One more and I’m done for the night… New GLAM Workbench page for the ‘Trove API introduction’ notebooks.
One more and I’m done for the night… New GLAM Workbench page for the ‘Trove API introduction’ notebooks.
I’ve finished putting details of all the current GLAM Workbench repositories into the new documentation site. Still a few notebooks to migrate from the original workbench, but getting there! There’s about 50 Jupyter notebooks so far. #dhhacks
Added a ‘data’ section to the GLAM Workbench docs, with info on harvests from government data portals, as well as series from @naagovau relating to ASIO and the White Australia Policy.
And now a GLAM Workbench page for @Te_Papa…
Added a page for @ArchivesNZ’s Archway to the GLAM Workbench docs…
So here’s some fun things to do with @TroveAustralia newspapers… (via GLAM Workbench)
Ok, more documentation for you — page for the @DigitalNZ API in GLAM Workbench updated!
Slowly working my way through the documentation for my GLAM Workbench. Still lots to do, but I think the page for @naagovau’s RecordSearch is now up-to-date.
If there are APIs or other data sources you’d like me to add to my GLAM Workbench, feel free to create an issue. You could also describe what sorts of tools or examples using that data source would be useful.
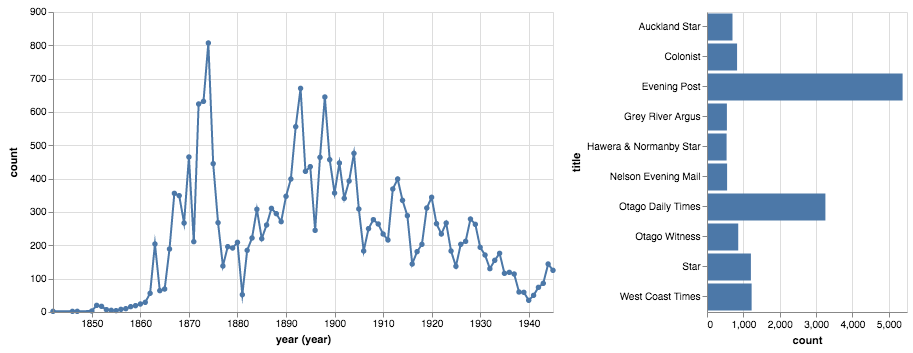
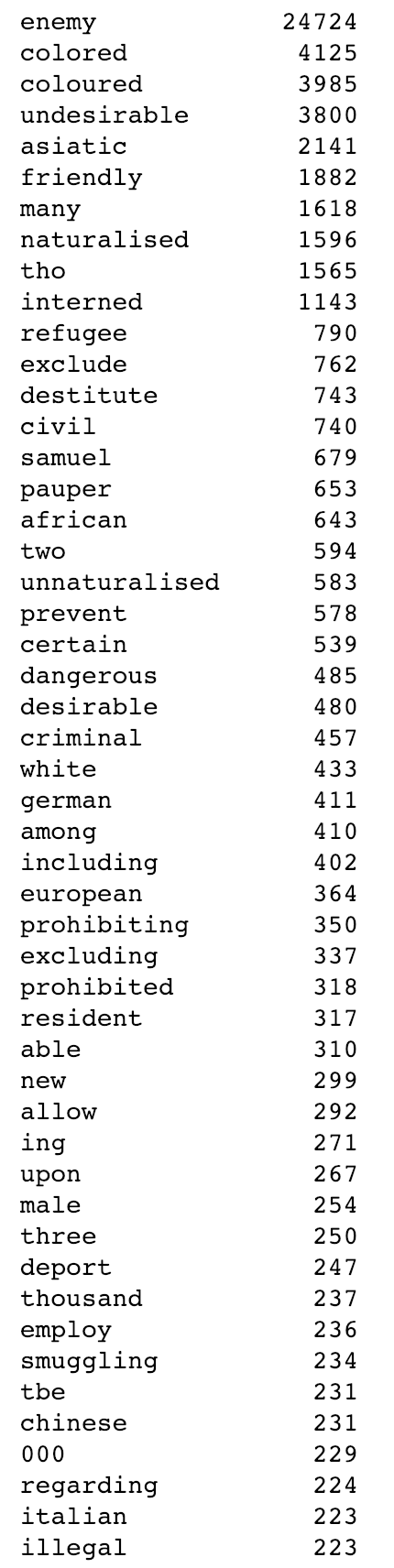
Updated list of the fifty most common words occuring before the word ‘aliens’ in @TroveAustralia newspapers (with no capitalisation and stopwords removed). 274,157 occurances in 213,151 articles.
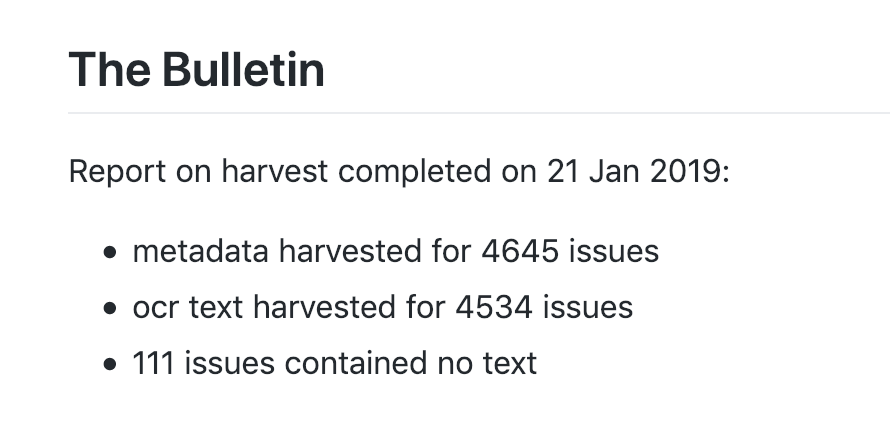
Just updated my harvest of metadata and full text from The Bulletin in @TroveAustralia. There’s about 2gb of OCRd text from 4,534 issues (1880-1968). Full text for about 60 issues have been added since my last harvest. 111 have no OCRd text. Download it all from GitHub #dhhacks
Fifty most common words occuring before the word ‘aliens’ in @TroveAustralia newspapers (213,000 articles)…

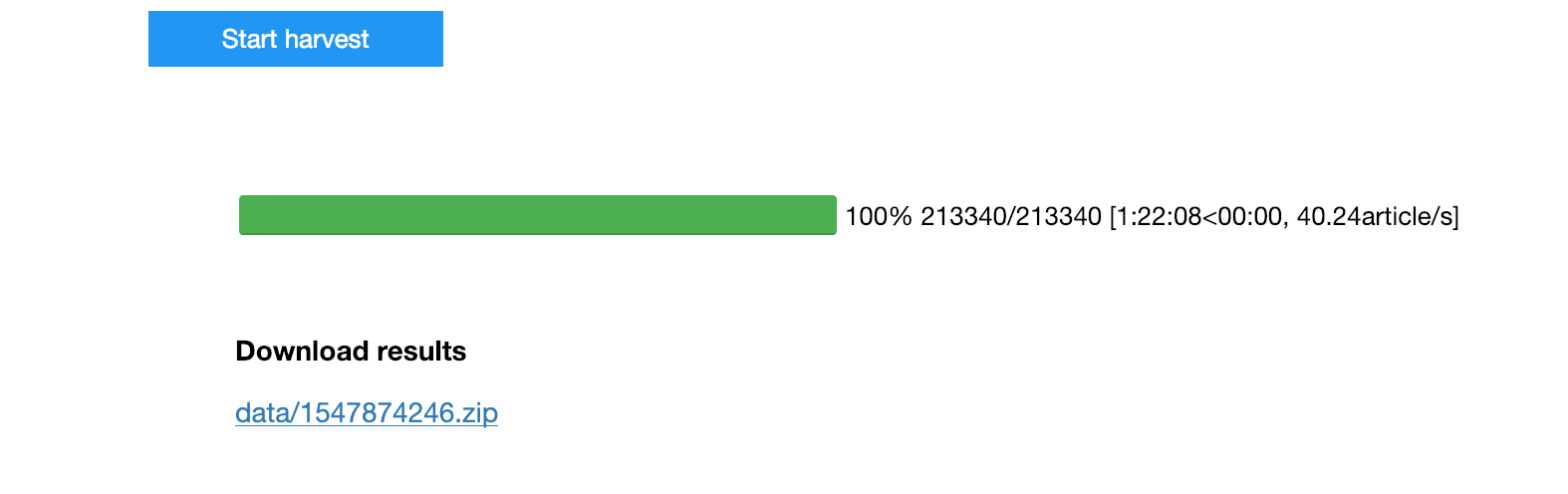
You want big data? I just harvested 213,340 newspaper articles (including full OCRd text) from @TroveAustralia in 82 minutes, at about 40 articles a second. https://mybinder.org/v2/gh/GLAM-Workbench/trove-newspaper-harvester/master?urlpath=%2Fapps%2Fnewspaper_harvester_app.ipynb
So now I’ve updated TroveHarvester and built a new interface I can get back to the task I wanted the TroveHarvester for a couple of days ago — harvesting all references to ‘aliens’ in newspapers… #yakshaving
Want an easy way to download @TroveAustralia newspaper articles in bulk? No installation? Point and click? I’ve created a simple web app version of my TroveHarvester using a Jupyter notebook & running on @mybinderteam. Try it live! #dhhacks
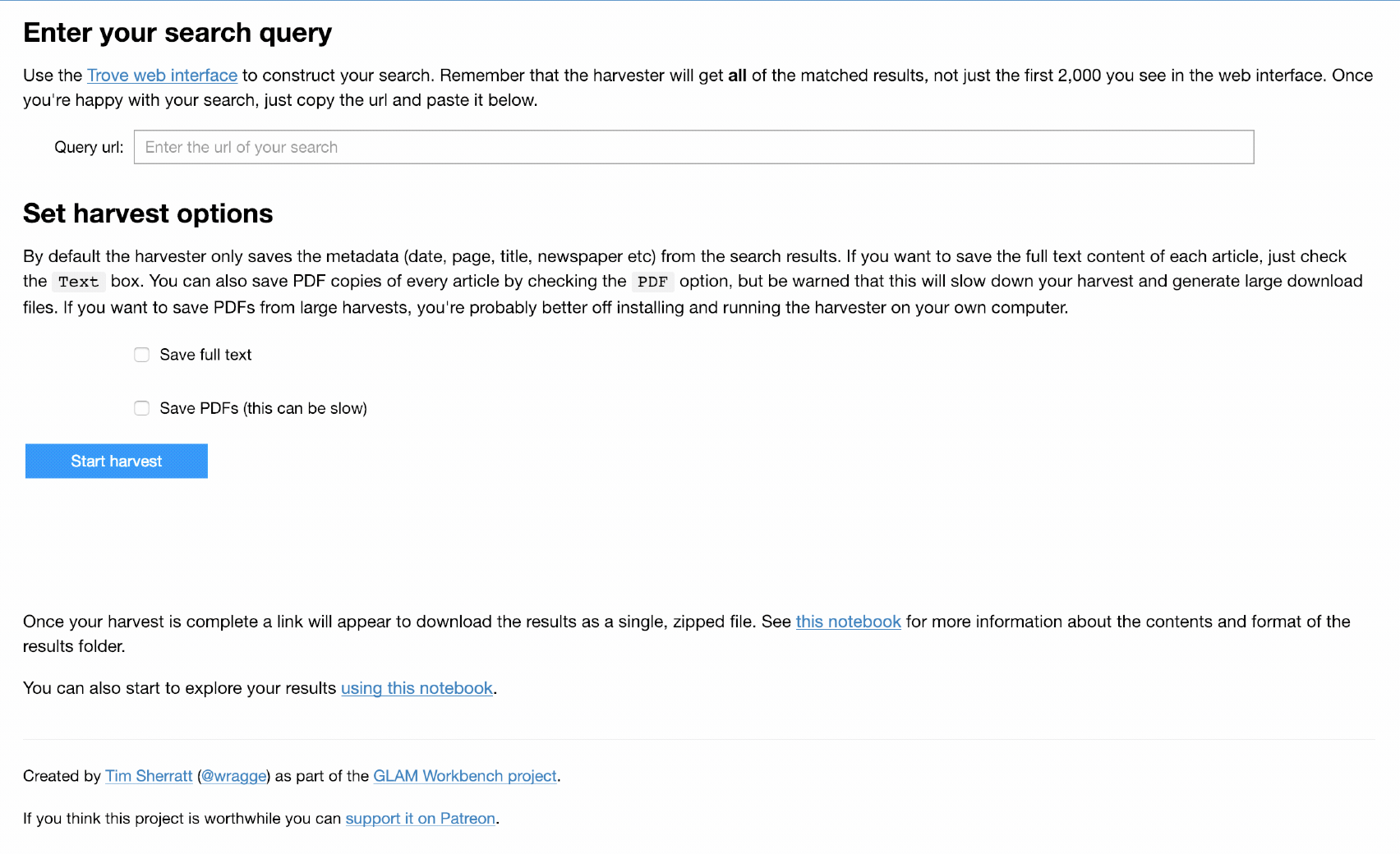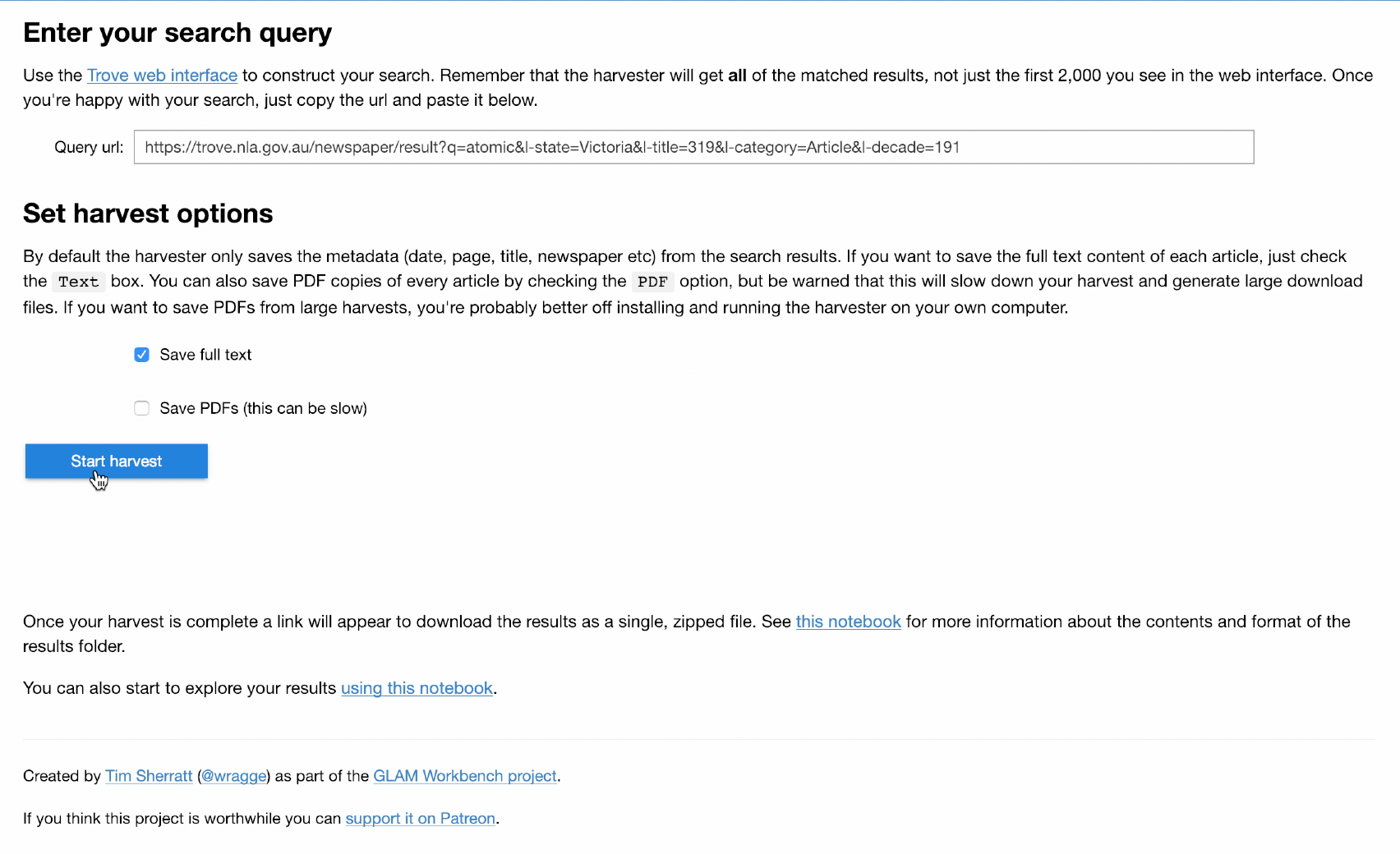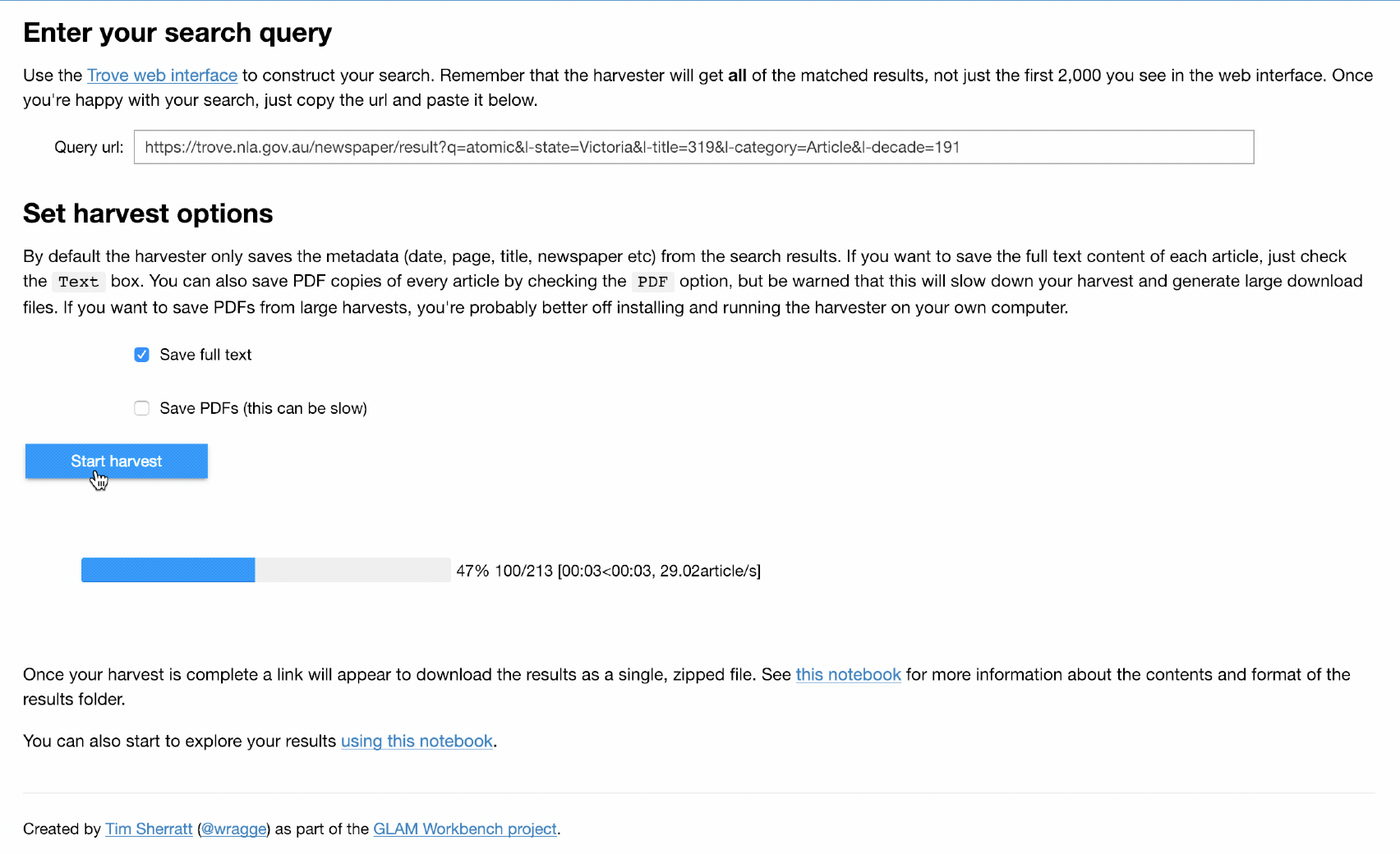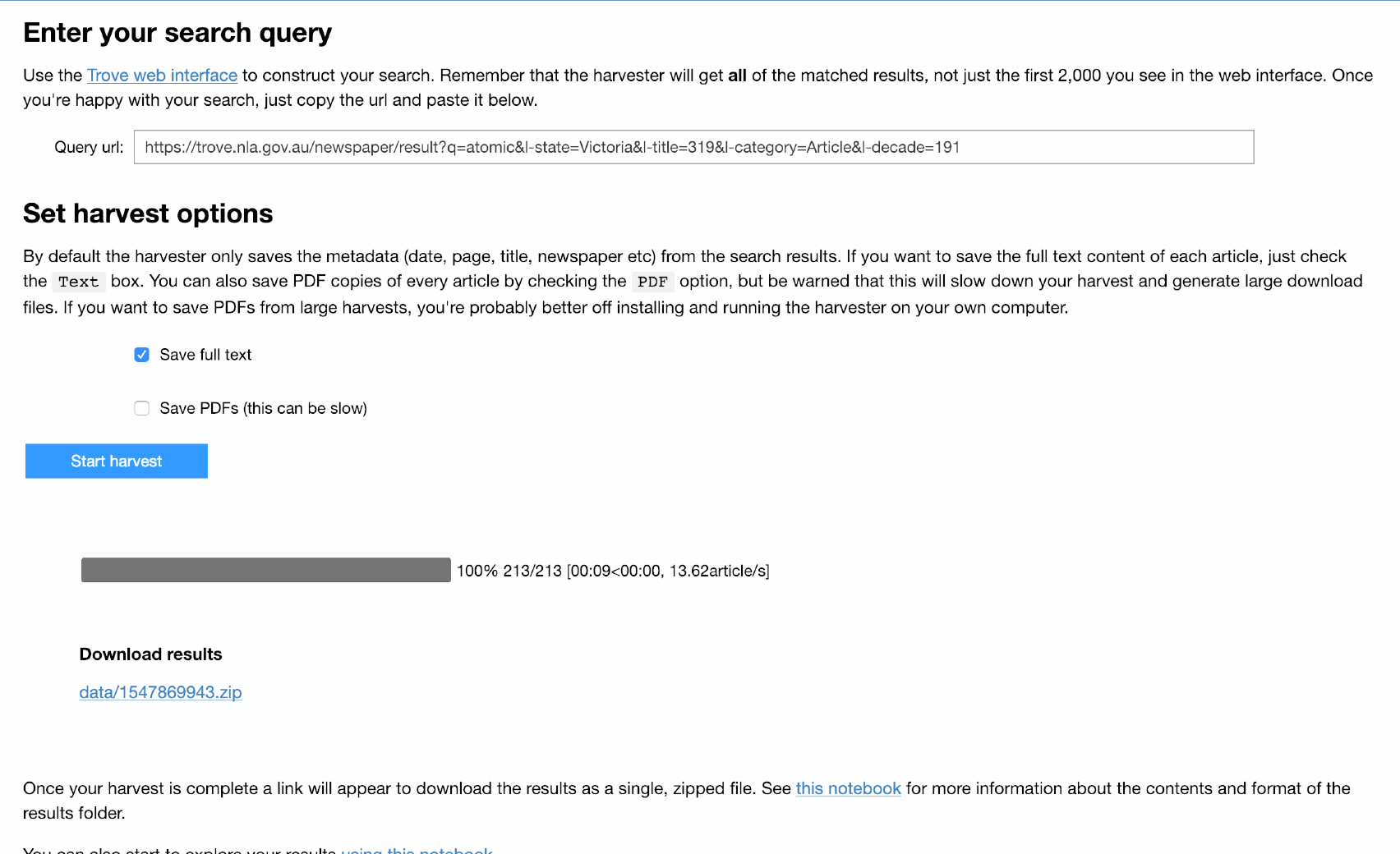
And version 0.2.2 of TroveHarvester quickly follows 0.2.1 as I squash a bug when downloading PDFs… Also managed to get the README displaying properly on Pypi. pypi.org/project/t…
TroveHarvester 0.2.1 — updated to work with version 2 of the @TroveAustralia API. Now on pypi! More details shortly…
Ok, that’s more like it. Full text and metadata of 29,203 newspaper articles harvested using the @TroveAustralia API in under 10 minutes. Testing nearly done…
Ah ok, I forgot about the new ‘bulkHarvest’ parameter in the @TroveAustralia API. Setting that to ‘true’ seems to make all the difference…
Uh, never come across one of these before from the @TroveAustralia API. Needless to say it causes the Newspaper Harvester to die.
It’s easy to check for these things once you know they exist, but…
