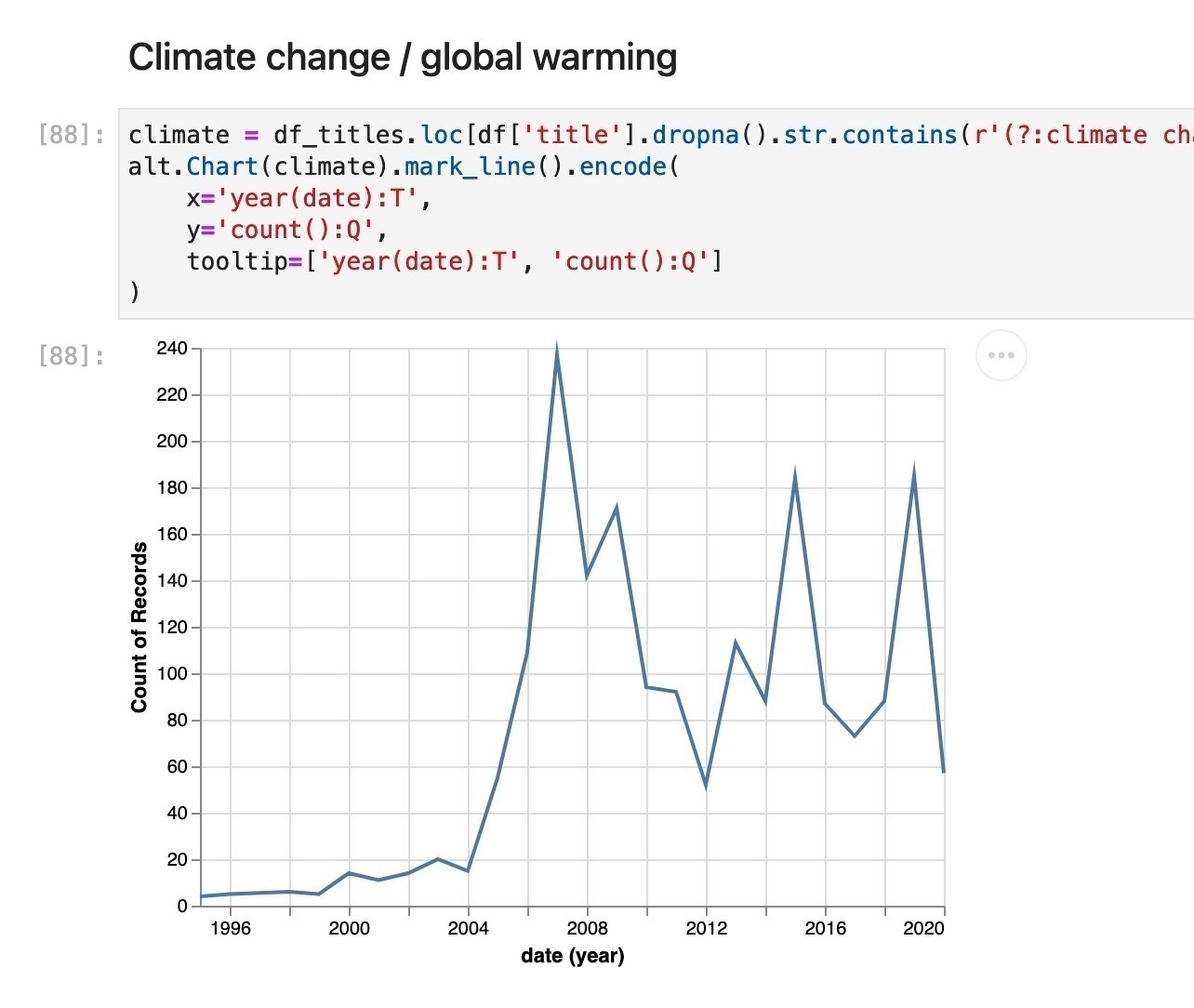
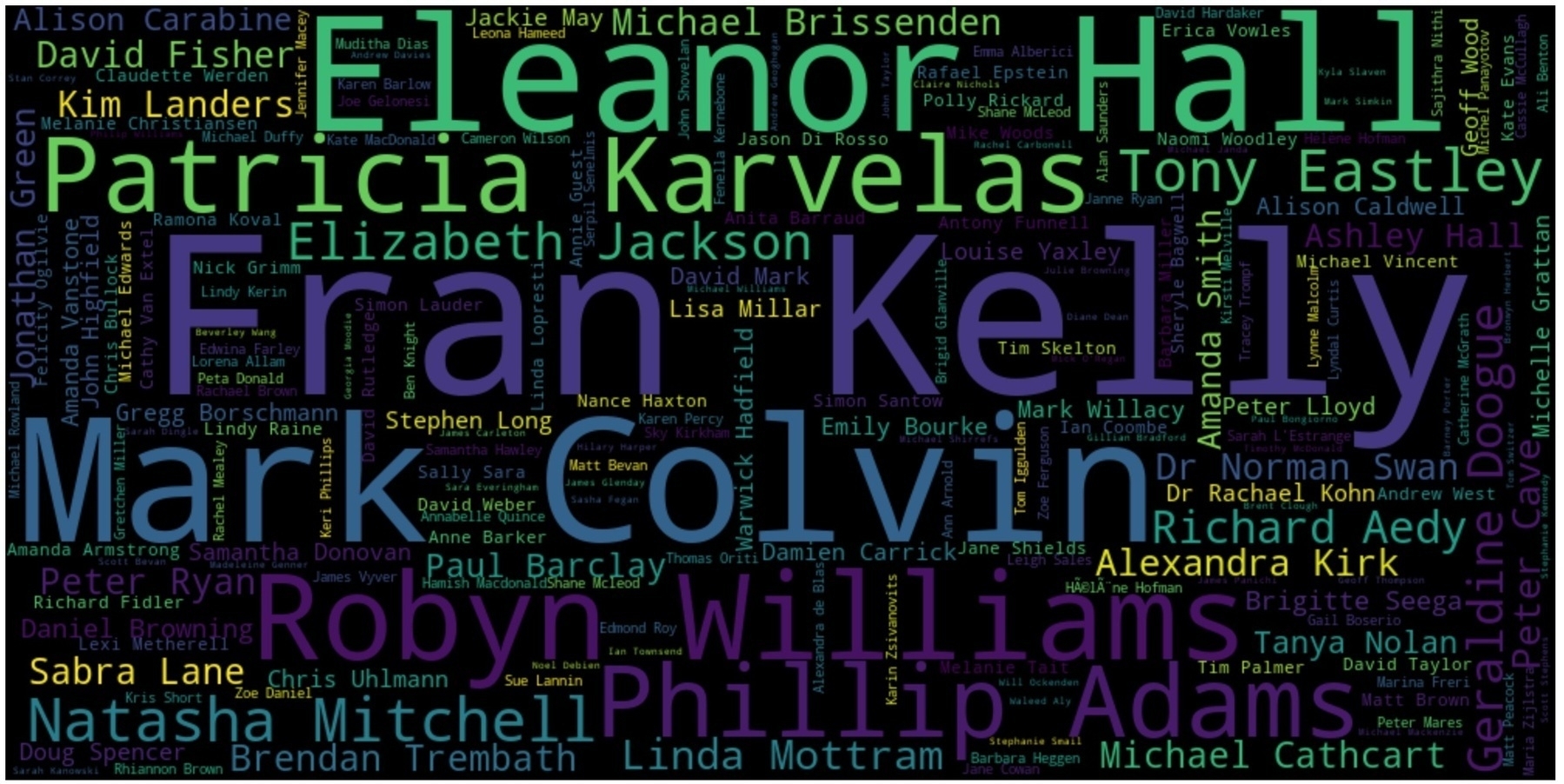
This is a very rich source of data for examining Australia’s political and social history over the last twenty years. Dive in and see what you can find! #dhhacks
