More tools and data for working with Trove's digitised periodicals
The Trove Periodicals section of the GLAM Workbench has been updated! Some changes were necessary to make use of version 3 of the Trove API, but I’ve also taken the chance to reorganise things a bit – starting with the name. This section used to be called ‘Trove journals’, reflecting the naming of Trove’s ‘Journals’ zone. But zones have gone, and periodicals are now spread across multiple categories, so I thought a name change was necessary to better reflect the type of content being examined.
What periodicals have been digitised?
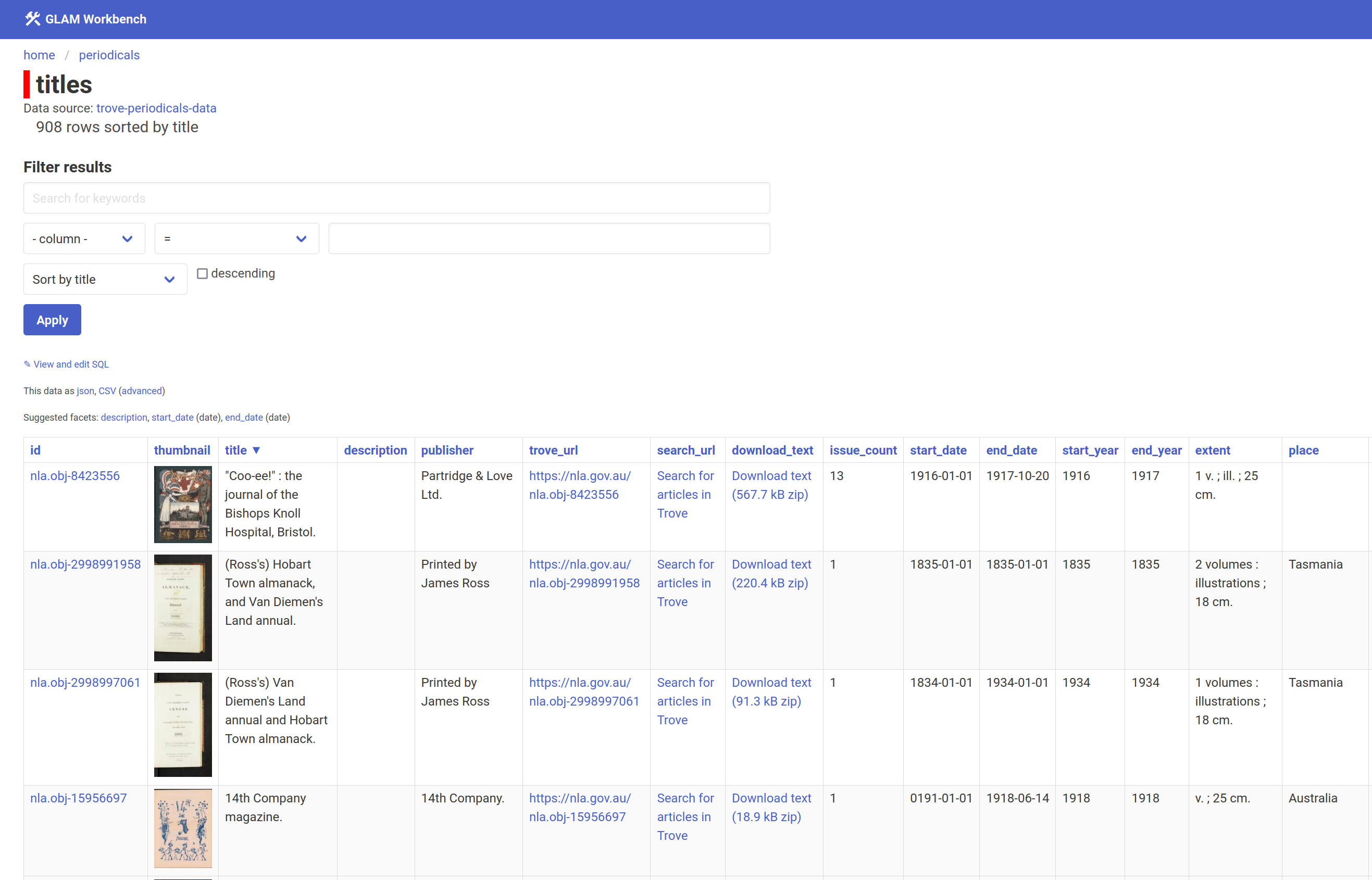
It’s surprising difficult to find out what periodicals have actually been digitised in Trove. There’s no straightforward list of titles as there is in the newspapers category. Over the years I’ve created a variety of lists and tools to try and overcome this. I’m now trying to consolidate these efforts into a single dataset which you can explore using Datasette-Lite. I’ve made a few improvements to this in recent weeks, in particular, title records now include a link to download all the OCRd text from periodical.
New notebooks
The notebook pages in the GLAM Workbench now include previews of the notebook’s content. There are a number of new notebooks:
-
Get details of periodicals from the
/magazine/titlesAPI endpoint – shows how you can get a list of titles from version 3 of the Trove API and explores some of the problems with the data -
Enrich the list of periodicals from the Trove API – shows how to work around some of the problems with the titles data, adds some extra metadata, and generates the database described above
-
Harvest illustrations from periodicals – extract illustrations for periodical pages, issues, articles and searches using a OCR layout data
If you’d like an example of the sorts of illustrations you can extract from the digitised periodicals, here’s a collection of photos found by searching for periodical articles with cat or kitten in their titles.

Updated and reorganised datasets
I’ve moved all the datasets out of the main GitHub repository into their own separate repositories. Some large collections that were previously stored on the sadly-deceased Cloudstor service are now sitting in an Amazon s3 bucket. These include:
-
Details of digitised periodicals from the
/magazine/titlesAPI endpoint – these are the datasets created by harvesting and enriching titles and issues data from the Trove API -
CSV formatted list of journals available from Trove in digital form – this is an update of an older dataset of titles created by searching for digitised works with the format
Periodical -
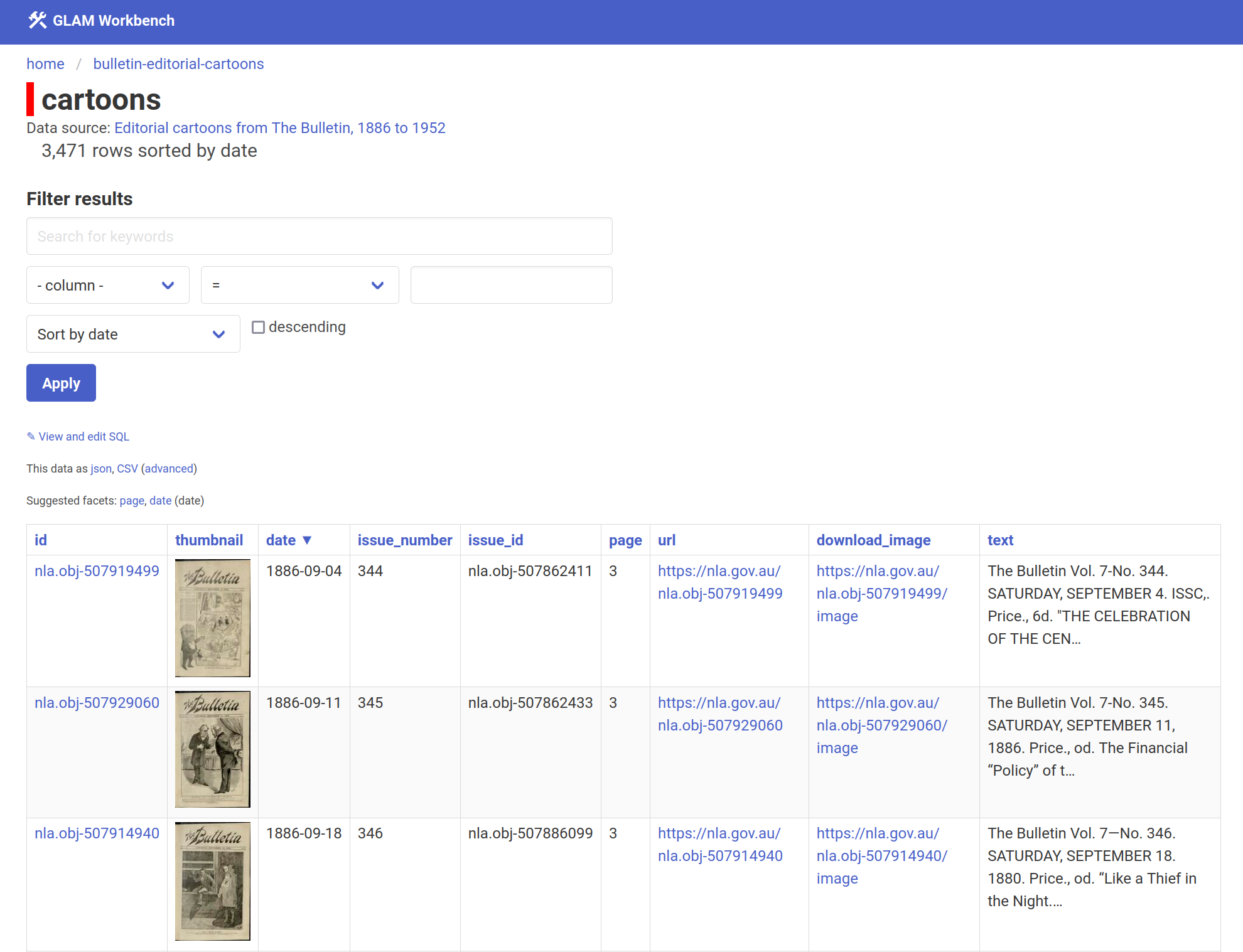
Editorial cartoons from The Bulletin, 1886 to 1952 – the cartoons haven’t been updated, but I’ve created a new metadata file and fixed up some problems with page numbering
-
OCRd text from Trove digitised journals – I’ve reharvested all of the OCRd text and made it available as individual zip files for each title, and one big zip file with everything!
As previously noted, I’ve also made the Bulletin cartoons available through Datasette-Lite for easy exploration.