Customising Datasette-Lite to explore datasets in the GLAM Workbench
As well as tools and code, the GLAM Workbench includes a number of pre-harvested datasets for researchers to play with. But just including a link to a CSV file in GitHub or Zenodo isn’t very useful – it doesn’t help researchers understand what’s in the dataset, and why it might be useful. That’s why I’ve also started including links that open the CSV files in Datasette-Lite, enabling the contents to be searched, filtered, and faceted. Just look for the Explore in Datasette buttons!
Datasette is an excellent tool for sharing and exploring data. I’ve used it in a number of projects such as the GLAM Name Index Search and the Tasmanian Post Office Directories. Datasette-Lite is a version of Datasette that runs completely in the user’s web browser – no need for separate servers! All you do is point a Datasette-Lite Github repository at a publicly available CSV file, and it builds a searchable database in your browser. So instead of having to configure and maintain a series of servers running Datasette, I just have one static GitHub repository that only springs into action when needed.
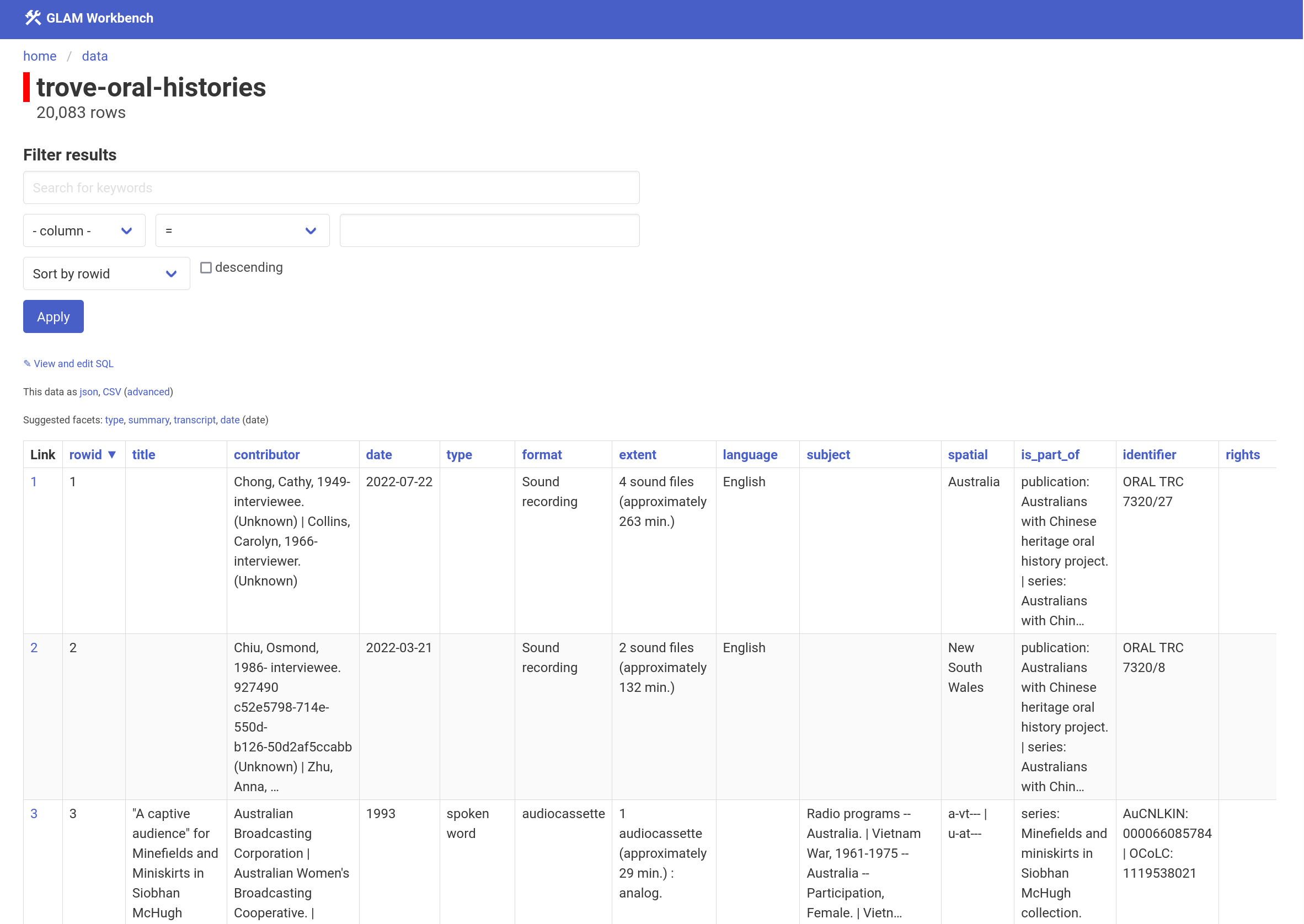
For example, click this link to explore metadata describing oral history collections in Trove using Datasette-Lite.
I’ve made a few changes to the standard Datasette-Lite application for use with the GLAM Workbench. These are all included in the GLAM Workbench’s Datasette-Lite fork and described below.
Custom theme
I’d already created a custom Datasette theme for use in other projects. The question was how do I get it to work with Datasette-Lite? Just putting a templates folder in the repository wasn’t enough, as the virtual environment created within the browser doesn’t have direct access to all the files. I eventually figured out that I could zip up the templates folder, fetch the zip file using Javascript, and then unzip the folder into the browser’s virtual environment. This is the code in webworker.js that does all that:
let templateResponse = await fetch("templates.zip");
let templateBinary = await templateResponse.arrayBuffer();
pyodide.unpackArchive(templateBinary, "zip");
Then it’s just a matter of changing the Datasette initialisation to point to the templates directory:
ds = Datasette(
names,
settings={
"num_sql_threads": 0,
"truncate_cells_html": 100 # truncate cells
},
metadata=metadata,
template_dir="templates", # point to custom templates directory
plugins_dir="plugins", # point to custom plugins directory
memory=${settings.memory ? 'True' : 'False'}
)
As you can see, I’ve also added the "truncate_cells_html": 100 setting to truncate the contents of cells in the table view.
Custom plugins
Sometimes fields can contain multiple urls. While Datasette will make single urls clickable, multiple urls are just left as plain text. The datasette-multiline-links plugin fixes this for urls separated by line breaks, but I generally separate multiple values in CSV fields using the | character. It wasn’t hard to modify the plugin, but again it wasn’t clear how to make the modified plugin work with Datasette-Lite. You can use the install parameter to load plugins, but the plugins have to either be published in PyPI or available in GitHub as a Python wheel. That all seemed like overkill for my tiny plugin modification, but then I realised that I could use the same method as I was using for the custom template – zip, fetch, unzip, then point Datasette to the new plugins directory.
It also took me a while to figure out how to get the plugin to work nicely with the truncate_cells_html setting. Unless a cell-formatting plugin returns None, other cell format operations, such as truncation, aren’t applied. So I had to make sure that the plugin returned None if there were no urls in a cell.
Custom metadata
You can use the metadata parameter in Datasette-Lite to point to a metadata file in either JSON or YAML. I’ve added a custom metadata.json file to the GLAM Workbench repository, and adjusted the webworker.js code to load it by default.
Full text indexing
One really cool things about Datasette is the ability to run full text searches across specified columns. If Datasette detects a full text index, it automatically adds a keyword search box.
There wasn’t a way of adding full text indexes to CSV datasets in Datasette-Lite, so I added a new fts url parameter and used the value in webworker.js to modify the database using SQLite-utils.
fts_cols = ${JSON.stringify(settings.ftsCols || "")}
try:
db[bit].enable_fts(fts_cols.split(",")) # add full text indexes to columns
except sqlite3.OperationalError:
print("Column not found")
pass
For example, adding fts=title to a Datasette-Lite url will automatically add a full text index to the title column. You can also index multiple columns – just separate the column names with commas.
This url opens a CSV dataset with oral history metadata harvested from Trove and indexes the title and contributor columns: https://glam-workbench.net/datasette-lite/?csv=https://github.com/GLAM-Workbench/trove-oral-histories-data/blob/main/trove-oral-histories.csv&fts=title,contributor
Datasette converts your CSV file to a SQLite database, and SQLite supports a number of advanced search options. These options aren’t enabled by default in Datasette – you need to set searchmode to raw in the table metadata. To enable advanced searches, I’ve added a line in webworker.js to modify the default metadata:
metadata["databases"]["data"]["tables"][bit] = {"searchmode": "raw"}
Drop unwanted columns
Not all the columns in pre-harvested datasets are useful or interesting. To remove selected columns from Datasette-Lite, I added a drop url parameter. Once again, you can submit multiple values separated by commas.
In webworker.js the drop values are used with the SQLite-utils transform() function to remove the columns from the database.
drop_cols = ${JSON.stringify(settings.dropCols || "")}
db[bit].transform(drop=set(drop_cols.split(",")))
This url opens a CSV dataset with oral history metadata harvested from Trove and drops the publisher and work_type columns: https://glam-workbench.net/datasette-lite/?csv=https://github.com/GLAM-Workbench/trove-oral-histories-data/blob/main/trove-oral-histories.csv&drop=publisher,work_type