Real Face of White Australia – updated site to transcribe records from the National Archives of Australia
Back in 2017, I worked with students from my ‘Exploring Digital Heritage’ class at the University of Canberra to develop and launch a site to transcribe records from the National Archives of Australia relating to the administration of the White Australia Policy. The highlight was a weekend-long ‘transcribe-a-thon’ held in Kings Hall at Old Parliament House.

This was part of the Real Face of White Australia project – an ongoing effort by Kate Bagnall and me to increase awareness and understanding of the White Australia Policy records held by the NAA. For an introduction to the project and its origins, see our chapter ‘The people inside’, published in Seeing the Past with Computers: Experiments with Augmented Reality and Computer Vision for History, edited by Kevin Kee and Tim Compeau.
The original transcription site was built using Scribe, a community transcription platform developed by the New York Public Library and Zooniverse. Unfortunately Scribe is no longer being supported or developed, and, with the infrastructure slowly degrading, I needed to find an alternative before the whole thing fell over.
I decided to use Zooniverse’s Project Builder, which itself is implemented using their Panoptes API. The basic structure of a Project Builder project is similar to Scribe, with ‘tasks’, ‘workflows’, ‘subjects’, and ‘classifications’. The Project Builder web interface makes it easy to get started, though defining workflows for complicated transcription tasks – like extracting structured information from a form or certificate – can get a bit messy. You can also access the Panoptes API directly, which means you can code your own pipelines for uploading and downloading data from your transcription project.
The documents I uploaded to the new site have no transcriptions from the old system. Some have been digitised since the first site was created. I’m still working through the transcription data from the original site, and will be adding new records over time. At the moment, all the records come from Series ST84/1 – there’s some background information about the records on the projects ‘about’ page.
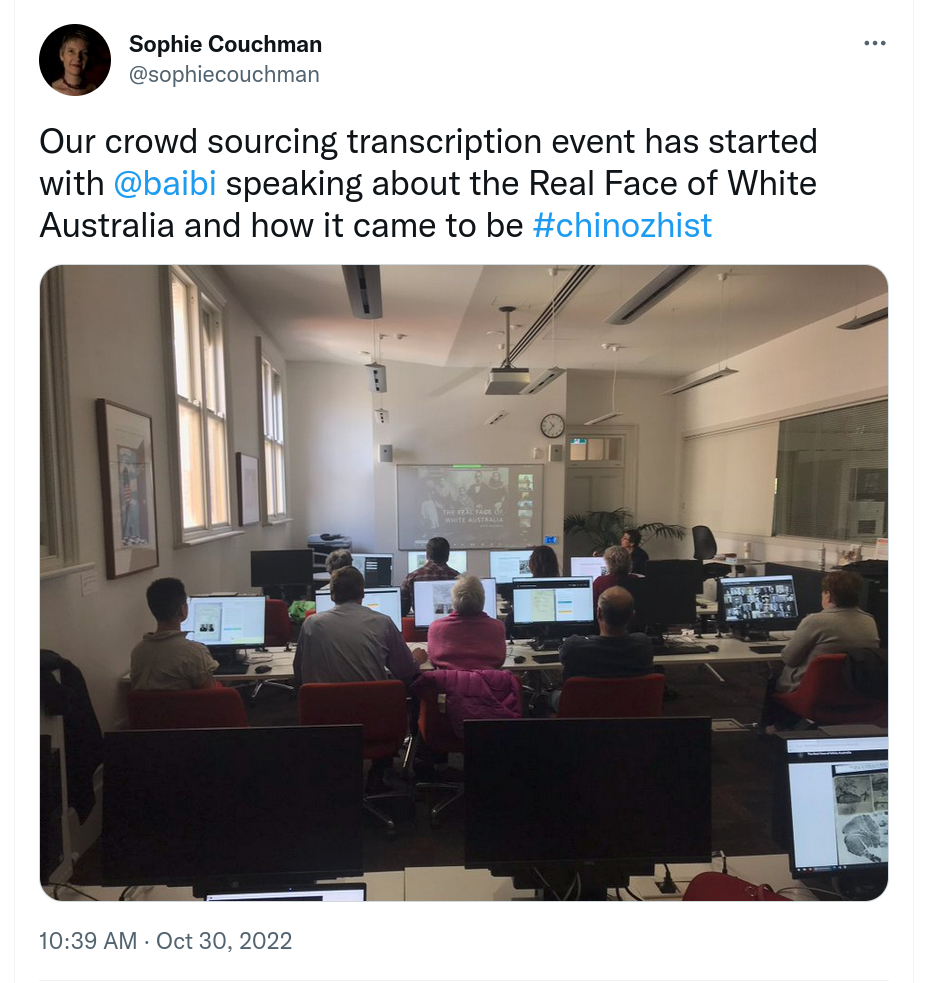
The new, Zooniverse-powered, Real Face of White Australia transcription site was launched on 30 October at a transcription event organised by CAFHOV (Chinese Australian Family Historians of Victoria). On that first day, 16 volunteers transcribed 880 documents, and they’ve kept going – the total’s now up to 6,749! If you want to help, just head along to the site and click on the Get Started button!
All the data extracted by the Real Face of White Australia project is available for further research through this GitHub repository. You can follow @invisibleaus on Twitter for twice-daily mini stories drawn from the transcribed data.