Recently digitised files in the National Archives of Australia
I’m interested in understanding what gets digitised and when by our cultural institutions, but accessible data is scarce. The National Archives of Australia lists ‘newly scanned' records in RecordSearch, so I thought I’d see if I could convert that list into a machine-readable form for analysis. I’ve had a lot of experience trying to get data out of RecordSearch, but even so it took me a while to figure out how the ‘newly scanned’ page worked. Eventually I was able to extract all the file metadata from the list and save it to a CSV file. The details are in this notebook in the GLAM Workbench.
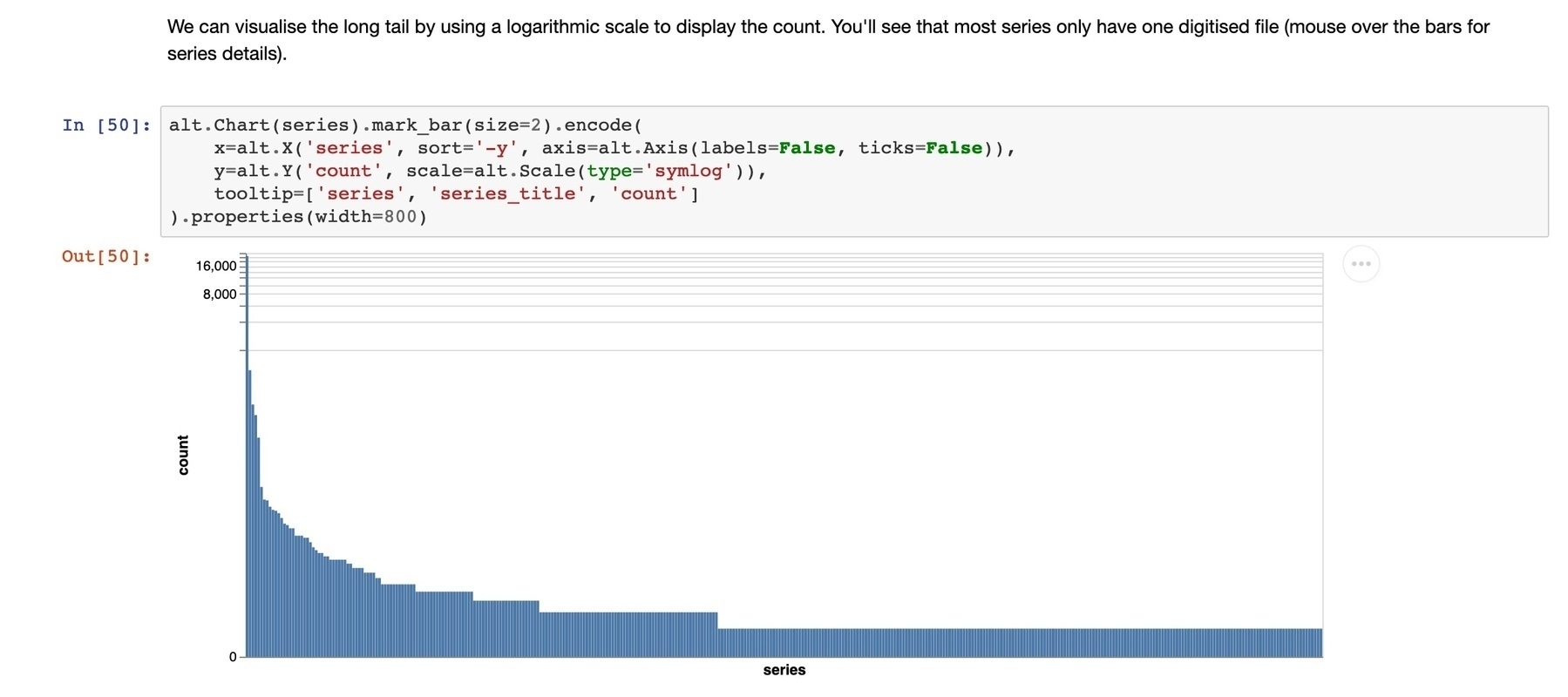
I used the code to create a dataset of all the files digitised in the past month. The ‘newly scanned' list only displays a month’s worth of additions, so that’s as much as I could get in one hit. In the past month, 24,039 files were digitised. 22,500 of these (about 93%) come from just four series of military records. This is no surprise, as the NAA is currently undertaking a major project to digitise WW2 service records. What is perhaps more interesting is the long tail of series from which a small number of files were digitised. 357 of the 375 series represented in the dataset (about 95%) appear 20 or fewer times. 210 series have had only one file digitised in the last month. I’m assuming that this diversity represents research interests, refracted through the digitisation on demand service. But this really needs more data, and more analysis.
As I mentioned, only one month’s data is available from RecordSearch at any time. To try and capture a longer record of the digitisation process, I’ve set up an automated ‘git scraper’ that runs every Sunday and captures metadata of all the files digitised in the preceding week. The weekly datasets are saved as CSV files in a public GitHub repository. Over time, this should become a useful dataset for exploring long-term patterns in digitisation. #dhhacks