New GLAM Workbench section for working with government publications in Trove
The GLAM Workbench has a brand new section aimed at helping you find and use government publications in Trove. Most of the GLAM Workbench’s existing sections focus on a particular resource format, or are related to one of Trove’s top-level categories. This didn’t quite work for government publications, as things like Parliamentary Papers are spread across multiple categories, and can encompass a variety of formats. So I thought a new section was the best way of bringing it all together.
At the moment the Trove Government section includes two notebooks and three pre-harvested datasets.
- Harvest parliament press releases from Trove
- Harvest details of Commonwealth Parliamentary Papers digitised in Trove
- Digitised Parliamentary Papers in Trove
- Press releases relating to refugees
- Press releases relating to COVID
It took a bit longer than I was originally expecting because I also made some changes in the way I store and display information about GLAM Workbench resources. You might notice, for example, that each of the datasets lives in its own separate GitHub repository, rather than being rolled together with the notebooks into one big repository. This makes it easier to manage and share information about individual datasets, and also trims down the size of the Docker images built from the code repository.
Each of these data and code repositories have their own machine-readable metadata following the RO-Crate standard. This continues work I’ve been doing with the ARDC Community Data Lab to describe GLAM Workbench resources and outputs using RO-Crate. Having this metadata in a standard format creates new possibilities for integration and automation. I’m now using the RO-Crate files to produce different, public-facing views of the resources they describe. The README files in each repository and all the GLAM Workbench pages in the Trove Government section are automatically generated from the RO-Crate data. In the latter case, I’ve extended my MkDocs setup using macros to pull in the RO-Crate JSON files and make the data available to the page templates. Connecting all the bits up took a lot of time, but I’m pretty happy with the result and will eventually extend this approach to the rest of the GLAM Workbench.

I also fiddled a bit with the way Jupyter notebooks are presented in the GLAM Workbench. The Trove Government pages include a notebook preview – basically an HTML rendering of the notebook in an iframe. This means you can browse the content of the notebook without having to do anything extra, or go anywhere else. In other sections you can view notebook content by following links to GitHub or NBViewer, but the embedded previews seem cleaner and more useful.
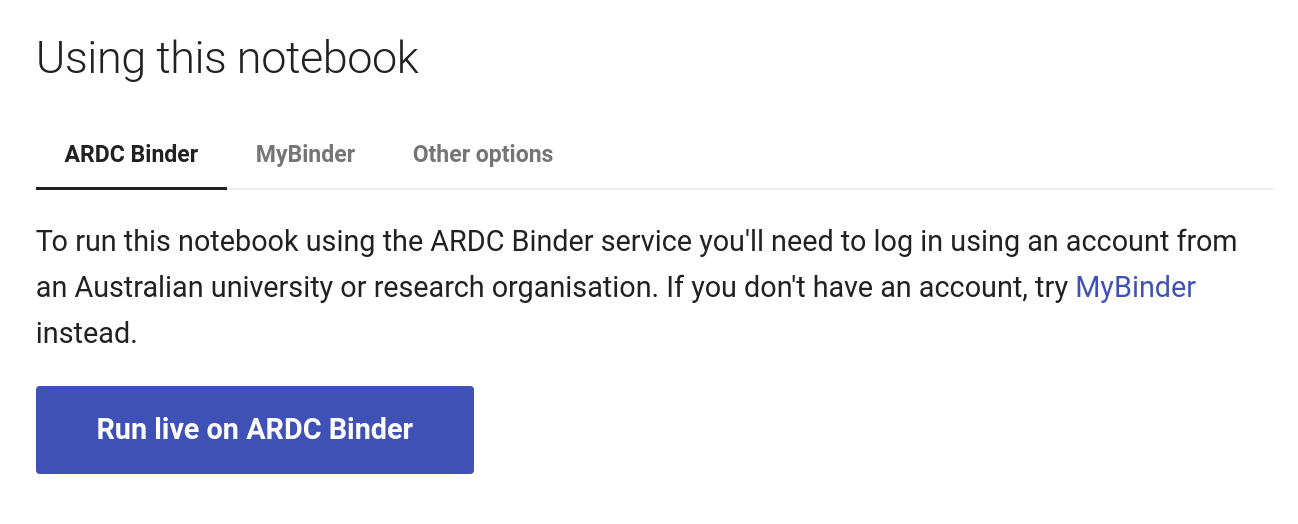
I’ve also changed the way options to run the notebook are presented. In the Trove Government section, these options are displayed as tabs beneath the preview – allowing you to choose, for example, between ARDC Binder and the public MyBinder service. In other sections I have a big blue button to launch the notebook using a specific service, with other options listed below. This new approach means I don’t have to prioritise one particular service – it’s left to the user to choose. It’s also expandable. In the future, I’m hoping to make some of the GLAM Workbench’s notebooks available using JupyterLite. As I do this, I can just add the JupyterLite option under another tab.
As with some other sections of the GLAM Workbench, the dataset pages are integrated with Datasette-Lite. If there’s a CSV file in the dataset, you’ll see a button to explore it using Datasette. For example, this link leads to a searchable database with details of 24,997 digitised Parliamentary Papers. That same dataset has also been used in the Trove Data Guide, to visualise Trove’s holdings of Parliamentary Papers. Yay for integration and reuse!