Making NSW Postal Directories (and other digitised directories) easier to search with the GLAM Workbench and Datasette
As part of my work on the Everyday Heritage project I’m looking at how we can make better use of digitised collections to explore the everyday experiences woven around places such as Parramatta Road in Sydney. For example, the NSW Postal Directories from 1886 to 1908 and 1909 to 1950 have been digitised by the State Library of NSW and made available through Trove. The directories list residences and businesses by name and street location. Using them we can explore changes in the use of Parramatta Road across 60 years of history. But there’s a problem. While you can browse the directories page by page, searching is clunky. Trove’s main search indexes the contents of the directories by ‘article’. Each ‘article’ can be many pages long, so it’s difficult to focus in on the matching text. Clicking through from the search results to the digitised volume lands you in another set of search results, showing all the matches in the volume. However, the internal search index works differently to the main Trove index. In particular it doesn’t seem to understand phrase or boolean searches. If you start off searching for “parramatta road” , Trove tells you there’s 50 matching articles, but if you click through to a volume you’re told there’s no results. If you remove the quotes you get every match for ‘parramatta’ or ‘road’. It’s all pretty confusing.
The idea of ‘articles’ is really not very useful for publications like the Post Office Directories where information is mostly organised by column, row or line. You want to be able to search for a name, and go directly to the line in the directory where that name is mentioned. And now you can! Using Datasette, I’ve created an interface that searches by line across all 54 volumes of the NSW Post Office Directory from 1886 to 1950 (that’s over 30 million lines of text).
Basic features
-
The full text search supports phrase, boolean, and wildcard searches. Just enter your query in the main search box to get results from all 54 volumes in a flash.
-
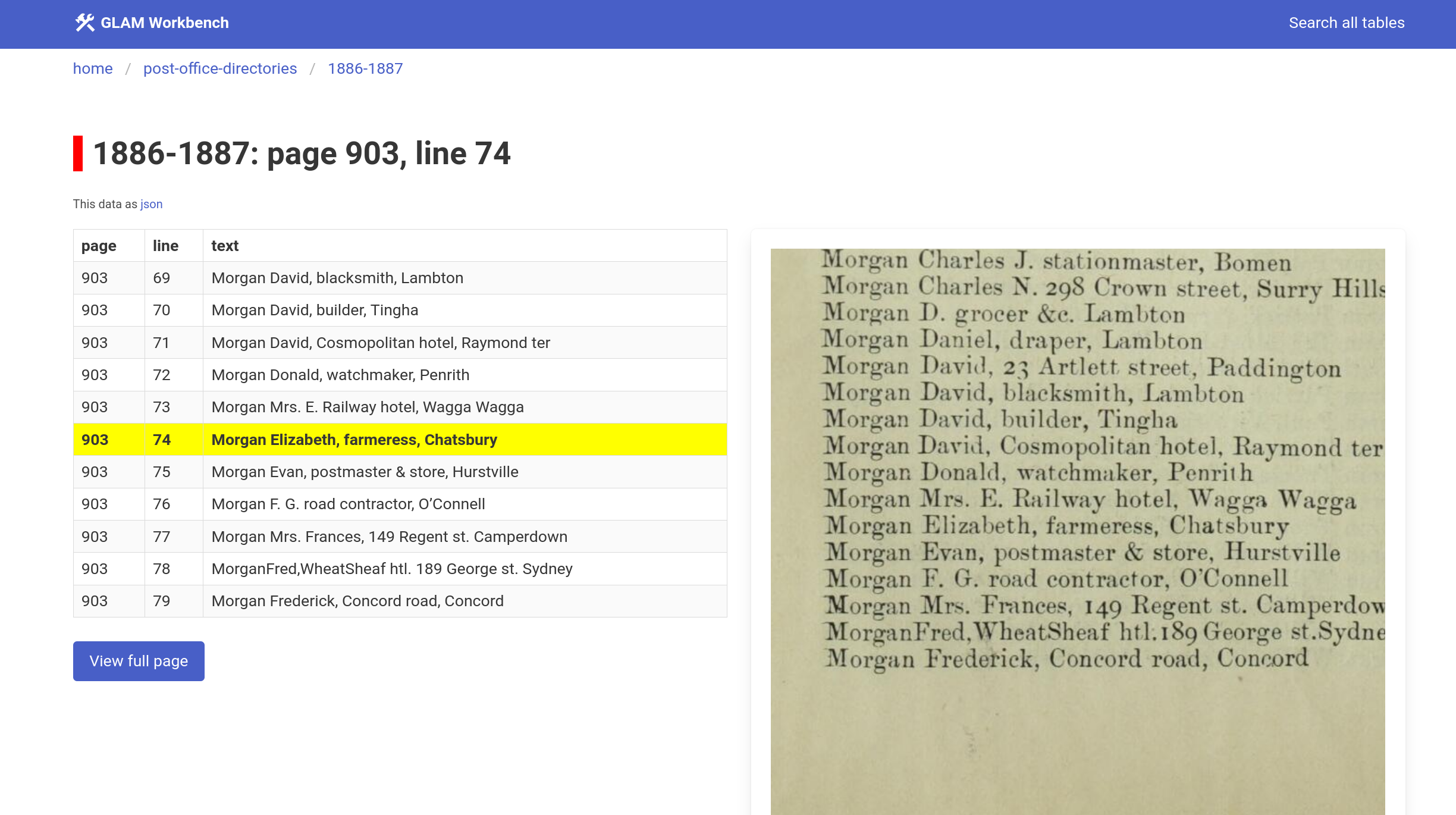
Each search result is a single line of text. Click on the link to view this line in context – it’ll show you 5 lines above and below your match, as well as a zoomable image of the digitised page from Trove.
-
For more context, you can click on View full page to see all the lines of text extracted from that page. You can then use the Next and Previous buttons to browse page by page.
-
To view the full digitised volume, just click on the View page in Trove button.
How it works
There were a few stages involved in creating this resource, but mostly I was able to reuse bits of code from the GLAM Workbench’s Trove journals and books sections, and other related projects such as the GLAM Name Index Search. Here’s a summary of the processing steps:
- I started with the two top-level entries for the NSW Postal Directories, harvesting details of the 54 volumes under them.
- For each of these 54 volumes, I downloaded the OCRd text page by page. Downloading the text by page, rather than volume, was very slow, but I thought it was important to be able to link each line of text back to its original page.
- To create links back to pages, I also needed the individual identifiers for each page. A list of page identifiers is embedded as a JSON string within each volume’s HTML, so I extracted this data and matched the page ids to the text.
- Using sqlite-utils, I created a SQLite database with a separate table for every volume. Then I processed the text by volume, page, and line – adding each line line of text and its page details as a individual record in the database.
- I then ran full text indexing across each line to make it easily searchable.
- Using Datasette and its search-all plugin, I loaded up the database and BINGO! More than 30 million lines of text across 54 digitised volumes were instantly searchable.
- To make it all public, I used Datasette’s
publishfunction to push the database to Google’s Cloudrun service.
All the code is available in the journals section of the GLAM Workbench.
Future developments
One of the most exciting things to me is that this processing pipeline can be used with any digitised publication on Trove where it would be easier to search by line rather than article. Any suggestions?