New GLAM data to search, visualise and explore using the GLAM Workbench!
There’s lots of GLAM data out there if you know where to look! For the past few years I’ve been harvesting a list of datasets published by Australian galleries, libraries, archives, and museums through open government data portals. I’ve just updated the harvest and there’s now 463 datasets containing 1,192 files. There’s a human-readable version of the list that you can browse. If you just want the data you can download it as a CSV. Or if you’d like to search the list there’s a database version hosted on Glitch. The harvesting and processing code is available in this notebook.
The GLAM data from government portals section of the GLAM Workbench provides more information and a summary of results. For example, here’s a list of the number of data files by GLAM institution.

Most of the datasets are in CSV format, and most have a CC-BY licence.
What’s inside?
Obviously it’s great that GLAM organisations are sharing lots of open data, but what’s actually inside all of those CSV files? To help you find out, I created the GLAM CSV Explorer. Click on the blue button to run it in Binder, then just select a dataset from the dropdown list. The CSV Explorer will download the file, and examine the contents of every field to try and determine the type of data it holds – such as text, dates, or numbers. It then summarises the results and builds a series of visualisations to give you an overview of the dataset.
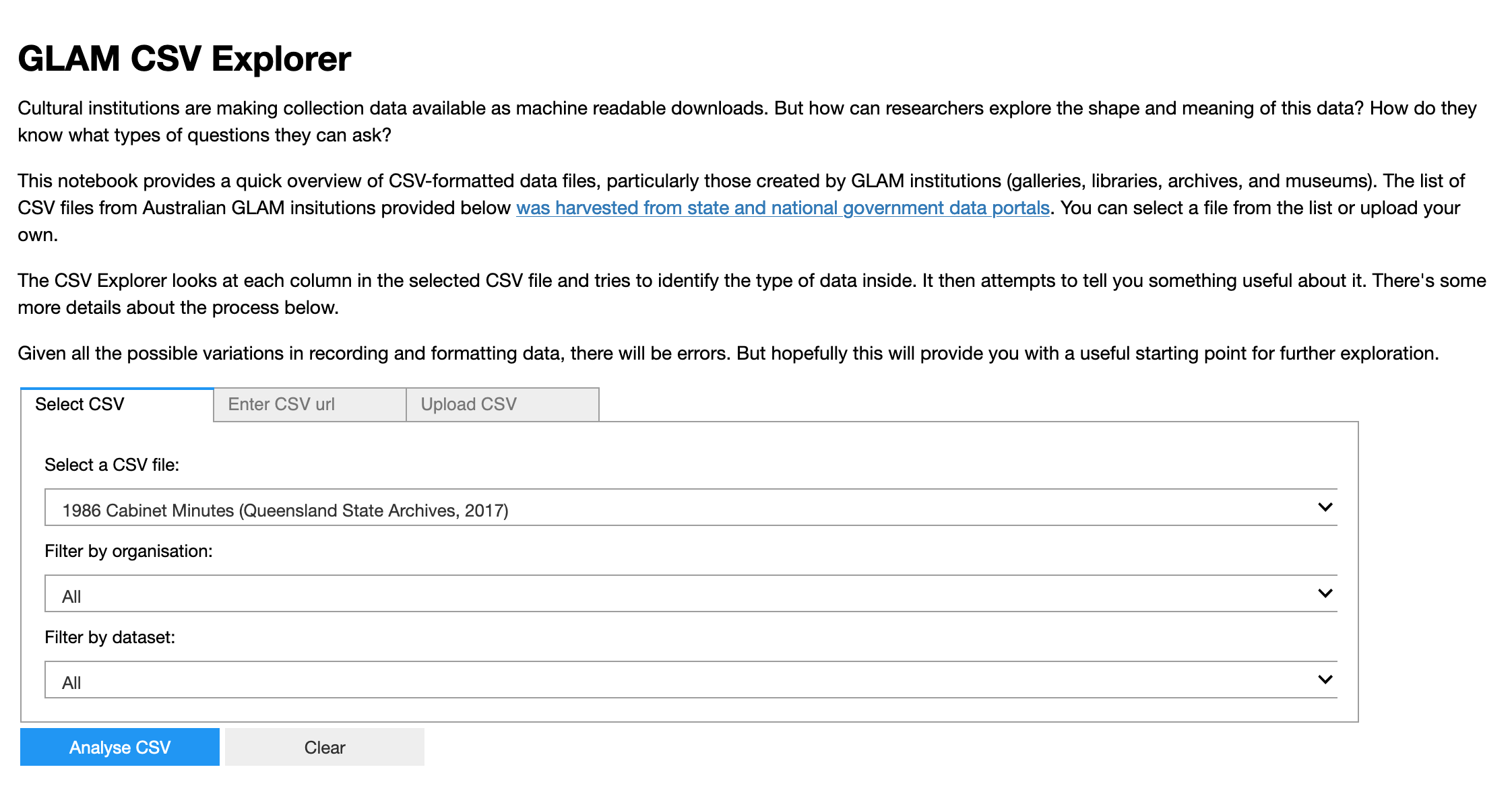
Search for names
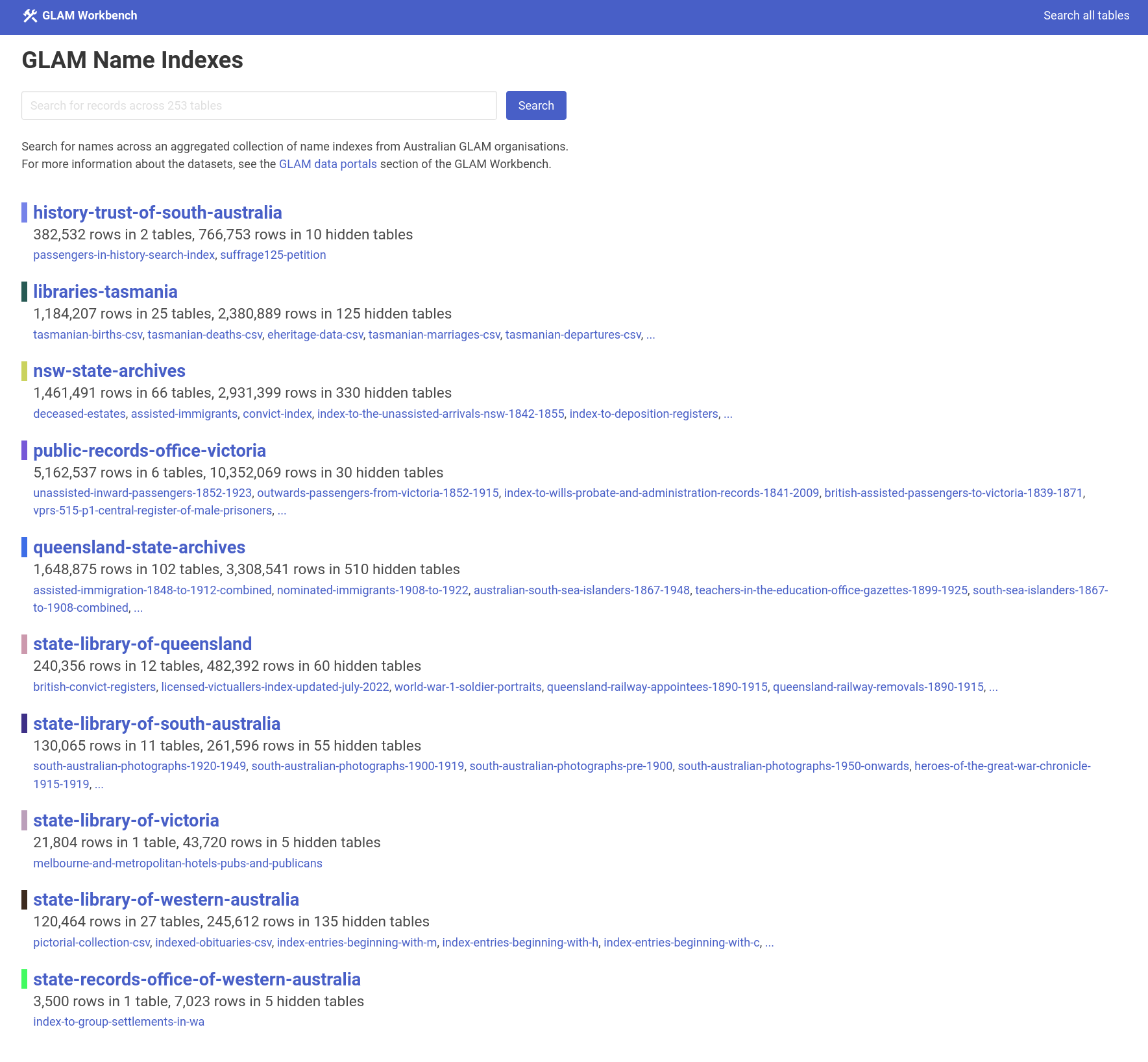
Many of the datasets are name indexes to collections of records – GLAM staff or volunteers have transcribed the names of people mentioned in records as an aid to users. For Family History Month last year I aggregated all of the name indexes and made them searchable through a single interface using Datasette. The GLAM Name Index Search has been updated as well – it searches across 10.3 million records in 253 indexes from 10 GLAM organisations. And it’s free!
And a bit of maintenance…
As well as updating the data, I also updated the code repository adding the features that I’m rolling out across the whole of the GLAM Workbench. This includes automated Docker builds saved to Quay.io, integrations with Reclaim Cloud and Zenodo, and some basic quality controls through testing and code format checks.