Explore Trove’s digitised books
The Trove books section of the GLAM Workbench has been updated! There’s freshly-harvested data, as well as updated Python packages, integration with Reclaim Cloud, and automated Docker builds.
Included is a notebook to harvest details of all books available from Trove in digital form. This includes both digitised books, that have been scanned and OCRd, as well as born digital publications, such as PDFs and epubs. The definition of ‘books’ is pretty loose – I’ve harvested details of anything that has been assigned the format ‘Book’ in Trove, but this includes ephemera, such as posters, pamphlets, and advertising.
In the latest harvest, I ended up with details of 42,174 ‘books’. This includes some duplicates, because multiple metadata entries can point to the same digital object. I thought it was best to preserve the duplicates, rather than discard the metadata.
Once I’d harvested the details of the books, I tried to see if there was any OCRd text available for download. If there was, I saved it to a public folder on CloudStor. In total, I was able to download 26,762 files of OCRd text.
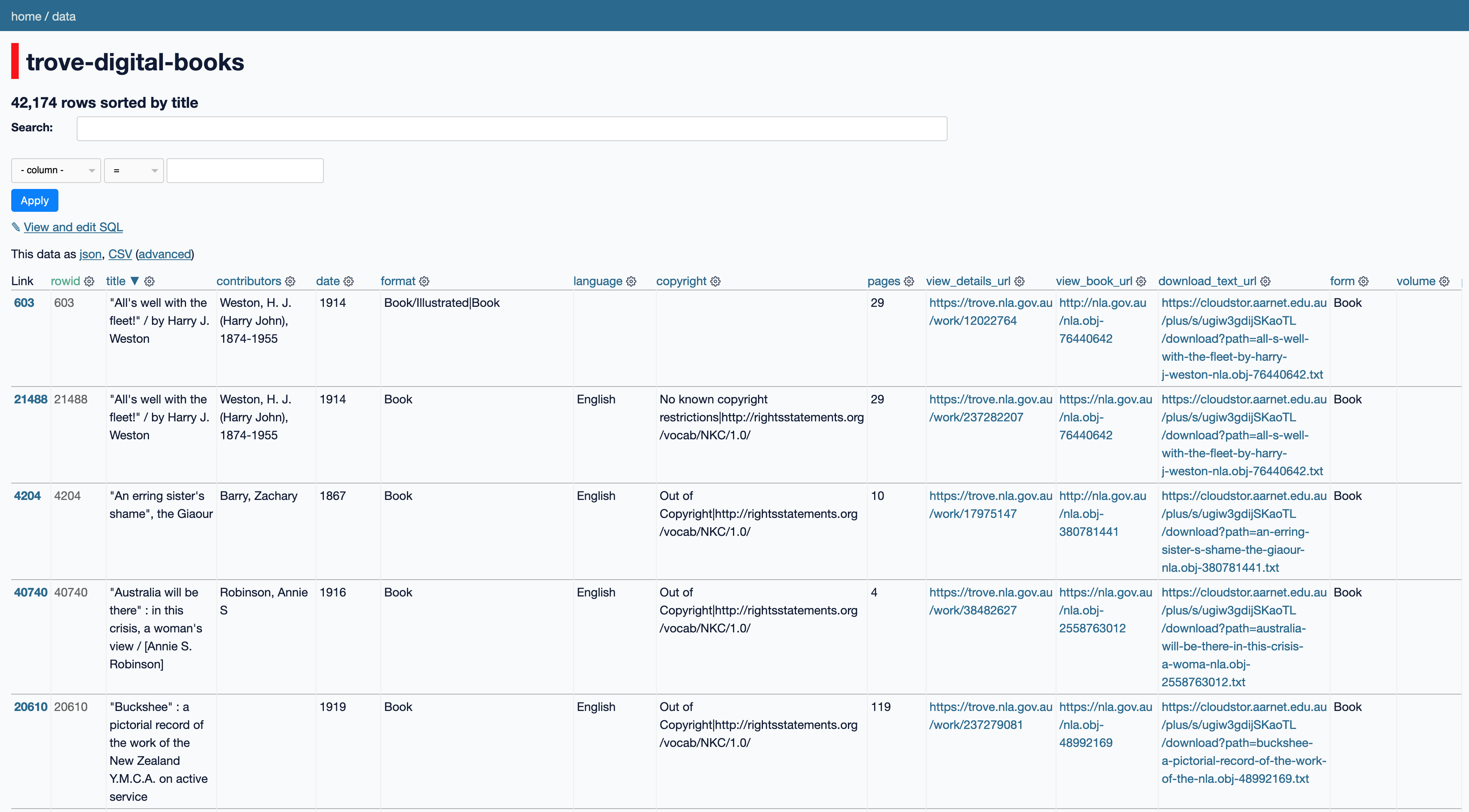
The easiest way to explore the books is using this searchable database. It’s created using Datasette and is running on Glitch. Full text search is available on the ‘title’ and ‘contributors’ fields, and you can filter on things like date, copyright status, number of pages, and whether OCRd text is available for download. If there is OCRd text, a direct link to the file on CloudStor is included. You can use the database to filter the titles, creating your own dataset that you can download in CSV or JSON format.
If you just want the full list of books as a CSV file, you can download it here. And if you want all the OCRd text, you can go straight to the public folder on CloudStor – there’s about 3.6gb of text files to explore! #dhhacks