A big milestone, Trove contributor data, and the coming of API v3 – recent GLAM Workbench updates
There have been quite a few GLAM Workbench updates over the last month, here’s some notes. (See February’s update for more recent changes…)
General developments
- After many months of work, all thirteen Trove repositories within the GLAM Workbench have been updated to include standard configurations, integrations, and basic tests. This will make ongoing development and maintenance much easier. Docker images of every repository are now built automatically whenever the code changes. These images can be used across multiple computing environments, including cloud services such as Binder, Nectar, and Reclaim Cloud, as well on a local computer. This means users have more options for running the notebooks within a consistent, pre-configured, and tested environment.
- With all the Trove repositories now Docker-ised, I worked with the Nectar Cloud team to update the GLAM Workbench app. Now when you install the app, you can select from any of the Trove repositories (excluding API intro and Random items), as well as the NAA RecordSearch, Web Archives, Digital NZ and Te Papa repositories.
- Datasette Lite integration! Datasette Lite turns CSV and JSON files into fully searchable databases running within your browser (no server required). I spent some time creating a customised version of Datasette Lite for the GLAM Workbench. Now all I can just point the urls for CSV datasets to my Datasette Lite repository to open them up for quick exploration – like this! I’ve started adding Explore in Datasette buttons to dataset pages in the GLAM Workbench. Some examples are mentioned below.
New sections
Trove contributors
Trove aggregates metadata from thousands of organisations and projects around Australia. Data about contributors is available from the /contributor endpoint of the Trove API. This section includes examples of harvesting and exploring this data.
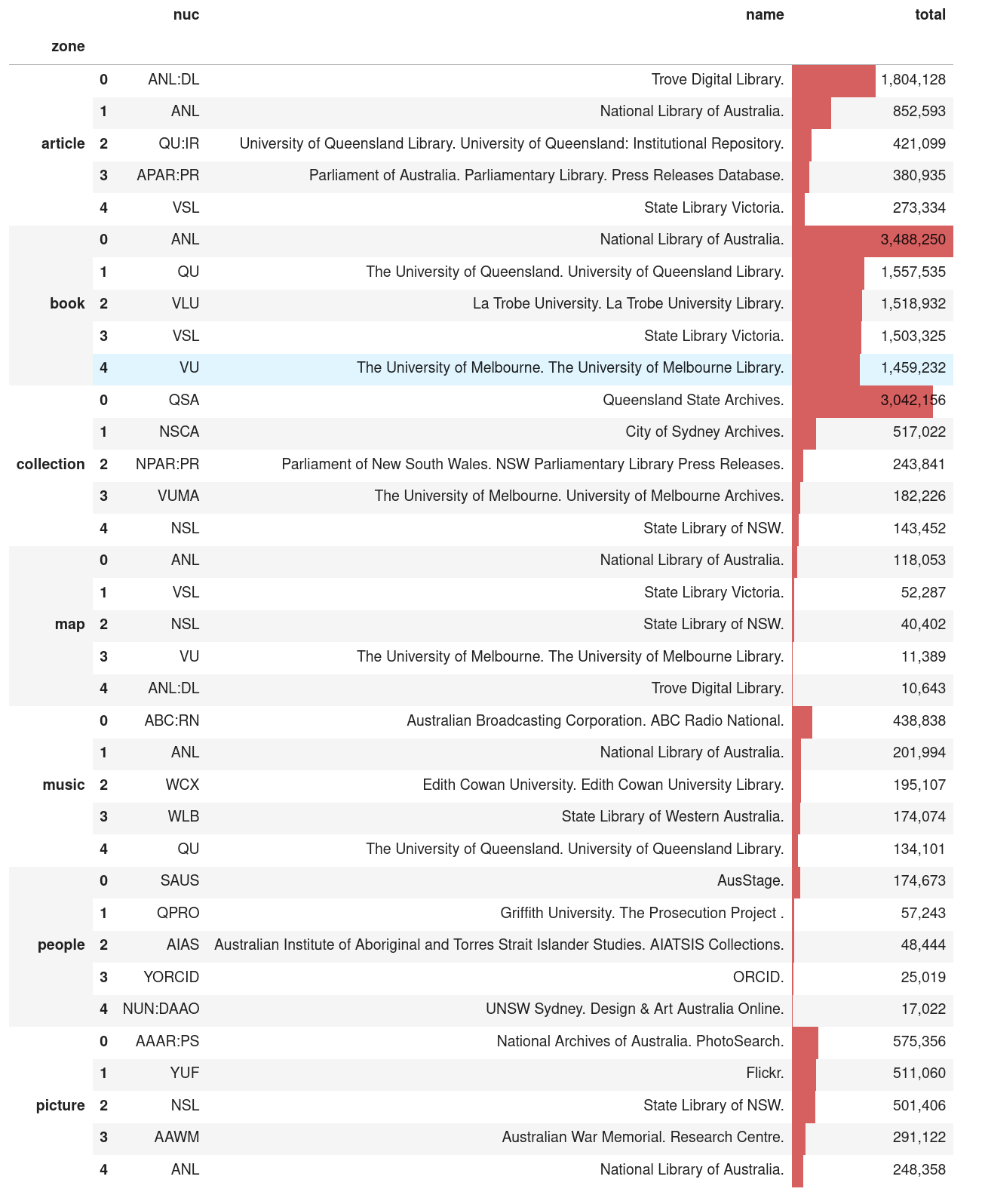
- Notebooks: One notebook converts the nested data available from the
/contributorendpoint into a single flat list of contributors. Another uses this list to to find out the number of records contributed by each organisation, aggregated by zone and format. - Datasets: Three datasets, generated by the code in the notebooks above, are being updated weekly – a list of organisations contributing metadata to Trove, a count of records by contributor and zone, and a count of records by contributor, zone, and format. You can explore them using Datasette Lite.
Trove API v3
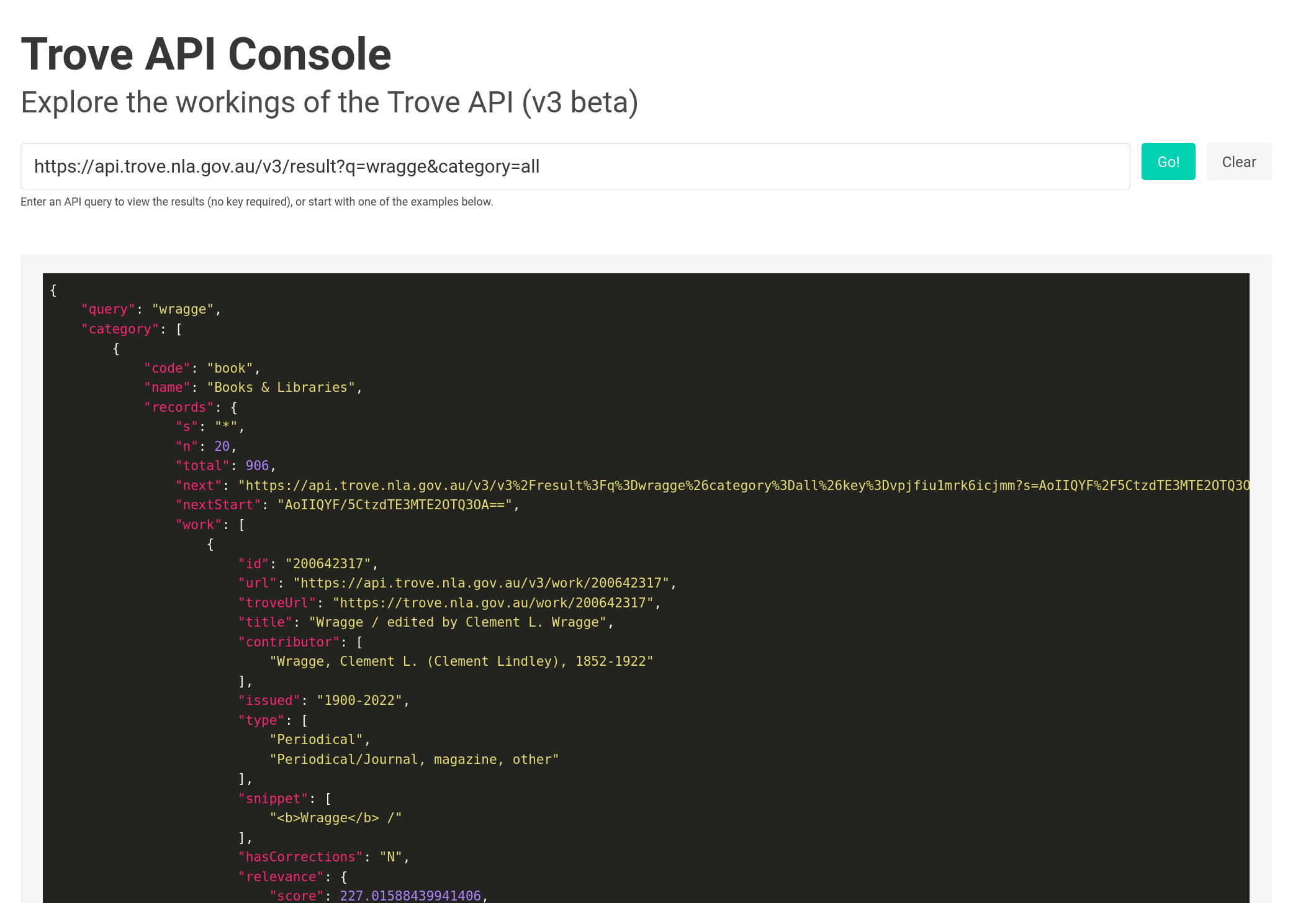
This is a temporary section of the the GLAM Workbench created to bring together information and examples relating to version 3 beta of the Trove API. It will probably disappear once the new version is officially released and I reorganise the Trove sections of the GLAM Workbench accordingly. It currently includes:
- A link to the new v3 beta section of the Trove API Console
- A summary of breaking changes in the new version – these are the things you’ll need to change in your code before v2 of the API is switched off in early 2024.
Over the coming months I’ll be adding updated notebooks and examples from other Trove sections.
Updated sections
Trove newspaper & gazette harvester
- New notebook! When I overhauled the trove-newspaper-harvester Python package last year, I made it possible to use the harvester as a library as well as a command line tool. This means you can integrate the harvester into your own tools or workflows. This new notebook, Harvesting articles that mention “Anzac Day” on Anzac Day, gives an example of a complex search query where it might be easier to use the harvester as a library – in this case, finding newspaper articles with particular keywords, published on a particular day, over a span of years!
Trove unpublished works (diaries, letters, and archives)
-
Repository upgraded: Python packages updated, configuration files standardised, basic tests added, automated Docker builds configured, integrations with Zenodo and Reclaim Cloud added.
-
New notebooks! I’ve added a series of notebooks related to finding, using, & analysing the NLA’s digitised manuscript finding aids (which are somewhat submerged beneath other content). One notebook, finds the finding aids, another one gathers some summary information about all 2,337 finding aids, and a third helps you reconstruct the hierarchy from the HTML of a single finding aid & saves the content as JSON.
-
New datasets! I used the new finding aids notebooks to generate a couple of datasets. One is just a list of Trove urls pointing to finding aids. The other dataset provides some summary information about each finding aid – this includes the number of items described, digitised, and searchable. You can explore the summary data using Datasette Lite.
Trove music & sound
- Repository upgraded: Python packages updated, configuration files standardised, basic tests added, automated Docker builds configured, integrations with Zenodo and Reclaim Cloud added.
- Updated harvest of ABC Radio National program metadata: there’s now 421,277 records from about 163 programs, though there doesn’t seem to have been any additions since early 2022.
Random items from Trove
This section documents some ways of retrieving random-ish works and newspaper articles from Trove.
- Repository upgraded: Python packages updated, configuration files standardised, basic tests added, automated Docker builds configured, integrations with Zenodo and Reclaim Cloud added.
Related developments
I’ve also created a couple of new ‘git scrapers’ to capture information about Trove. These are just bits of code that run on a schedule using GitHub actions and save their results into a GitHub repository. Along with the Trove Newspaper Data Dashboard and other historical datasets, these help researchers understand how the contents of Trove changes over time.
- trove-zone-totals: saves data about the contents of Trove’s zones (this will need to be changed to categories with the release of v3 of the Trove API)
- trove-contributor-totals: saves details of organisations and projects that contribute metadata to Trove