How to download all the images from a digitised collection in Trove (& learn some cool Trove tricks)
Digitised resources in Trove are sometimes grouped into collections – an album of photographs, a set of posters, a bundle of letters. I’ve just added a notebook to the GLAM Workbench that downloads all the images in a collection at the highest available resolution.
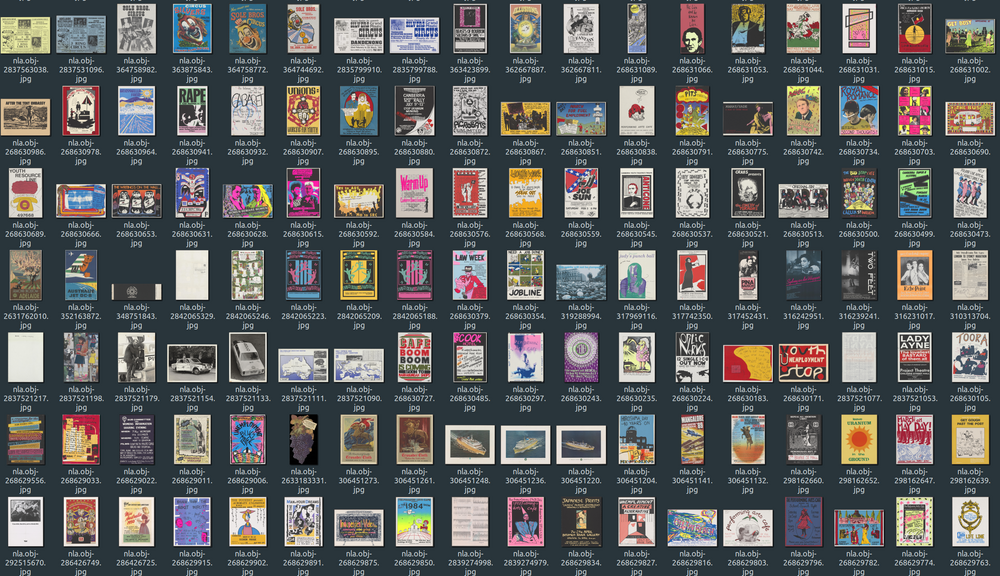
A sample of the 3,048 posters download from nla.obj-2590804313
Why is it necessary?
Trove’s digitised collection viewer includes a download option. But in most cases that seems to be limited to downloading 20 images at a time. Part of the reason for that is probably because the images are zipped up into a single file, which could get very large if 100, or 200 images were added.
Another limitation of the built-in download option is that the images are often fairly low resolution copies (many have a maximum width of 1000px). The quality of the images limits how you can use them.
For many research purposes, you’ll want a complete collection at the highest resolution possible. Trove makes that difficult. The new notebook makes it easy.
How does it work?
The Trove API is not much help. The only collections it knows about are articles in newspapers, and issues in periodicals. However, when you browse through a collection using the digitised collection viewer, a little internal API is called that delivers an HTML list of the next 20 items. By stepping through the collection page by page, you can eventually harvest details of all the items in a collection.
Once you have the nla.obj identifiers for each image, you can download a high-resolution version simply by adding /image to the url. Downloaded this way, the images generally seem to have a longest dimension equal to 5000px – a considerable improvement!
As well as downloading all the images, the notebook also generates an RO-Crate metadata file that describes the context of your harvest – when it was run, what collection you downloaded, what notebook you used, as well as the details of each image. This’ll help you in the future when you’ve forgotten where all the images came from!
Where can I learn all these Trove tricks?
This new notebook came about because I was documenting the method for harvesting collections in the Trove Data Guide. I realised that I needed to adapt my original code to work with complex collections that included multiple layers of nested sub-collections (like manuscript finding aids). Having done that, I thought it would be useful to create a working example in the GLAM Workbench.
The Trove Data Guide is being developed as part of the ARDC’s Community Lab. In it I’m trying to document as many of these problems and workarounds as I can to open Trove data to new research uses. Here, for example, is the page that discusses how to get a list of collection items, and here are some suggestions for downloading high-resolution images. One of my favourite discoveries from recent weeks was the internal API that delivers OCR layout information about book and periodical pages – find out how to save illustrations from books, visualise the layout of a periodical page, and even create some #redactionart poetry.
The content of the Trove Data Guide is changing and developing all the time. It’s all happening in the open, so feel free to explore the bleeding-edge development version or the latest published version. If there’s something you’d like to see, please post it on the GitHub ideas board.
Where is the new notebook?
The new notebook is part of the Trove images section in the GLAM Workbench. Because I was adding a new notebook, I also took the chance to update the whole repository. Changes include:
- now using Trove API v3
- now using Python 3.10
- updated Python packages
- now includes an
ro-crate-metadata.jsoncontaining machine-readable metadata describing this repository
I also updated the datasets that provide information about the application of licences and rights statements to images by Trove contributors and moved them to their own GitHub repository.