Keyword analysis of Trove newspapers with the GLAM Workbench & ATAP
There’s a new draft tutorial in the development version of the Trove Data Guide. It walks through the process of harvesting a collection of digitised newspaper articles from Trove, reshaping the harvest to create sub-collections, and then loading the data into the Keyword Analysis Tool provided by the Australian Text Analytics Platform (ATAP).
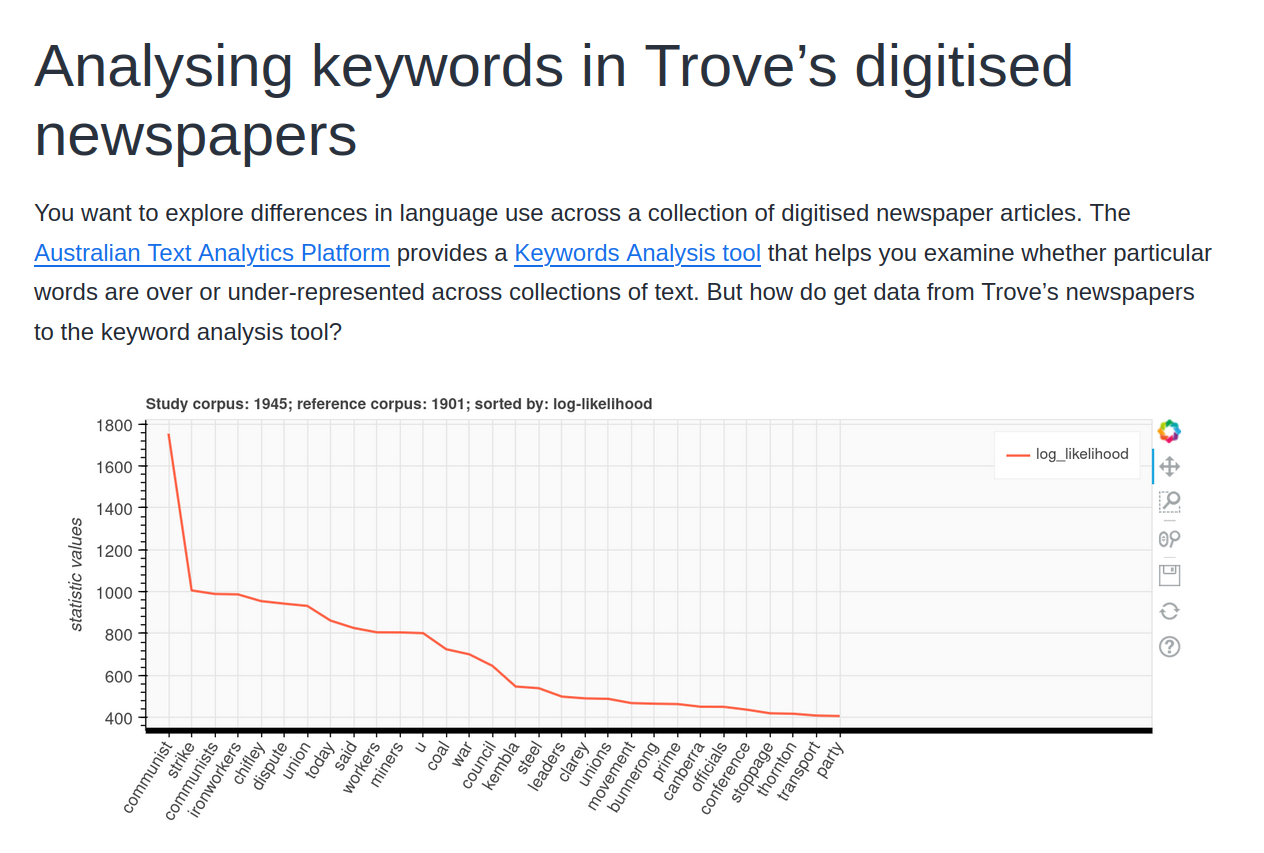
Along the way it goes into a fair bit of detail about constructing searches, using the Trove Newspaper Harvester, and thinking about your data. Much of the information on creating and reshaping datasets would apply to using the digitised newspapers with other analysis tools as well.