Exploring Trove’s digitised periodicals
While Trove’s digitised newspapers get all the attention, there are many other digitised periodicals to explore. But it’s not easy to find them from the Trove web interface – unlike the newspapers, there’s no list of digitised titles. So to help researchers find and use Trove’s digitised periodicals, I’ve created a searchable database using Datasette-Lite. Try it out!
Search for the titles of digitised periodicals.
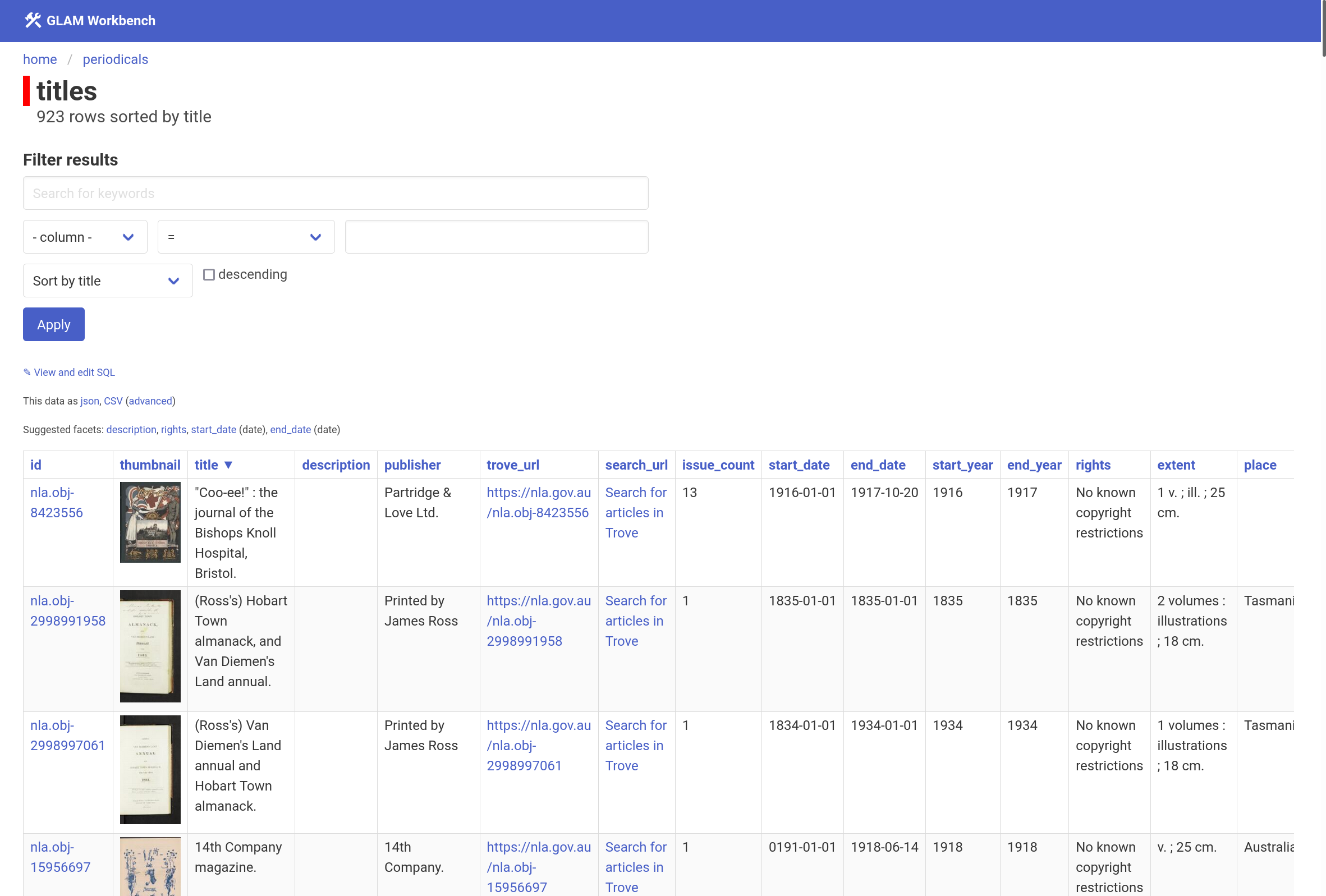
View the details of an individual title (note the link to available issues at the bottom.
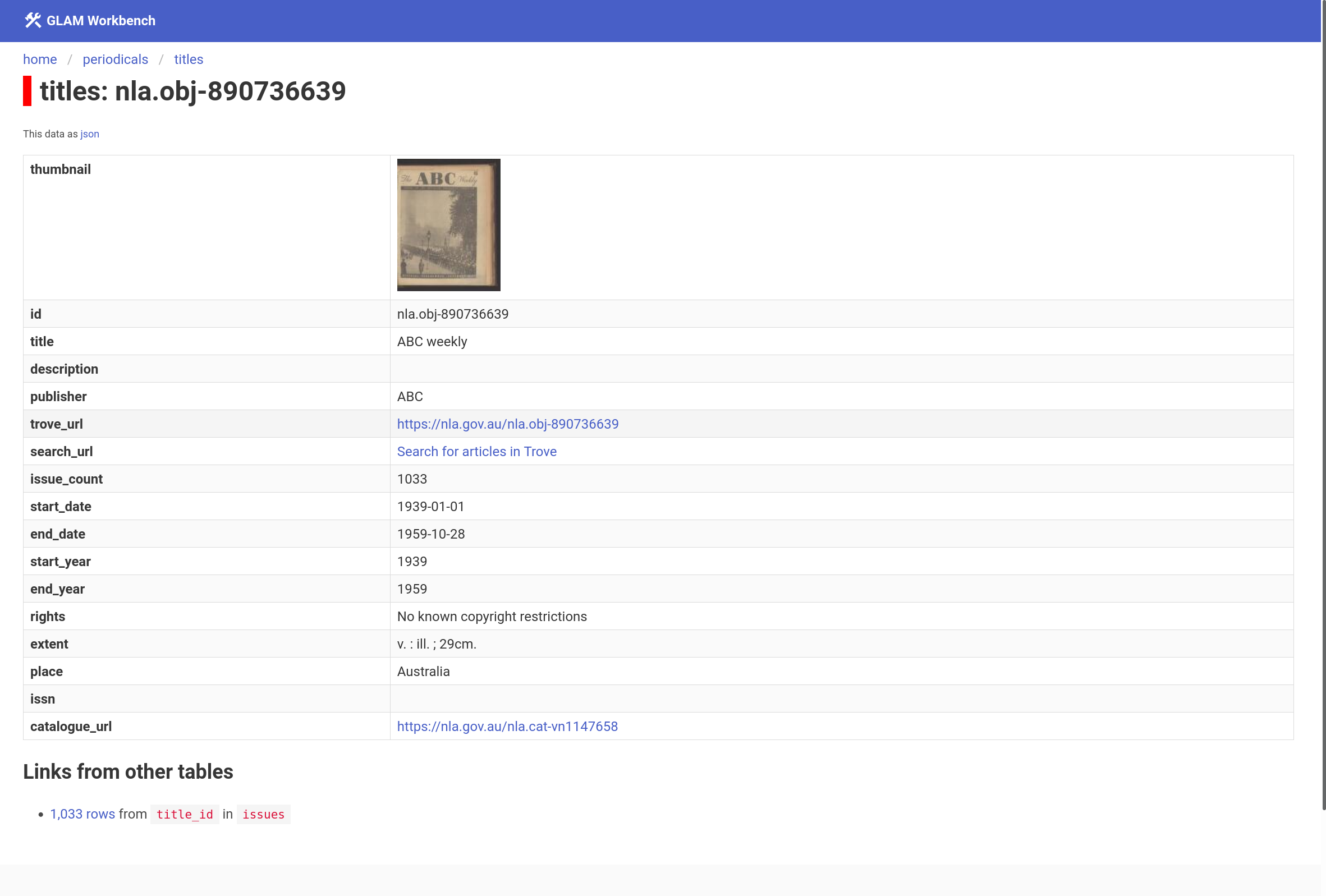
Browse a list of available issues.
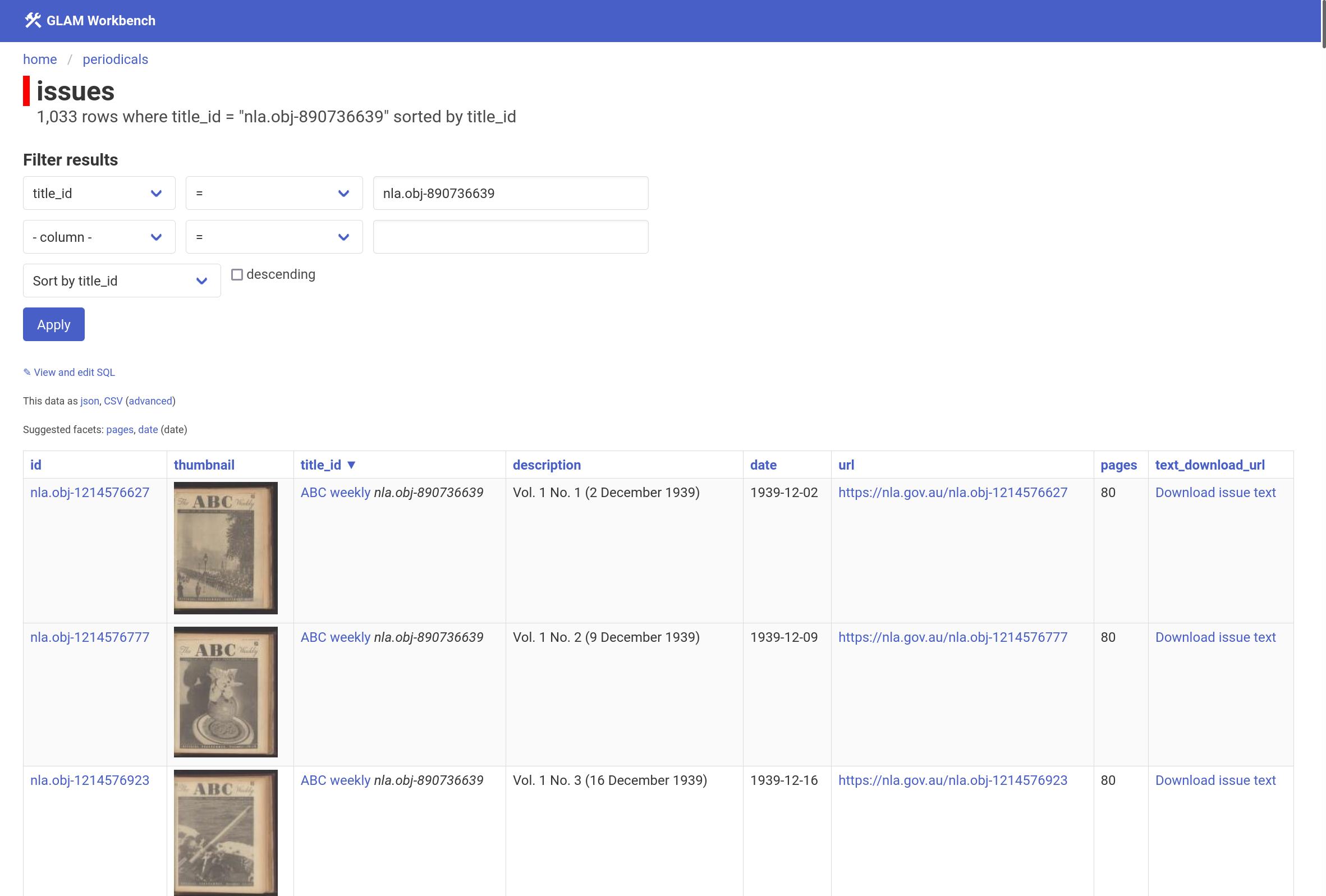
The database currently contains details of 923 different titles, and over 37,000 individual issues. You can search for titles by keyword, then click through to view a full list of issues from a periodical. As well as basic descriptive metadata and links back to Trove, there’s a couple of other handy inclusions:
- Titles include a ‘Search for articles in Trove’ link that opens up the Trove interface and pre-populates the search box with the title’s identifier. By adding some keywords you can search for articles within the publication.
- Issues include a
text_download_urllink that downloads all the OCRd text from the issue.
Regular viewers might be thinking – wasn’t there already something like this? Yes indeed, for several years I’ve been maintaining the Trove Titles app, which provides a similar list. I’ve also provided harvests of OCRd text. So why the new database? First of all, I’ve harvested the data in a different way – making use of the new /magazine/titles API endpoint. This had several problems (see below), but I’m hoping that in the long term it will make updates easier.
Second, I’m exploring ways to make these sorts of resources available in a more sustainable way. The current Trove Titles app runs on the Heroku platform and there are costs associated with the app and the databases it uses. It just seems a bit silly for a relatively small amount of data. Datasette-Lite takes a very different approach – there’s no constantly running server, just a static site pointing at a dataset. All the magic happens within your browser!
I’ve written previously about how I’ve been customising Datasette-Lite for use within the GLAM Workbench, but I had to handle the periodicals data a bit differently. Because there’s a foreign key relationship between the titles and the issues (each issue is linked back to a title), I loaded the harvested data into a SQLite database (using sqlite-utils), defined the foreign key, and built a fulltext index on the periodical titles. Then I just saved the whole SQLite database to a GitHub repository and pointed Datasette-Lite at it.
I had to modify the GLAM Workbench template a bit to insert links back to the title when you view an individual issue. This happens automatically when you view a list of results, but not when you view an individual item. First I used the install parameter to tell Datasette-Lite to install the datasette-template-sql plugin. This plugin lets you run SQL queries within a template. Then I could run a query to see if there was a foreign key associated with the current item:
{% set fk = sql("SELECT * FROM pragma_foreign_key_list(?)", [table]) %}
If there is a foreign key, I run another query to get the title of the linked title:
{% if fk %}
{% set flinks = sql("select title, " + fk.0.to + " from " + fk.0.table + " where id = ?", [display_rows.0[fk.0.from]]) %}
{% set ftitle = flinks.0.title %}
{% endif %}
Then when rendering the column containing the linked value I can insert the title and a link:
{% if fk and cell.column == fk.0.from %}
<a href="/{{database}}/{{fk.0.table}}/{{cell.value}}">{{ftitle}}</a> <em>{{cell.value}}</em>
{% else %}
{{ row.display(cell.column) }}
{% endif %}
It seems to work ok, and doesn’t cause problems on databases where there’s no foreign keys.
I’m also using the datasette-json-html plugin to render the thumbnails. I’m also using the metadata parameter to point Datasette-Lite at a custom metadata file – this was primarily to define a custom sort order for the tables.
The data
I’ll write up more about the data and the harvesting process in coming weeks. There’ll also be a new section in the Trove Data Guide and some updated notebooks in the journals section of the GLAM Workbench. But a few notes about the /magazine/titles API endpoint:
- there are a few hundred duplicate records – I’ve removed these from the dataset
- the API doesn’t provide full information about issues, in particular undated issues are not returned – I’ve tried to fill these gaps
- the data includes a thousand or more Parliamentary Papers – I’ve harvested these separately and thought it was best to exclude them from this dataset
- some titles are actually nested collections, so the ‘issues’ are actually another level of title, while alternatively some titles are actually issues – I’ve tried to sort as much of this out as I can, but it gets confusing!
So I’m not confident that I’ve got everything, but I think it’s a useful start. I’ve reported the API problems to Trove but haven’t heard anything back yet.