Major update for the Trove Newspapers section of the GLAM Workbench
The Trove newspapers section of the GLAM Workbench was updated last week. Over the last year I’ve been gradually updating notebooks to use version 3 of the Trove API, but when version 2 suddenly disappeared a couple of weeks ago I had to hurriedly pull everything together. The Trove newspapers section includes 23 notebooks and 6 datasets, so it’s not a small job. The changes include:
- updated all notebooks to use version 3 of the Trove API
- removed remaining datasets from the code repository and created dedicated data repositories for them, integrating them with Zenodo where appropriate
- added metadata to all the notebooks – this is used to build an RO-Crate metadata file for the code repository
- updated all the Python packages
- added a
voila.jsonfile to configure Voilá
None of the functionality of the notebooks should have changed. There’s a slight difference in the Finding non-English newspapers in Trove notebook because the language detection library I was using is no longer maintained. I’ve swapped in py3langid and it seems to work well, though the results are a little different. Interestingly, where the previous library thought that bad OCR was ‘Maltese’, the new one detects it as ‘Latin’! There’s no change to the list of newspapers with non-English language content detected by the notebook.
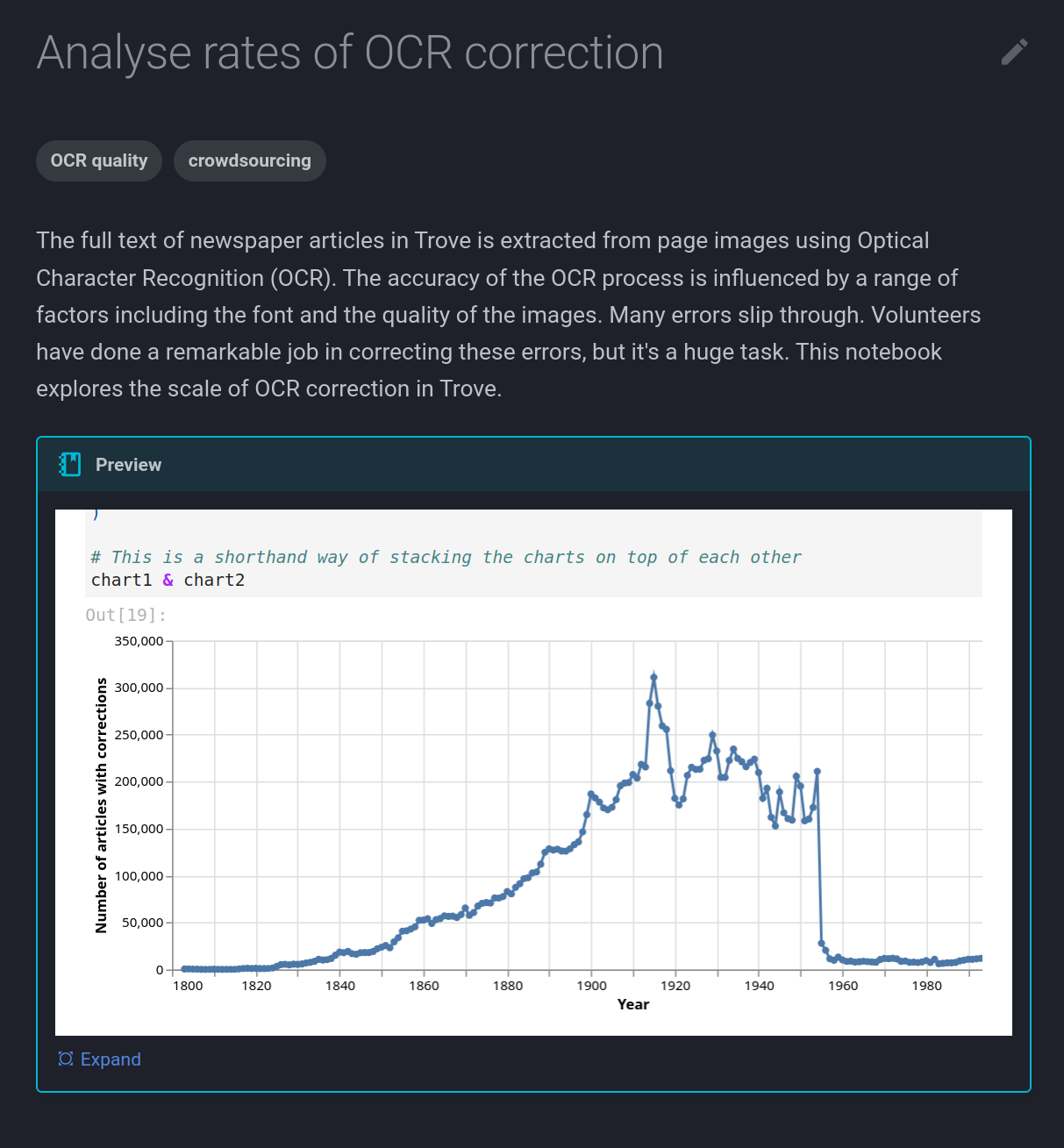
The documentation pages have also been updated. The notebook pages are now built using data from the code repository’s RO-Crate file. They also include embedded HTML previews of the notebooks. If a notebook generates visualisations, the visualisations are usually included in the HTML, so you can explore the outputs without running the notebook – see, for example, the charts in Visualise the total number of newspaper articles in Trove by year and state. Most of the dataset pages now include links to explore the contents using Datasette-Lite.
I still have to generate RO-Crate files for all the data repositories, but I wanted to get the code stuff finished first.