15 years of work on Trove threatened by the NLA
See my latest post for an update!
On Friday, without warning, I received an email from the National Library of Australia informing me that my Trove API keys had been suspended. This threatens the future of 15 years of work helping people use and understand the possibilities of Trove for new types of research.
What’s happened?
Here’s the full text of the email:
Your recently published work on the GLAM Workbench regarding extracting metadata and text from a National e-Deposit (NED) periodical has been brought to the Library’s attention.
Trove API Terms of Use specify that developers may access metadata only and do not provide extended rights. We consider the use of an API to extract and save full text as being in violation of the Terms of Use.
Effective immediately, the four API keys currently registered to you: glamworkbench, headlineroulette, troveconsole and wragge will be suspended.
Please feel free to get in touch for a more detailed conversation about this.
The reasons given for switching off my access don’t make any sense. While the API terms of use only mention metadata, the API, by design, delivers full text from newspapers, digitised periodicals and some books. If you interpret the terms of use as above, simply using the API as it has been designed and documented would be seen as a breach! Surely that’s nonsense.
In any case, the notebook they mention doesn’t even use the Trove API, so it’s hard to see how it could breach the API terms of use. I extracted the text from the periodicals simply by downloading the PDFs and using a standard PDF library. The notebook does scrape some metadata from the Trove website. This is necessary because the API has major limitations – you can’t, for example, get the members of a digitised collection. The NLA might want to argue that scraping breaches the website’s terms of use, but that’s a different point. I’d also note that I’ve been scraping data from the Trove website for 15 years without any objections (see below for more).
When I was Trove manager, I drafted a previous version of the API terms of use. It was a lot less legalistic back then, and I’ve always understood that the point of the API and website terms of use were to protect the NLA from exploitation by commercial interests, not to inhibit work done by researchers in good faith.
I developed the NED notebook in response to a request for help by a community group that uses the National eDeposit service to preserve its newsletter. I did it for free, and I documented the results in the GLAM Workbench in case it might be of use to other communities and researchers.
The ‘has been brought to the Library’s attention’ bit is also grimly amusing. Everything I do is open, and wherever possible I tag GLAM organisations on social media to let them know I’m making use of their collections. The email makes it sound like I was trying to hide what I was doing, when in fact I tagged them on Facebook and LinkedIn. I was thought they might be interested, and I suppose they were, just not in the way I hoped.
What’s at risk?
What’s the consequence of switching off my API keys? A few long-running services were broken immediately. Others will continue to work, but I’ll be unable to maintain them over time. Obviously I won’t be able to develop new Trove-related resources, and perhaps most importantly, my ability to help researchers with their Trove problems will be severely limited.
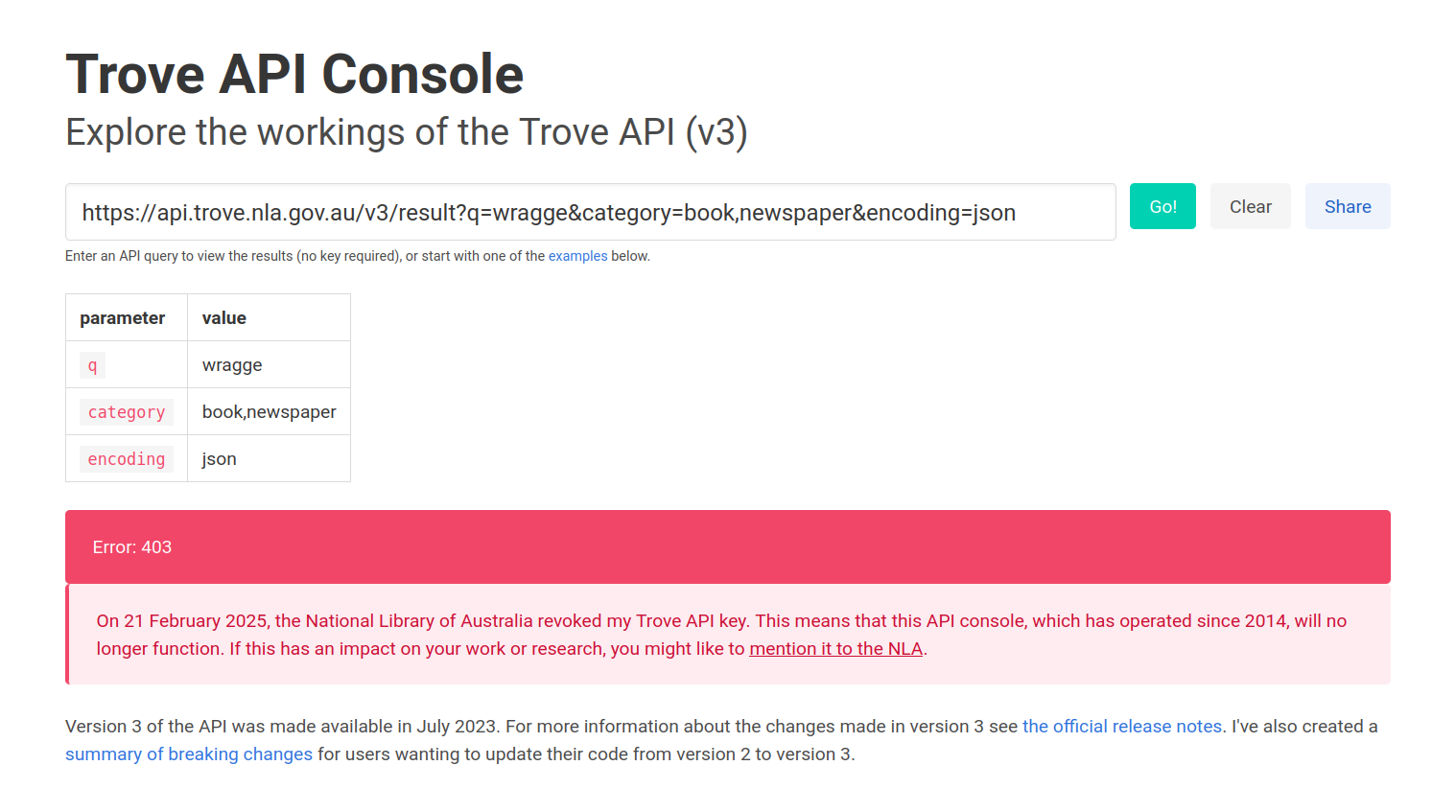
Tools and services that were broken immediately:
- The Trove API Console – running since 2014, the API console has helped many people learn to use the API. I created it when I was Trove Manager, and it’s still linked from Trove’s Create something page.
- The Trove Newspaper Data Dashboard (and related data harvests) – running since 2022, the data dashboard enables researchers to understand how the Trove newspaper corpus changes over time. The dashboard depends on weekly data harvests that can no longer run, so there will be no further updates. Similarly other automated data harvests capturing and sharing data about Trove categories and contributors are now broken.
- @troveNewsBot – created back in 2013, the bot has survived changes to the Trove API, the demise of Twitter, and a recent forced change of Mastodon instances, but it can’t work without an API key. I’m already missing it’s regular posts.
- Headline Roulette – just a simple game, but a fun way to start a workshop and get people thinking about the possibilities of Trove, it’s been running since 2010.
Tools and resources that I won’t be able to update or maintain:
- The GLAM Workbench includes more than 80 Jupyter notebooks that demonstrate how to work with data from Trove. Most of these require an API key. Fortunately users will still be able to use them with their own keys, but I won’t be able to do any further development or testing. This includes tools like QueryPic that I’ve been maintaining since 2013 and is cited in the research literature.
- The GLAM Workbench also includes more than 30 datasets capturing information about Trove. Some document changes in things like text correction, and the use of tags, while others provide alternative entry points to important collections of digitised resources, such as oral histories and maps. I won’t be to update any of these datasets.
- The Trove Data Guide incorporates many visualisations and summaries generated from Trove data. I won’t be able to update these. There are also many API examples that link to the now broken API console.
- trove-newspaper-harvester is a Python package that’s existed in different forms since 2010. It’s used by researchers to create datasets of newspaper articles and has been cited a number of times in the research literature. It won’t be immediately affected because users supply their own API keys, but I won’t be able to maintain it into the future.
- Trove places is a map based interface to Trove’s newspapers. It’s dependent on data harvested using the API, so I won’t be able to update it.
Planned developments I won’t be able to undertake:
- I had hoped this year to automate more data harvests so I could, for example, provide regular updates on digitised collections such as books, periodicals, and maps.
- I was planning to add a number of new sections to the Trove Data Guide, including maps, photos, ephemera, and manuscripts.
- I was intending to update the trove-newspaper-harvester to make it possible to identify and capture changes in a results set.
I’m very disappointed that the automated data harvests are now broken. As I suggested in this post, I think it’s important that we capture information about online collections so that future researchers will be able to investigate their impact. I’ve been working to streamline, standardise, and automate this data collection, both through the weekly harvests and the Trove historical data collection in Zenodo. But this will now stop.
Most disappointing of all, however, is that without an API key I won’t be able to help researchers who come to me asking how to get data out of Trove. In finding solutions to their problems I often end up creating new notebooks so that the knowledge can be shared and all researchers can benefit. I won’t be able to do this any more.
The GLAM Workbench includes a list of published research articles that cite the GLAM Workbench or one of its associated tools, such as QueryPic and the Trove Newspaper Harvester. Many of these publications have used my tools to work with data from Trove. This sort of research will suffer if the tools can’t be maintained.
Of course, all of my work is openly licensed and freely available through GitHub and Zenodo. If I can’t maintain the code, hopefully others will jump in and take over.
Trove and me
I started scraping data from the digitised newspapers in 2009, before they were even a part of Trove. In 2010, I created the first versions of QueryPic and the Trove Newspaper Harvester. There was no API then, so I built a library of screen scrapers to extract the data. I ended up publishing my own ‘unofficial’ API using the screen scrapers. I found out later that my ‘unofficial ' API was used in the design of the official version that became available in 2012.
The work I was doing analysing digitised newspapers won me the NLA’s Harold White Fellowship in 2012. In 2013, I was appointed Trove Manager. Throughout my time at the NLA I lived something of a double life – manager by day, hacker by night. I continued to build tools and demonstrations to help people understand what the API made possible. Talking about the API and the new types of research that Trove opened up was one of the favourite parts of my job.
Nothing much changed after I left the library. I continued to build tools, help researchers, and give talks and workshops on the possibilities of Trove data. In 2017, I started to bring a lot of this work together within the GLAM Workbench. In 2023-24, I worked with the Australian Research Data Commons to develop the Trove Data Guide, documenting what I knew about Trove’s intricacies and inconsistencies.
My point really is that I’ve been doing this for 15 years now. Everything has been in the open, my approach has never really changed, and some of the work was actually supported by the NLA. So what’s different now?
Certainly the NLA’s attitude has changed. When I was Trove manager we used to celebrate the interesting things that people did with the Trove API. In contrast, the NLA has never publicly acknowledged that the GLAM Workbench exists, and certainly hasn’t shared any links to it. This was taken to ludicrous extremes in 2021, when the NLA’s draft project plan for funding as part of the ARDC’s HASS Research Data Commons proposed to duplicate tools already available through the GLAM Workbench. Just a few months earlier in December 2020, the GLAM Workbench won the British Library Labs Research Award. It’s strange that there has been much more engagement with the GLAM Workbench from national libraries in Europe than Australia.
I don’t know why this is, but it has been immensely frustrating, even heart-breaking. I do the work I do to help people use and understand Trove. But how do they find out about it? You’d think that the NLA would be pleased to support researchers by pointing them to tools and resources that would help them make best use of Trove. You’d think that the NLA would be thrilled to have people spending their own time and money to build and maintain those resources. But no.
It seems to me that the NLA has become increasingly closed off and defensive in recent years. Perhaps that’s to be expected given the funding pressures they’ve faced. But in challenging times you’d think it was more important than ever to bring together your supporters.
Much of my work does involve criticism of Trove. It’s an unwieldy beast, with many problems and inconsistencies. It’s part of my job (mission? calling?) to expose these problems and help users work around them. It wouldn’t help anyone for me to ignore Trove’s shortcomings. My criticisms come with suggestions and solutions. My aim is not to undermine, but encourage – to guide people past the many pitfalls and challenges to find the treasure within.
Back in November 2016, on the day after Trump’s first election victory, I gave a short presentation at the ‘Digital Directions’ conference in Canberra. The main point of my talk, entitled ‘Caring about access’, was that GLAM organisations should embrace criticism. Here’s part of what I said:
Access is not something that cultural institutions bestow on a grateful public. It’s a struggle for understanding and meaning. Expect to be criticised, expect problems to be found, expect your prejudices to be exposed. That’s the point.
If cultural institutions want to celebrate their website hits, celebrity visits, or their latest glossy magazines – well that’s just fabulous. But I’d like them to celebrate every flaw that’s found in their data, every gap identified in their collection – that’s engagement, that’s access. We need to get beyond defensive posturing and embrace the risky, exciting possibilities that come from critical engagement with collection data – recognising hacking as a way of knowing.
In this new post-truth world it’s going to be more important than ever to challenge what is given, what is ‘natural’, what is ‘inevitable’. Our cultural heritage will be a crucially important resource to be mobilised in defence of complexity, nuance, and doubt – the rich and glorious reality of simply being human.
The early part of that 2016 was dominated by the #fundTrove campaign, when Trove users mobilised to make the government aware of its importance to the Australian community. It took over my life for a while, and while many were keen to claim credit for the campaign’s ultimate success, it left me thinking that GLAM organisations need to better understand who their real friends are – the people who actually give a shit. It seems that the NLA is still struggling with that.
So what now?
I have to admit that the NLA’s inability to acknowledge the existence of the GLAM Workbench has taken an emotional toll. At times I’ve considered giving up the work. Why bother if it’s not going to get to the people who might benefit most?
So at this moment I don’t feel like arguing with the NLA. If they think so little of my work that they’re happy to simply pull the plug and let it die, then what’s the point in trying to continue?
However, there’s a bigger issue. Whatever happens to my work, it’s important that this type of work be encouraged and supported. Trove offers immense possibilities for new types of research and we need to explore and document them together. Central to this is a well-supported API. I’m worried that this little battle is actually a sign of waning commitment to the API and what it represents. Earlier this year I was shocked when the NLA suddenly decommissioned version 2 of the API without fixing major bugs in version 3. I think we need to stress that easy access to Trove data is vitally important to the future of Australian HASS research.
So if you’ve used any of my tools or resources, or value the work I’ve been doing over the last 15 years, you might like to tell the NLA about it. I don’t know if it’ll make any difference, but at least they’ll be better informed about the sorts of things people are doing with Trove data, and the types of resources that are needed to support them.
Contact options:
-
Marie-Louise Ayres, Director-General of the NLA (directorgeneral@nla.gov.au)
-
Tony Burke, Minister for the Arts (tony.burke.mp@aph.gov.au)
Of course you can also share your thoughts on social media!
All posts on this topic:
- 25 February 2025: 15 years of work on Trove threatened by the NLA
- 2 March 2025: Trove API users beware! – the latest in the saga of my cancelled API keys
- 11 April 2025: Update on Trove data access and my suspended API keys
- 7 May 2025: Farewell Trove