Using web archives to find out when newspapers were added to Trove
There’s no doubt that Trove’s digitised newspapers have had a significant impact on the practice of history in Australia. But analysing that impact is difficult when Trove itself is always changing – more newspapers and articles are being added all the time.
In an attempt to chart the development of Trove, I’ve created a dataset that shows (approximately) when particular newspaper titles were first added. This gives a rough snapshot of what Trove contained at any point in the last 12 years.
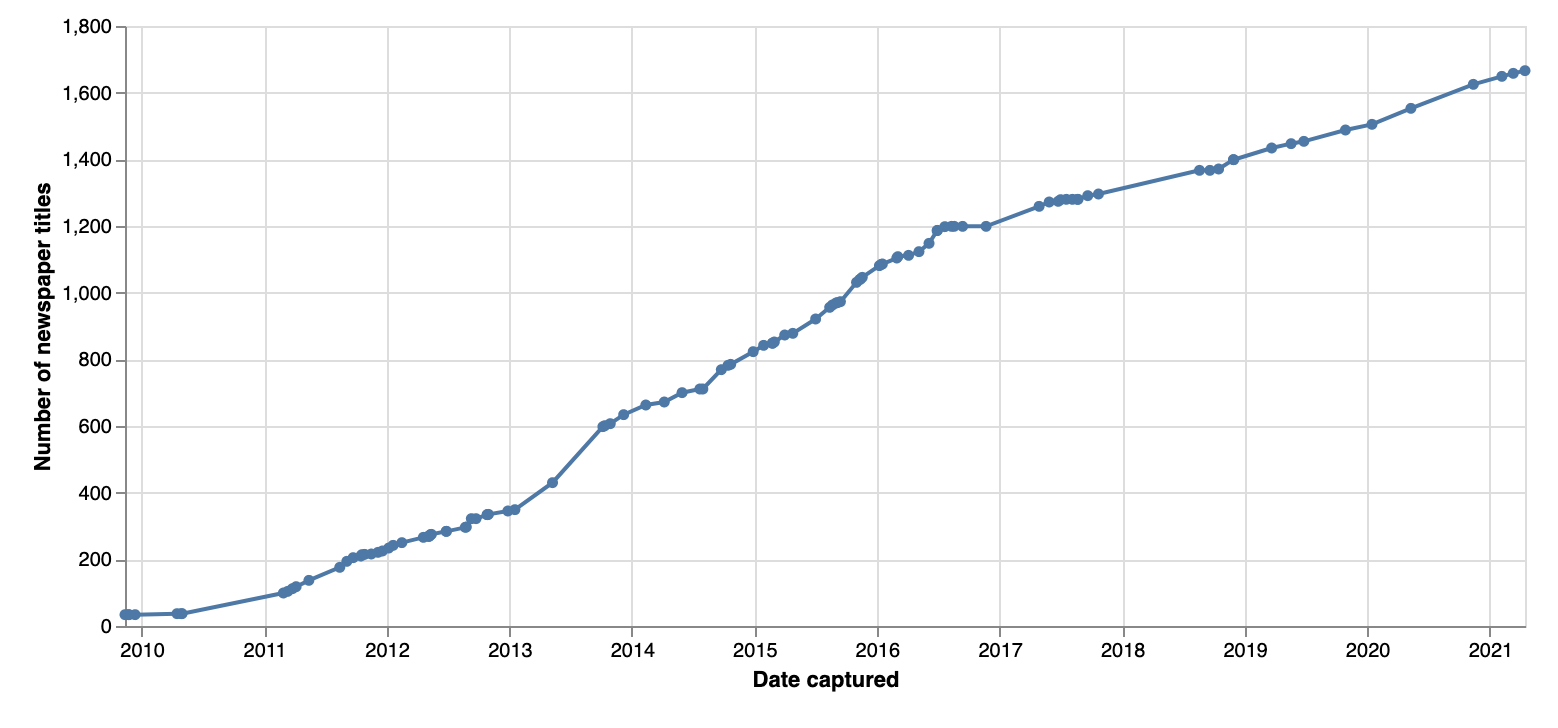
I say approximately because the only public source of this information are web archives like the Internet Archive’s Wayback Machine and Trove itself. By downloading captures of Trove’s browse page, I was able to extract a list of newspaper titles available when that capture was made. Depending on the frequency of captures, the titles may have been first made available some time earlier.
The method I used to create the dataset is documented in the Trove Newspapers section of the GLAM Workbench. I used the Internet Archive as my source rather than Trove just because there were more captures available. Most of the code I could conveniently copy from the Web Archives section of the GLAM Workbench, in particular the Find all the archived versions of a particular web page notebook.
The result was actually two datasets:
- trove_newspaper_titles_2009_2021.csv – complete dataset of captures and titles
- trove_newspaper_titles_first_appearance_2009_2021.csv – filtered dataset, showing only the first appearance of each title / place / date range combination
There’s also an alphabetical list of newspaper titles for easy browsing. The list shows the date of the capture in which the title was first recorded, as well as any changes to its date range. #dhhacks