Explore Trove's digitised maps
Trove contains thousands of digitised maps from the collections of the National Library of Australia, but they’re not always easy to find because of the way they’re arranged and described. To help you explore these maps I’ve created a new database and published it using Datasette.
Try it now!
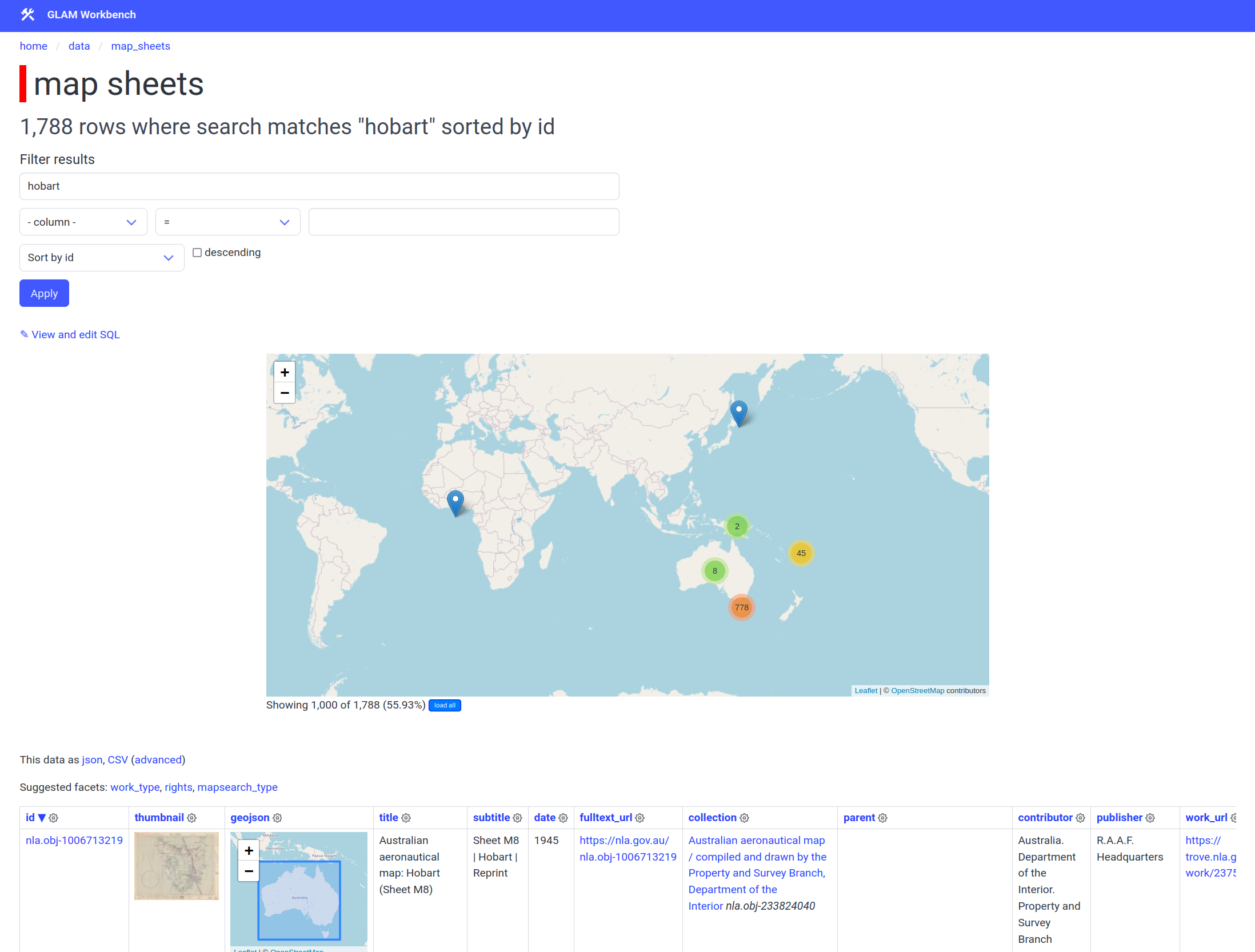
To get started, head to the map sheets table and search for some keywords. The results are displayed both as a cluster map using Leaflet, and as a table. To view the details of an individual map sheet, click on the id value.
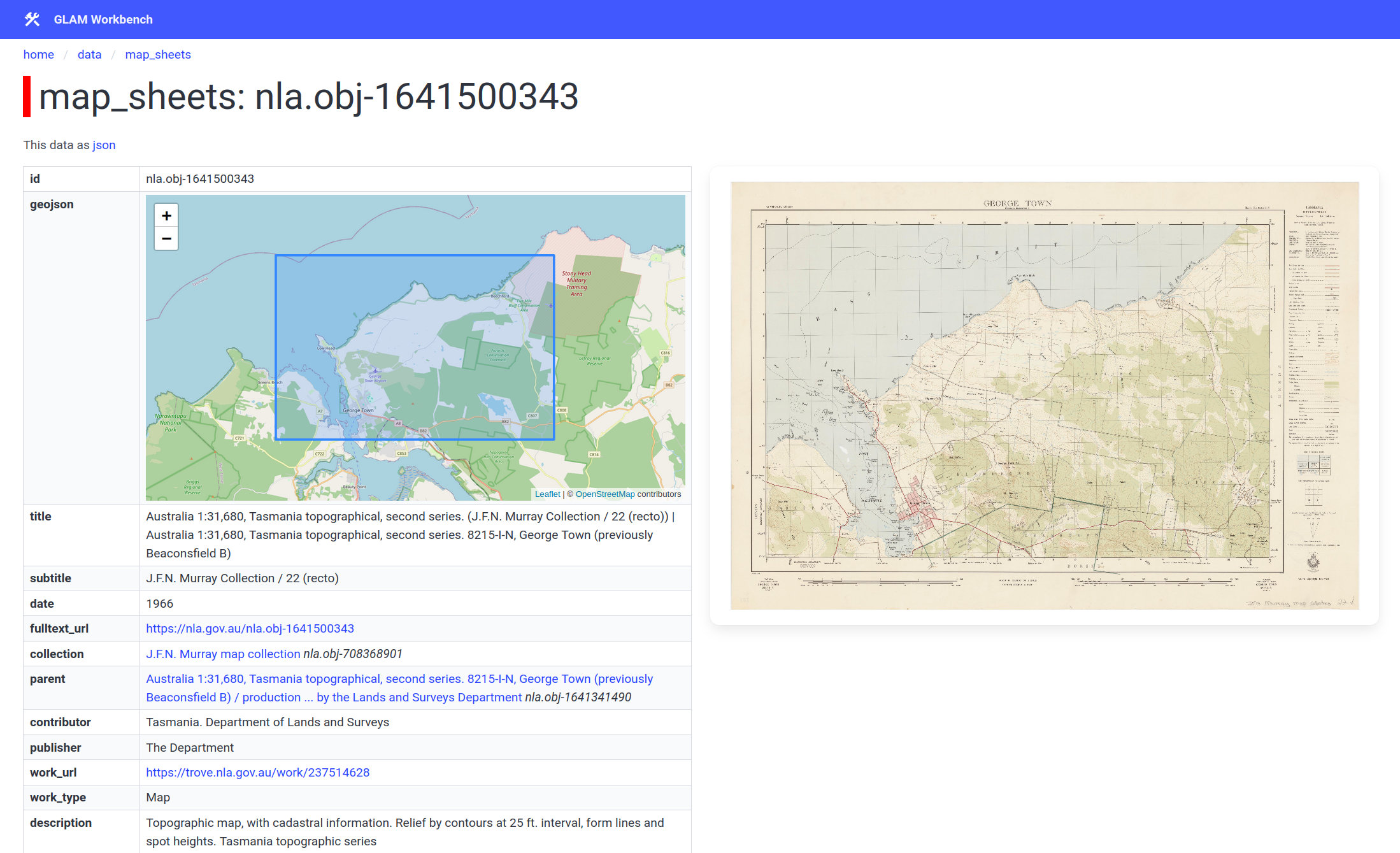
The individual record displays a zoomable version of the map image. If the record includes geospatial coordinates, these are also displayed on a modern basemap. There are also options to download the map image as a JPEG or a high-resolution TIFF (if available). Where possible I’ve also tried to link the Trove records to the NLA MapSearch interface.
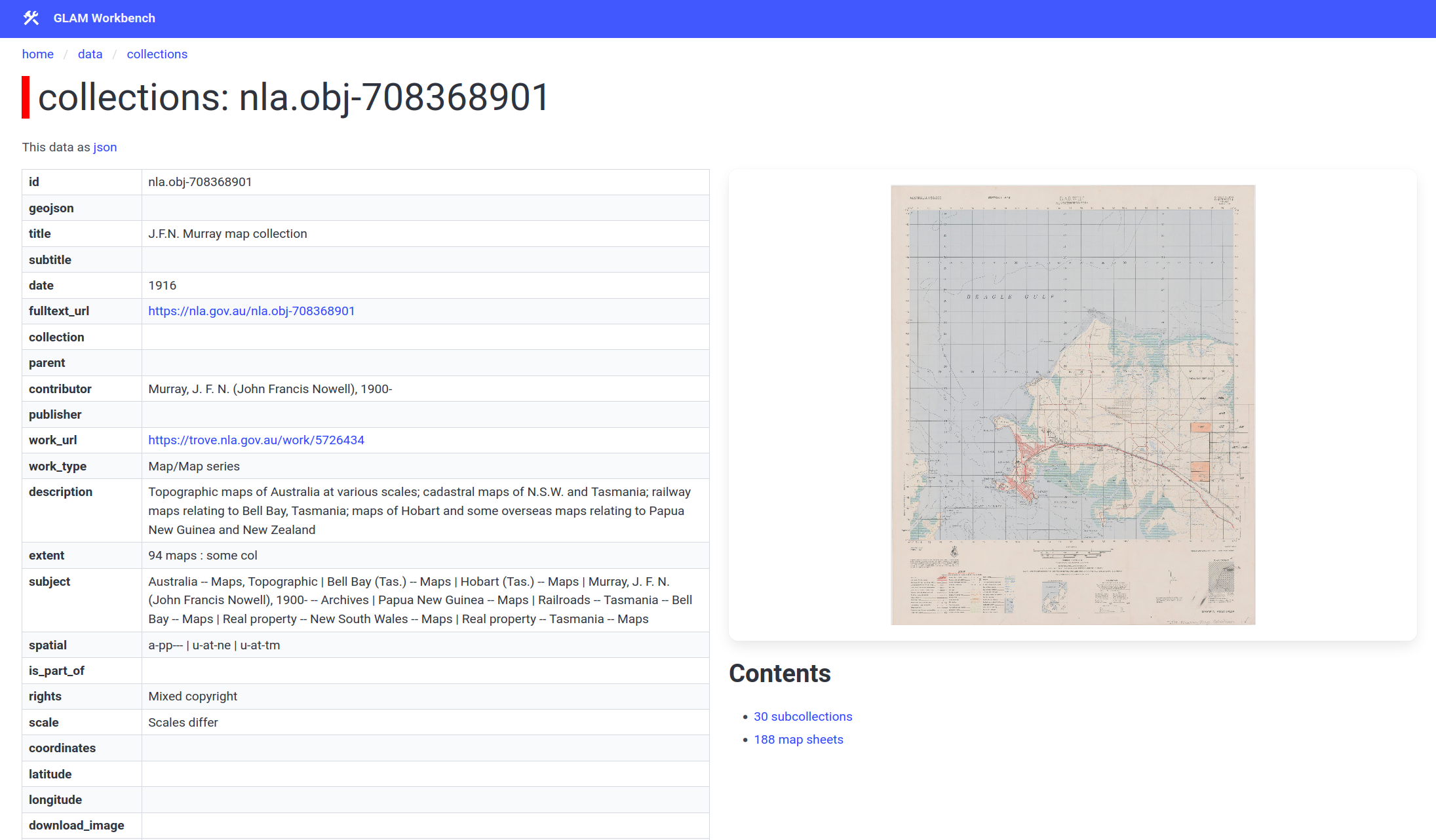
To find map collections, you can either search in the collections table, or click on the collection link in a map sheet record to move up the descriptive hierarchy. A collection record includes links to browse the sub-collections and map sheets it contains.
About the interface
I usually share GLAM Workbench datasets using Datasette-Lite, but in this case I’ve created a full Datasette instance running on Google Cloudrun. This is because of the size of the database, and because I wanted to try out some plugins that don’t work in Datasette-Lite. In particular:
- datasette-cluster-map – displays results on a cluster map using Leaflet
- datasette-leaflet-geojson – converts GeoJSON strings in cells into Leaflet maps, this creates the location previews in each row and item view
About the data
The data was compiled using the method outlined in the Trove Data Guide. This involves:
- harvesting all the work records from a search for maps
- unpacking any versions grouped within the work records
- using metadata embedded in the digitised object viewers to identify collections, harvest collection items, and enrich the records
- merging duplicate values and records
In addition, I’ve added geospatial information if it’s available. If there’s a corresponding record in NLA’s MapSearch interface, I’ve linked the records and added the geospatial data from MapSearch. Otherwise I’ve looked for geospatial information in the item metadata and attempted to parse the coordinates.
The result is a flat structure where every row in the database represents a record with a unique nla.obj identifier. I’ve divided the rows into three tables according to their position in Trove’s descriptive hierarchy – collections, sub-collections, and map sheets. Collections have child records, but no parents as they’re at the top of the hierarchy. Sub-collections have parent collections as well as child records. Map sheets have no child records but can belong to collections or sub-collections. There are links within each record to help you navigate up and down this hierarchy.
You’ll notice some problems and limitations with the data, in particular, maps within collections sometimes inherit their metadata from their parent. This means that their geospatial coordinates refer to the whole series, rather than the individual sheet. There are also numerous errors in the geospatial coordinates parsed from metadata.
Coming soon
I originally harvested this data to try and help me understand the scope of the digitised maps in Trove. I’m currently adding a ‘Maps’ section to the Trove Data Guide in which I’ll provide an overview of what’s available, and document methods for accessing and using the data.
The notebooks used to create the dataset will be added soon to the Maps section of the GLAM Workbench. I’ll also be sharing CSV-formatted versions of all the data.