Share your spreadsheet as a searchable online database using Datasette-Lite
HASS researchers often compile data in spreadsheets. Sometimes they want to ‘publish’ this data online in a form that encourages others to use and explore – but how? I’ve just added a simple tool to the GLAM Workbench that helps you construct a url that will open a CSV file as a searchable database using Datasette-Lite.
What’s Datasette?
Datasette is a fantastic tool that helps you publish your data as an interactive website. There’s a few different varieties of Datasette, but Datasette-Lite is probably the easiest, as you don’t need to install any software. Datasette-Lite runs completely within your web browser, converting your data into into a searchable database on demand.
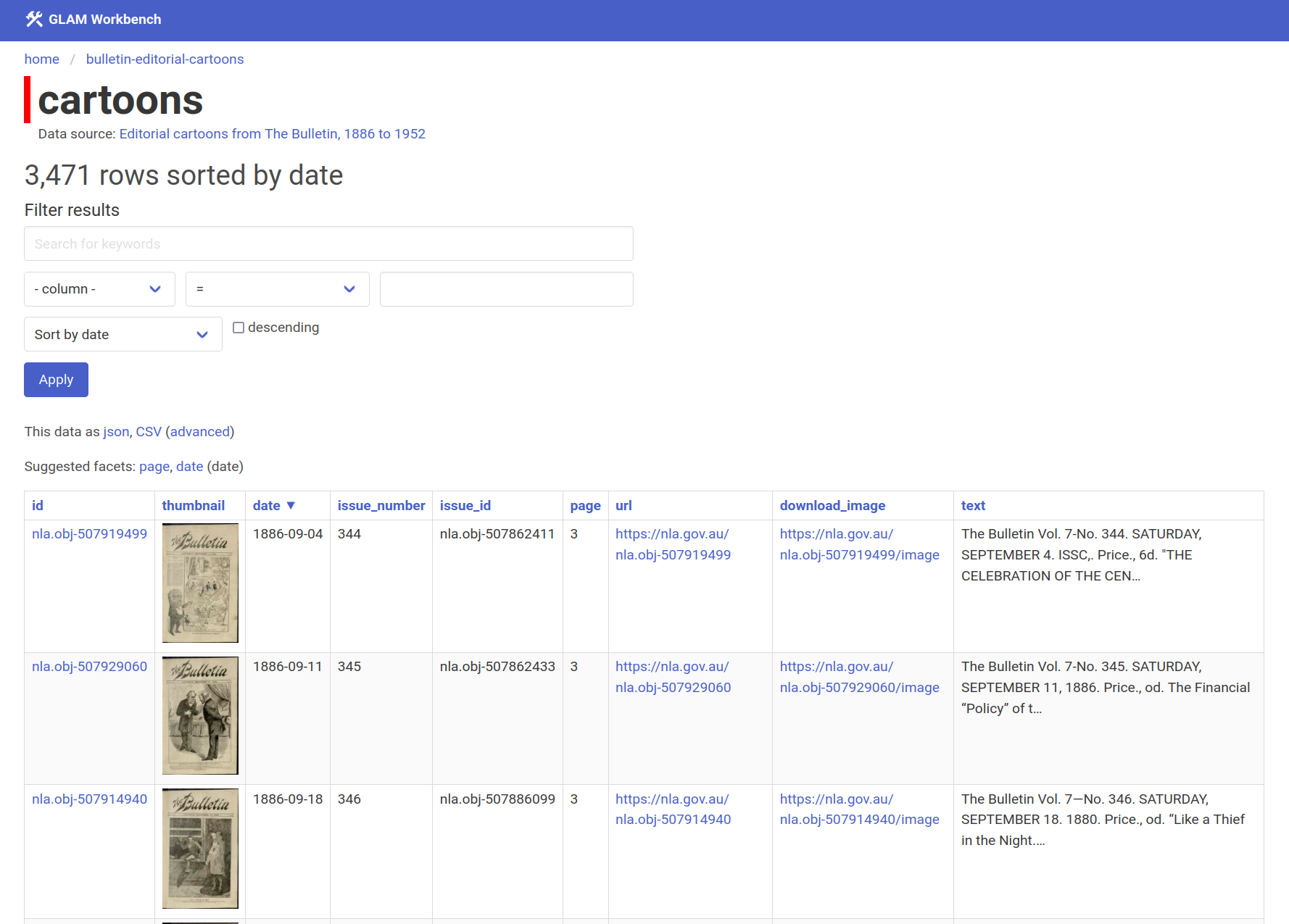
I’m using Datasette-Lite throughout the GLAM Workbench. For example, try clicking the Explore in Datasette buttons on any of these pages:
What do the buttons do? They’re simply links to my customised version of Datasette-Lite in GitHub. This links retrieve the Datasette-Lite web page, which instructs your browser to install the necessary software and run the Datasette application. Parameters in the url point Datasette to a specific data file in another GitHub repository. Datasette loads the data file and builds the interface.
Create your own Datasette-Lite links
All you need to publish your spreadsheet using Datasette-Lite is:
- your spreadsheet saved in CSV format in a public GitHub repository
- a url that points Datasette-Lite to the CSV file
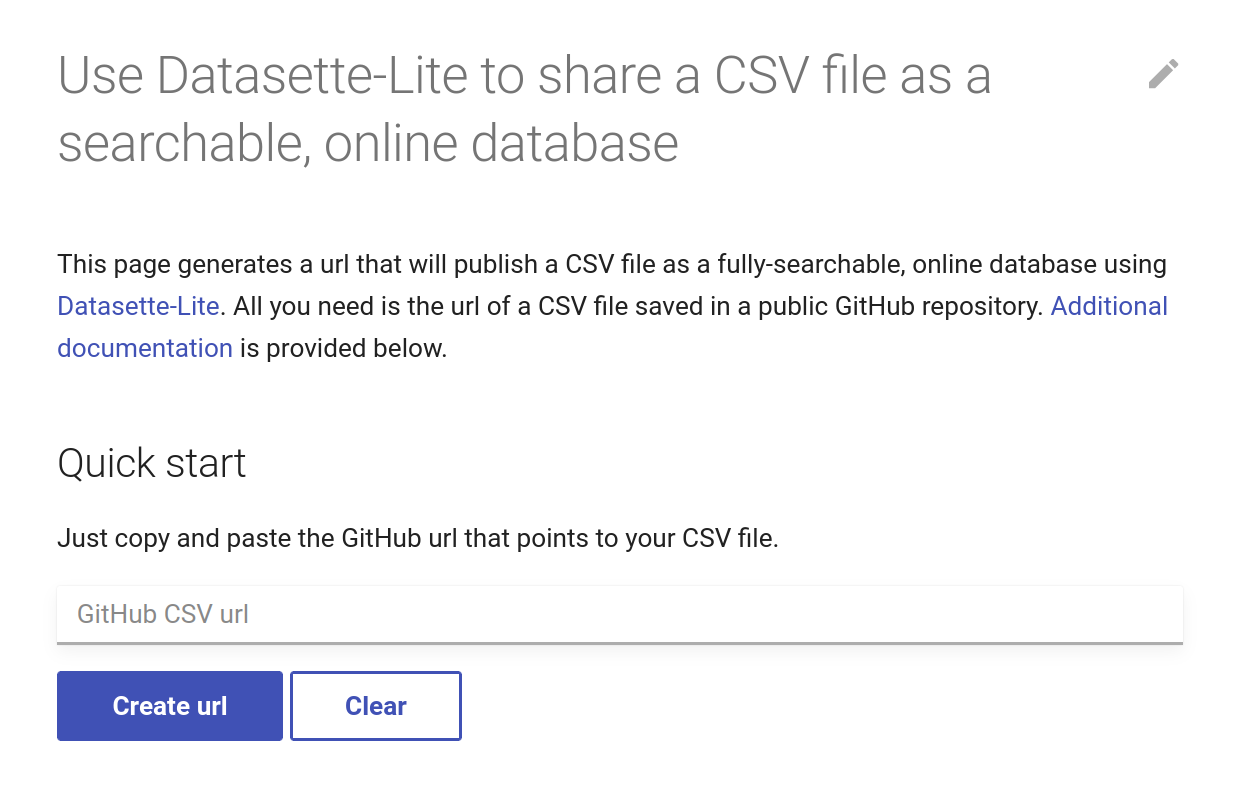
To make this as easy as possible, I’ve created a tool that generates the necessary url. It’s just a simple web form – paste in the link to your CSV file, add some optional parameters, click the button, and the url to open your CSV file in Datasette-Lite will be displayed. Click on the url to open Datasette, or copy it to share your data with others.
The optional parameters let you index full text columns for easy keyword searching, hide unwanted columns, and add links to more information about your dataset. They’re described more fully in the documentation.
Limitations and alternatives
This tool makes it easy to share single CSV files as searchable databases. But if your CSV has millions of rows it’ll probably make your web browser unhappy if you try and load it in Datasette-Lite. Instead you can make use of Datasette’s ‘publish’ option to push your data to a dedicated Datasette instance running in the cloud. You can also customise your instance by changing the theme or using canned queries.
For example, the GLAM Name Index Search contains more than 10 millions rows of data from multiple datasets, all aggregated through a single search interface. The Tasmanian Post Office Directories provides full-text search across 48 digitised volumes and has a heavily customised interface that displays page images as well as the OCRd content. Both of these Datasette instances are hosted on Google Cloudrun.
Similarly, the method described here is designed to work with single CSV files. If you have multiple, interconnected tables you’ll probably want to generate your own SQLite database to use with Datasette. There’s an example of how you can do this in the Enrich the list of periodicals from the Trove API notebook in the GLAM Workbench.