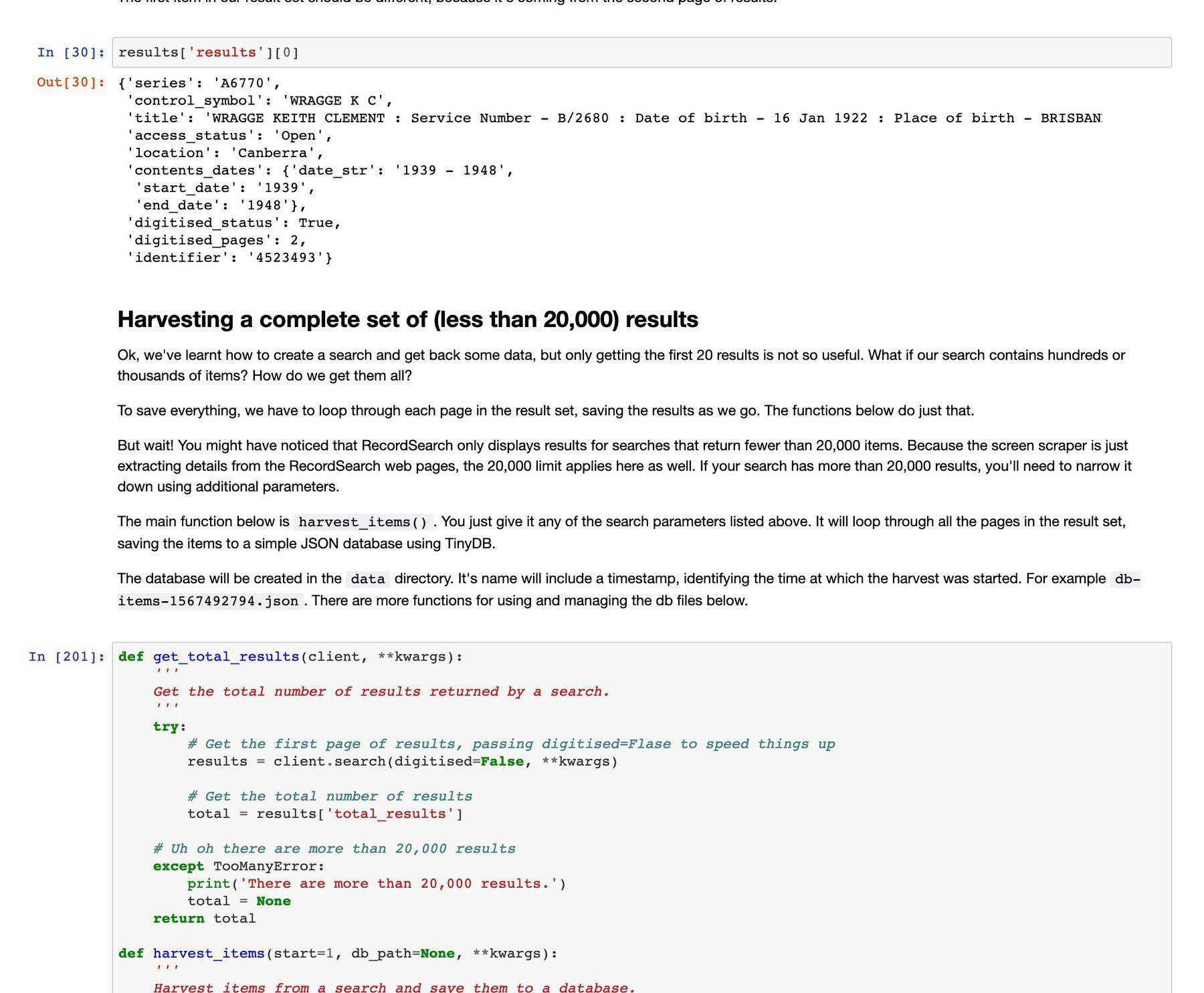
Want to save searches for items in @naagovau’s RecordSearch as CSVs for exploration & analysis? This notebook walks through the process of constructing, managing, and saving data harvests. #dhhacks
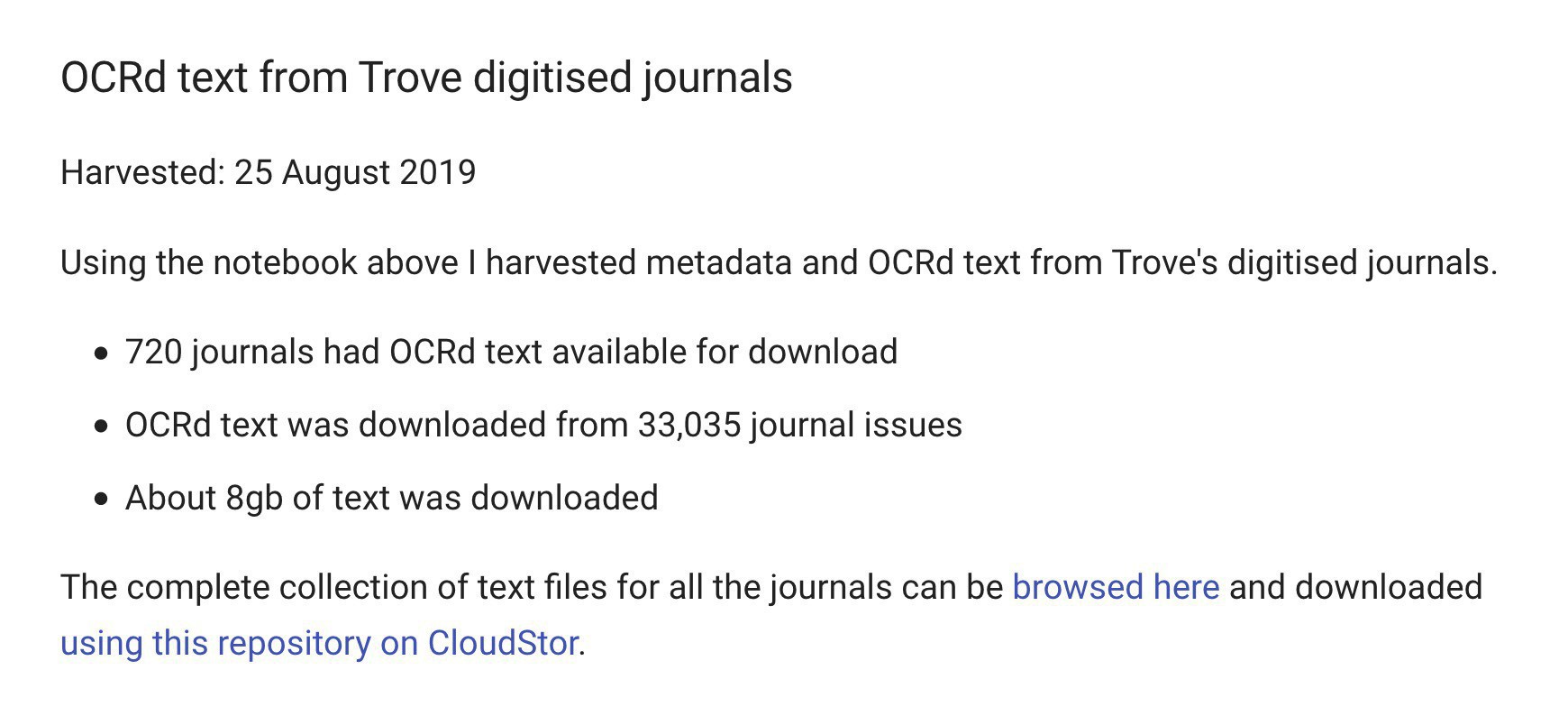
I’ve updated my harvest of OCRd text from digitised journals in @TroveAustralia. The complete dataset now includes 33,035 issues from 720 titles – about 8gb of text to explore. Details in the #GLAMWorkbench: glam-workbench.github.io/trove-jou… #dhhacks
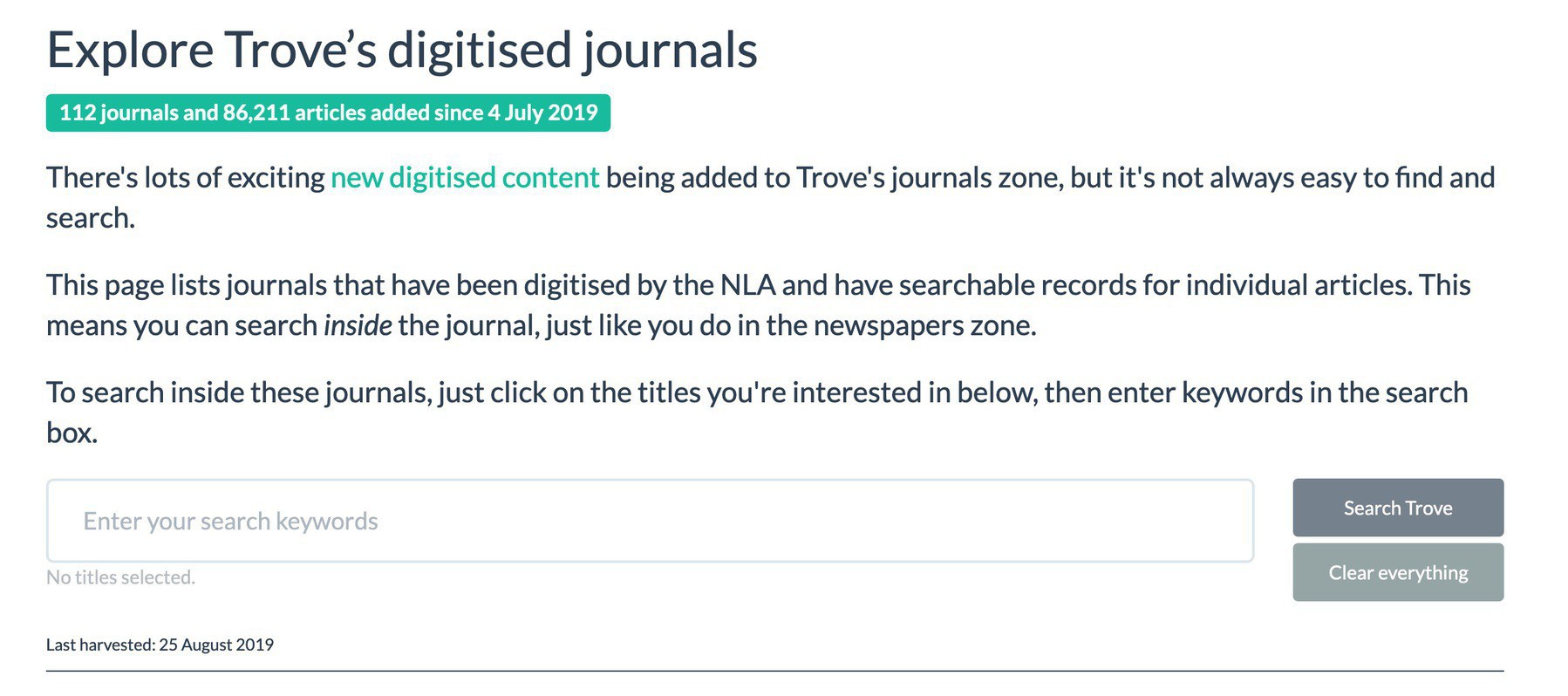
My app to browse & search @TroveAustralia’s digitised journals has been updated! Since 4 July, 112 new titles & 86,211 new articles have been added to Trove. Many of these new titles are parliamentary papers. Explore here: trove-titles.herokuapp.com #dhhacks
Another WIP notebook in need of additional documentation… This one explores the stats around volunteer correction of OCR errors in @TroveAustralia’s newspapers. More to come!
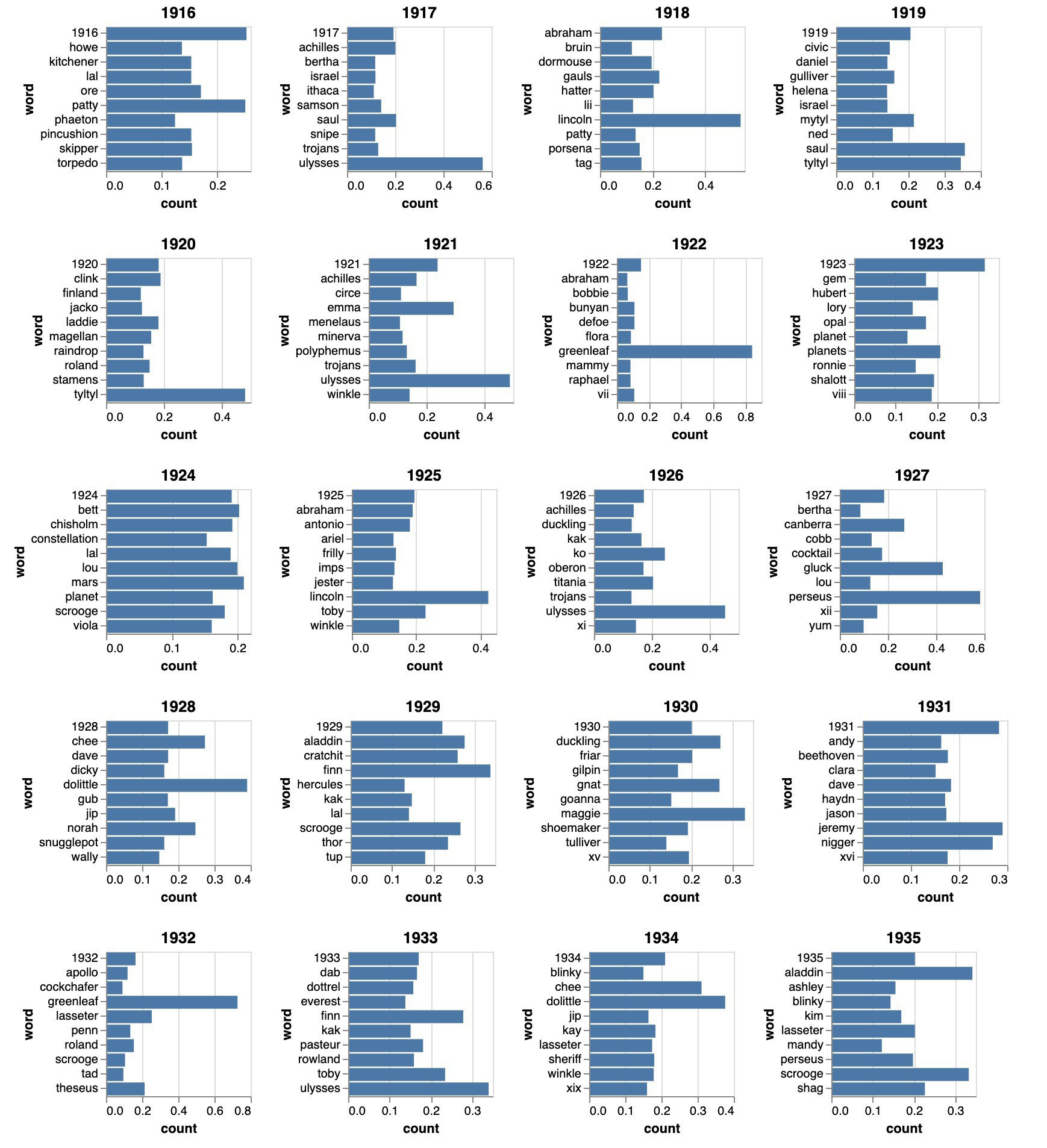
And this notebook uses TF-IDF to explore the OCRd text of a digitised journal from Trove. Get the top TF-IDF scores for each year across a journal’s life and see how they change. More documentation coming!
This notebooks lets you download the OCRd text of a digitised journal from @TroveAustralia (via CloudStor) and then explore word frequencies over time. More documentation coming soon!
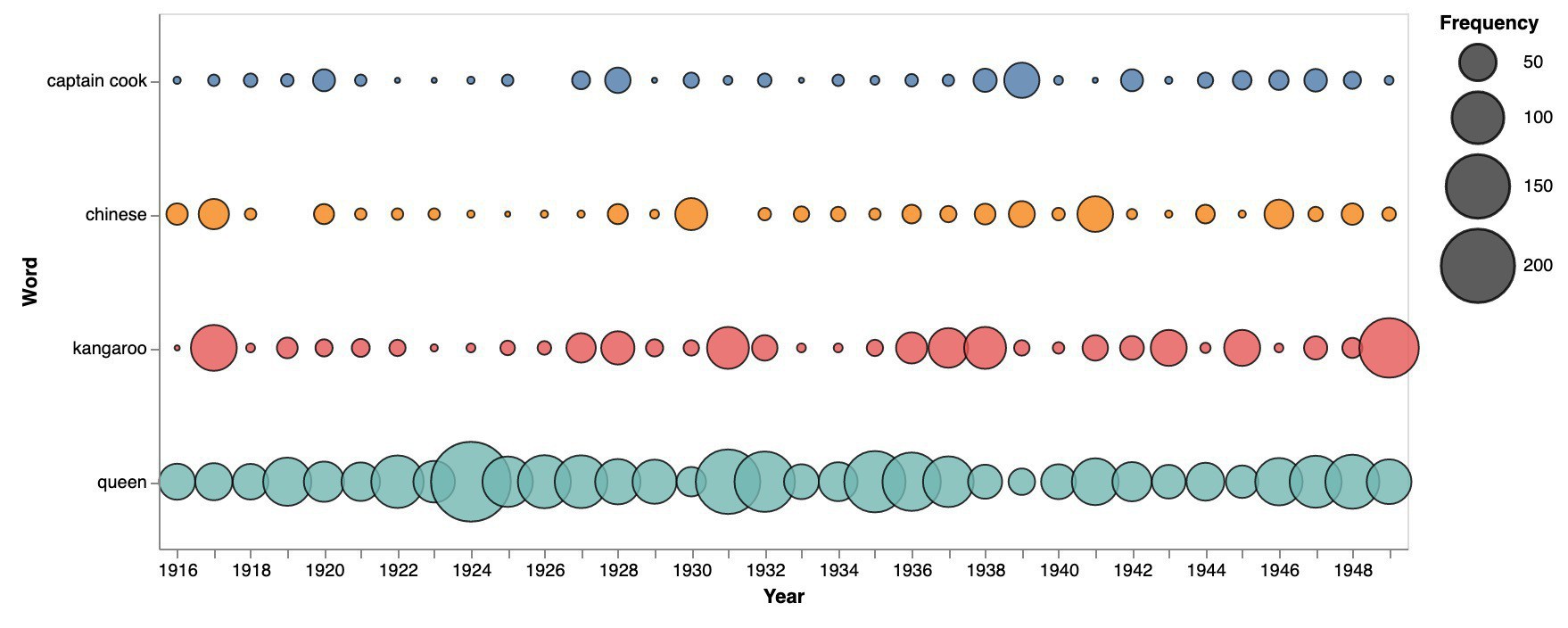
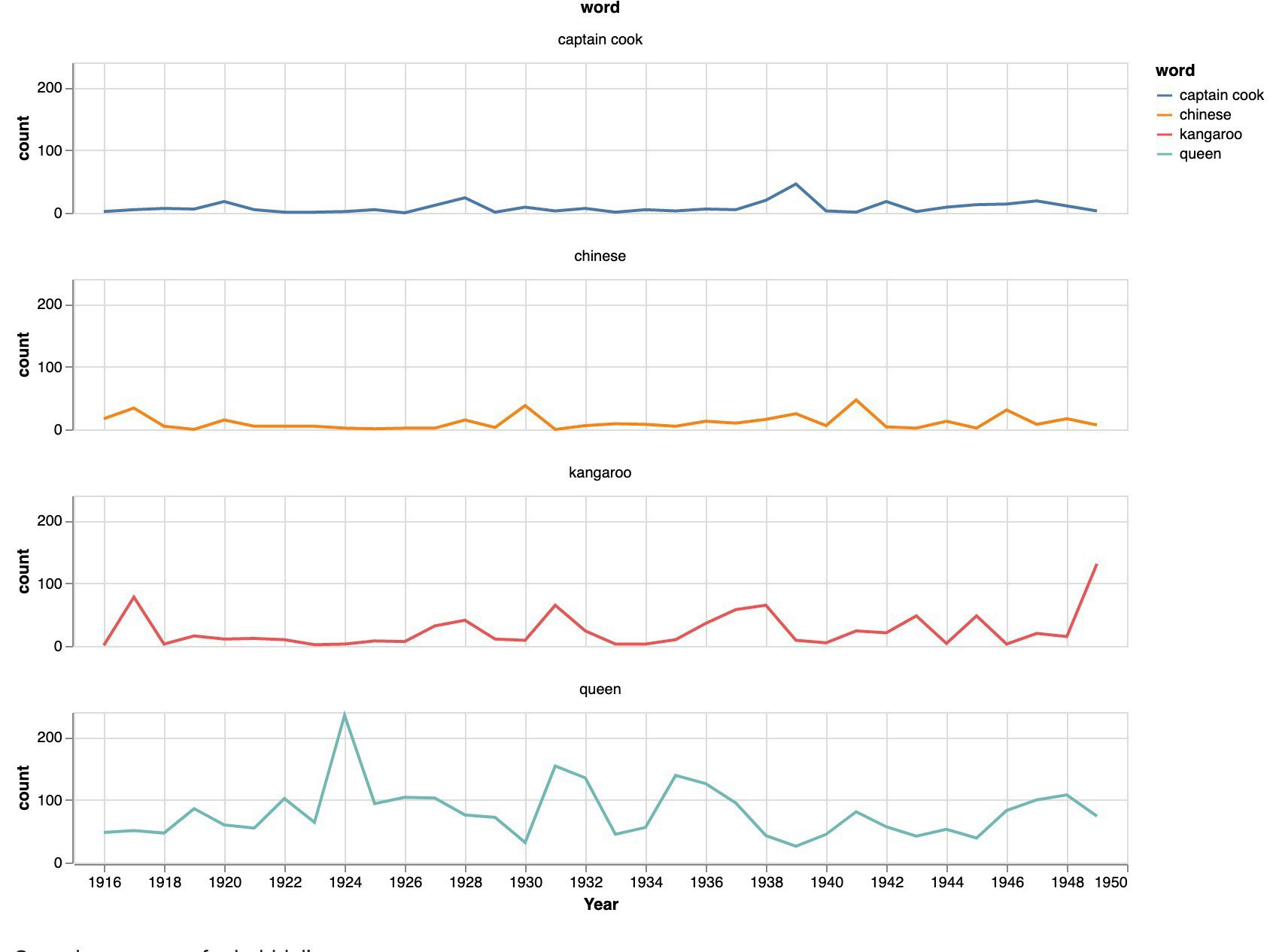
A new notebook looking at the data about digitised journals on @TroveAustralia. #dhhacks
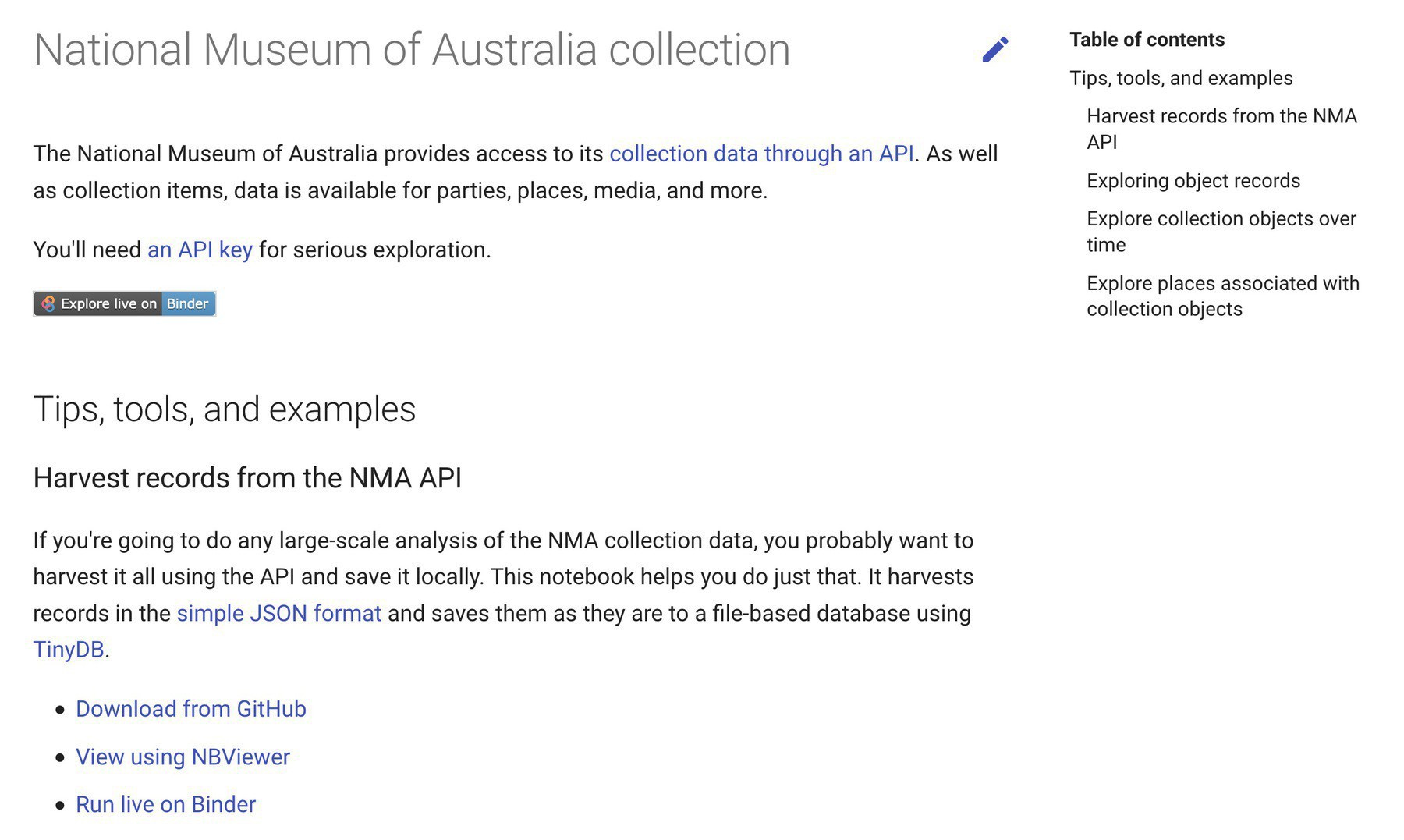
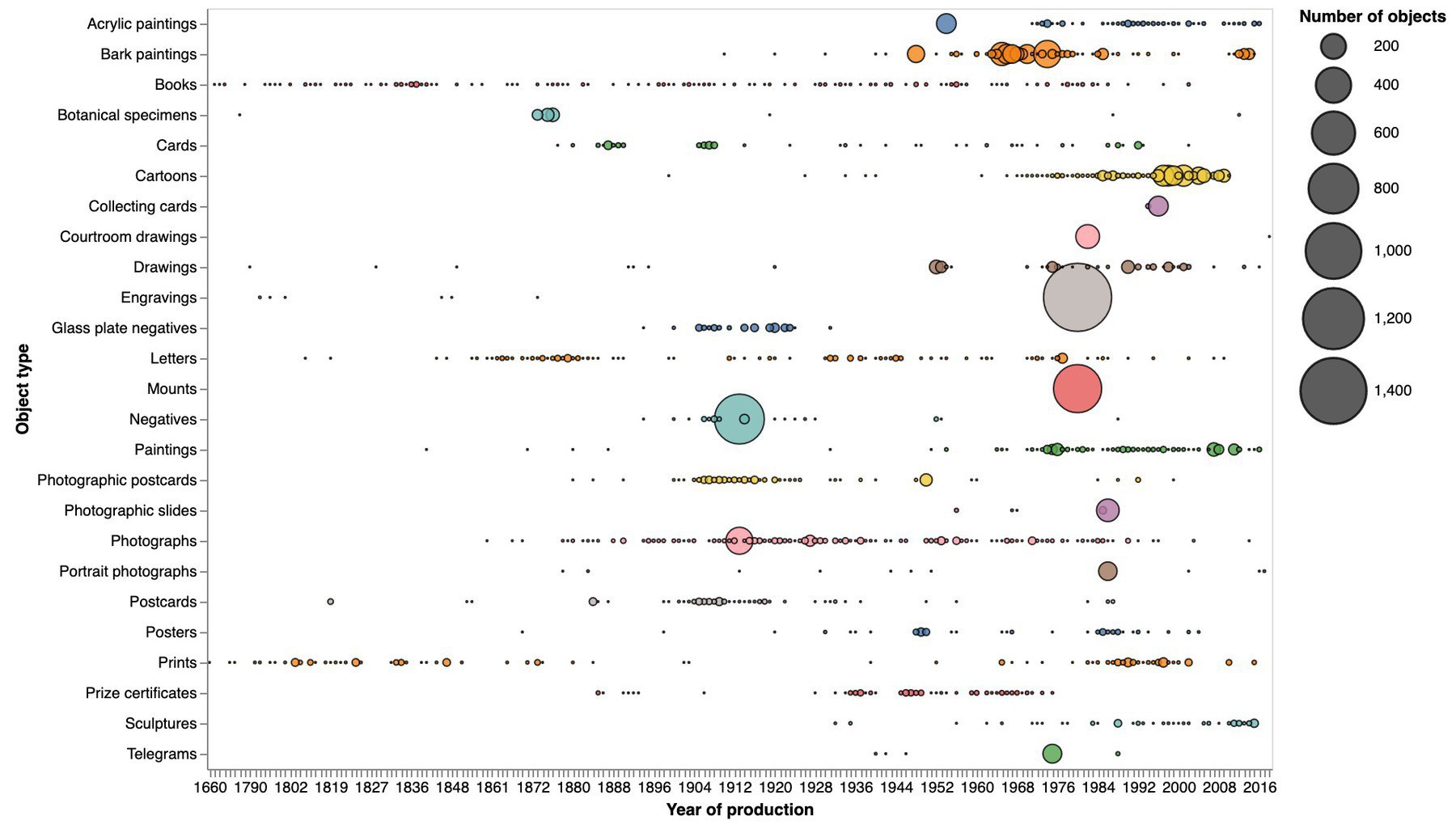
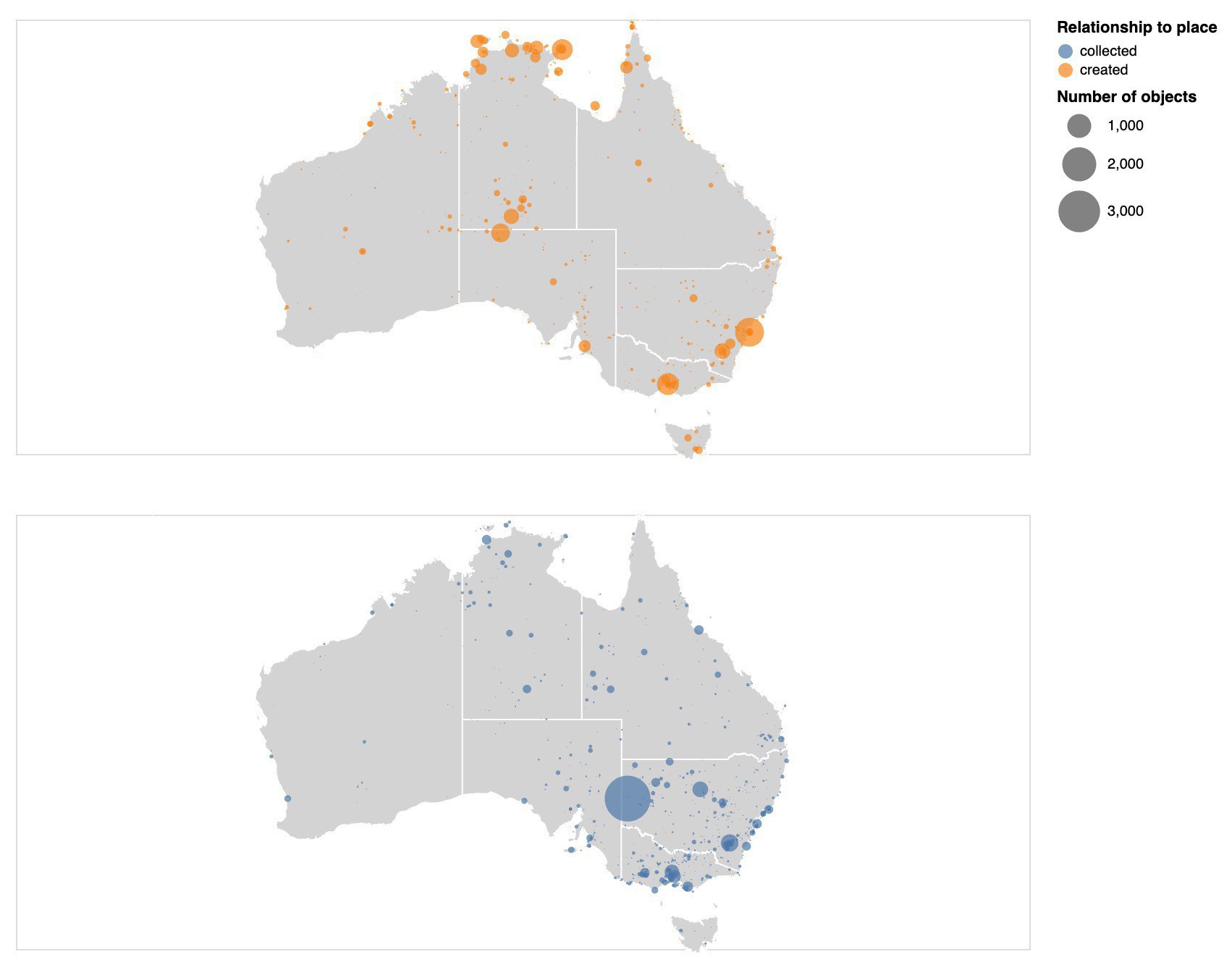
There’s a new section of the GLAM Workbench devoted to the National Museum of Australia collection API! Harvest @nma data, then explore it by time and place. #dhhacks
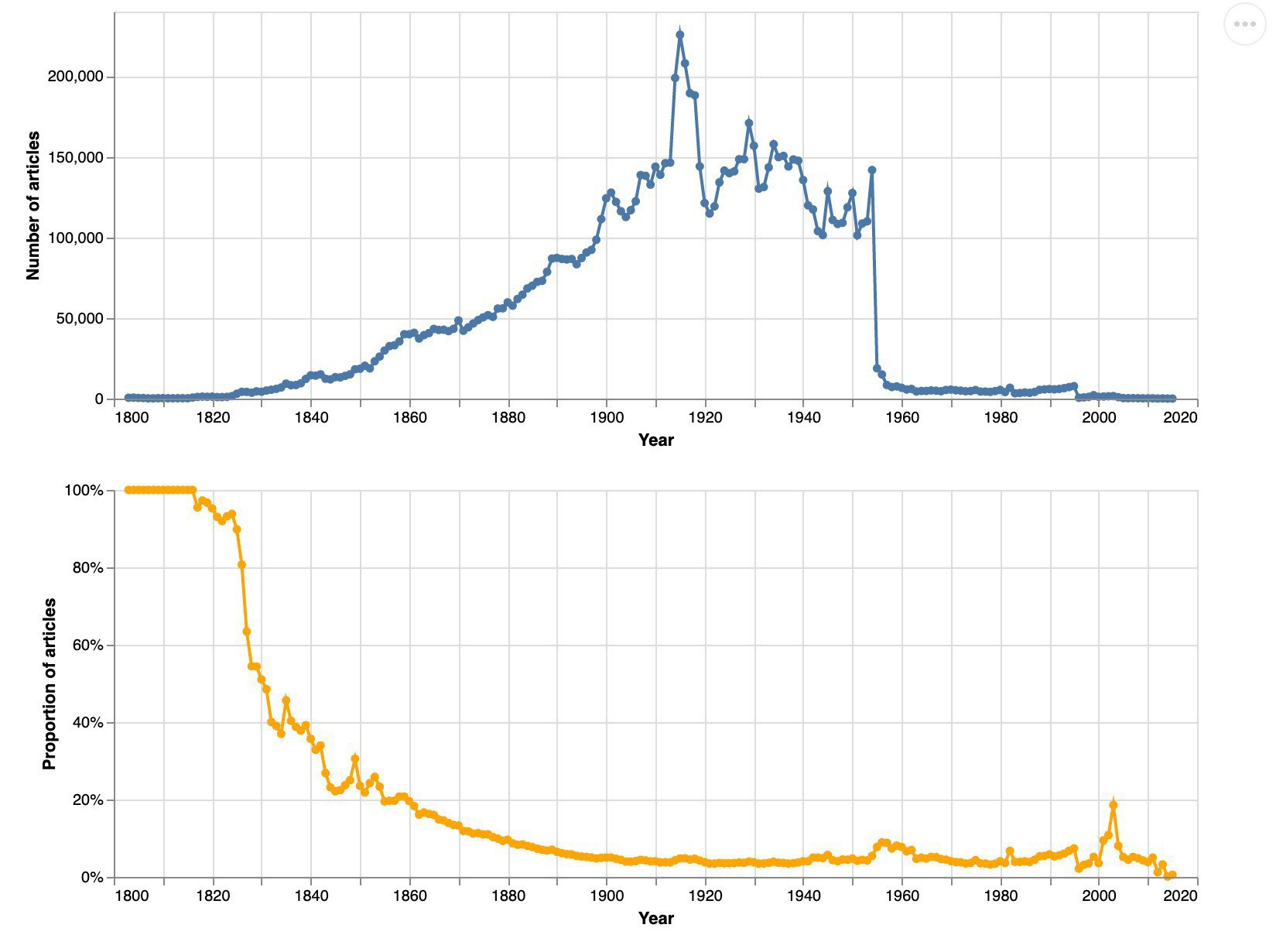
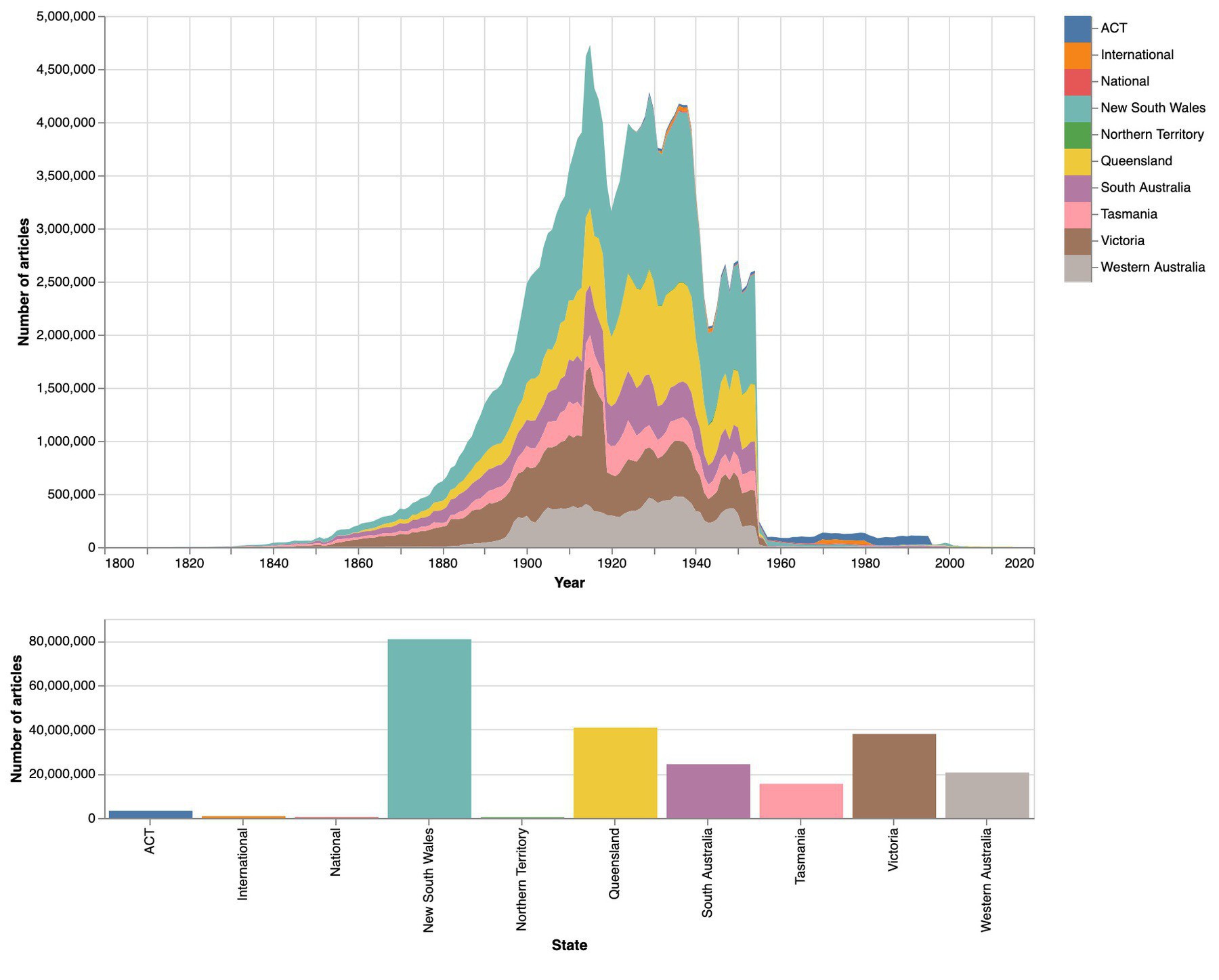
The second new notebook looks at @TroveAustralia’s newspapers as a whole, visualising both by time and by state. Along the way it looks at favourites such as the WWI effect and the copyright cliff of death. #dhhacks
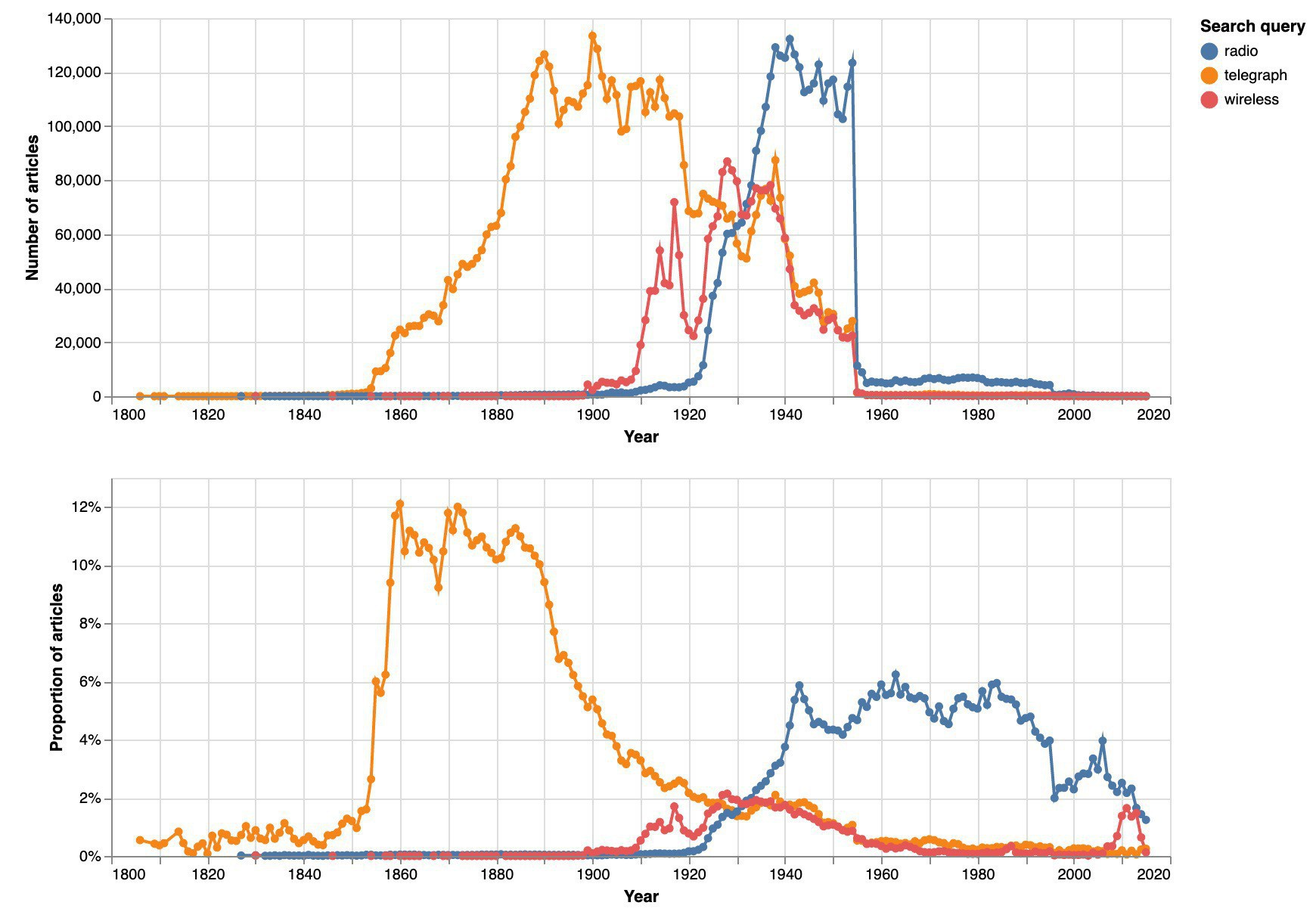
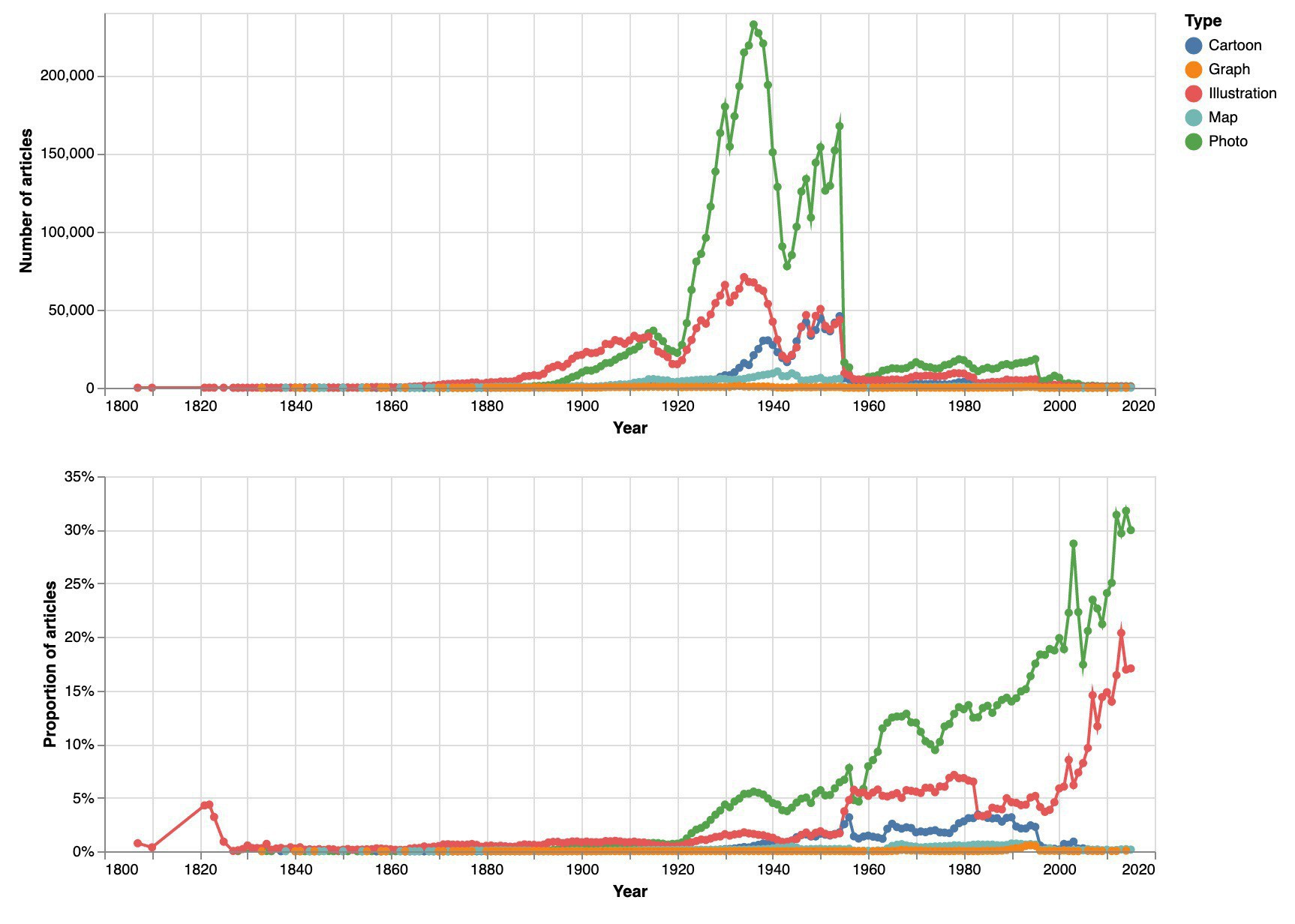
Some brand new Jupyter notebooks for those interested in #ozhist & digital exploration of @TroveAustralia’s newspapers. The first walks through different ways of visualising newspaper searches over time. #dhhacks
I’ve updated the @invisibleaus data repository with latest transcriptions/markings from White Australia Policy records in @naagovau.
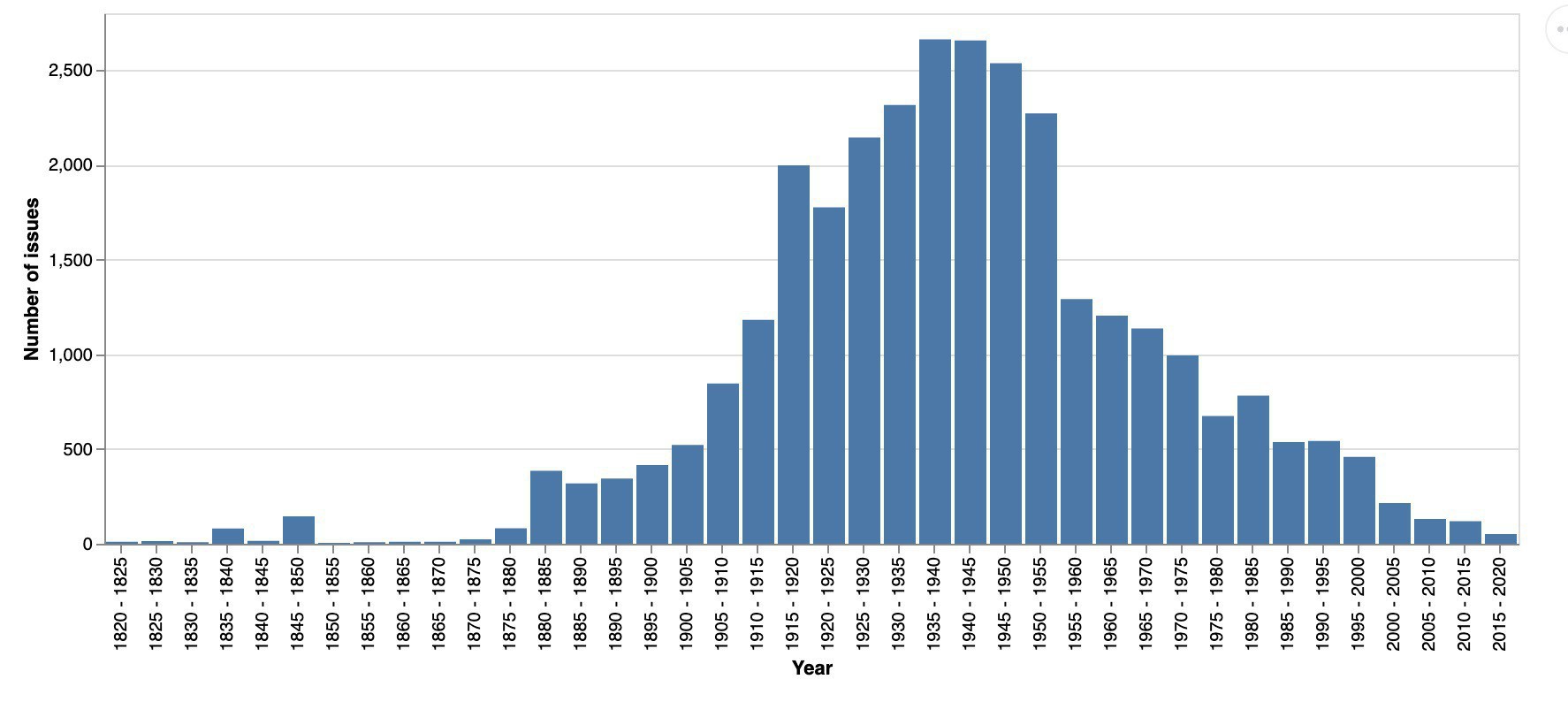
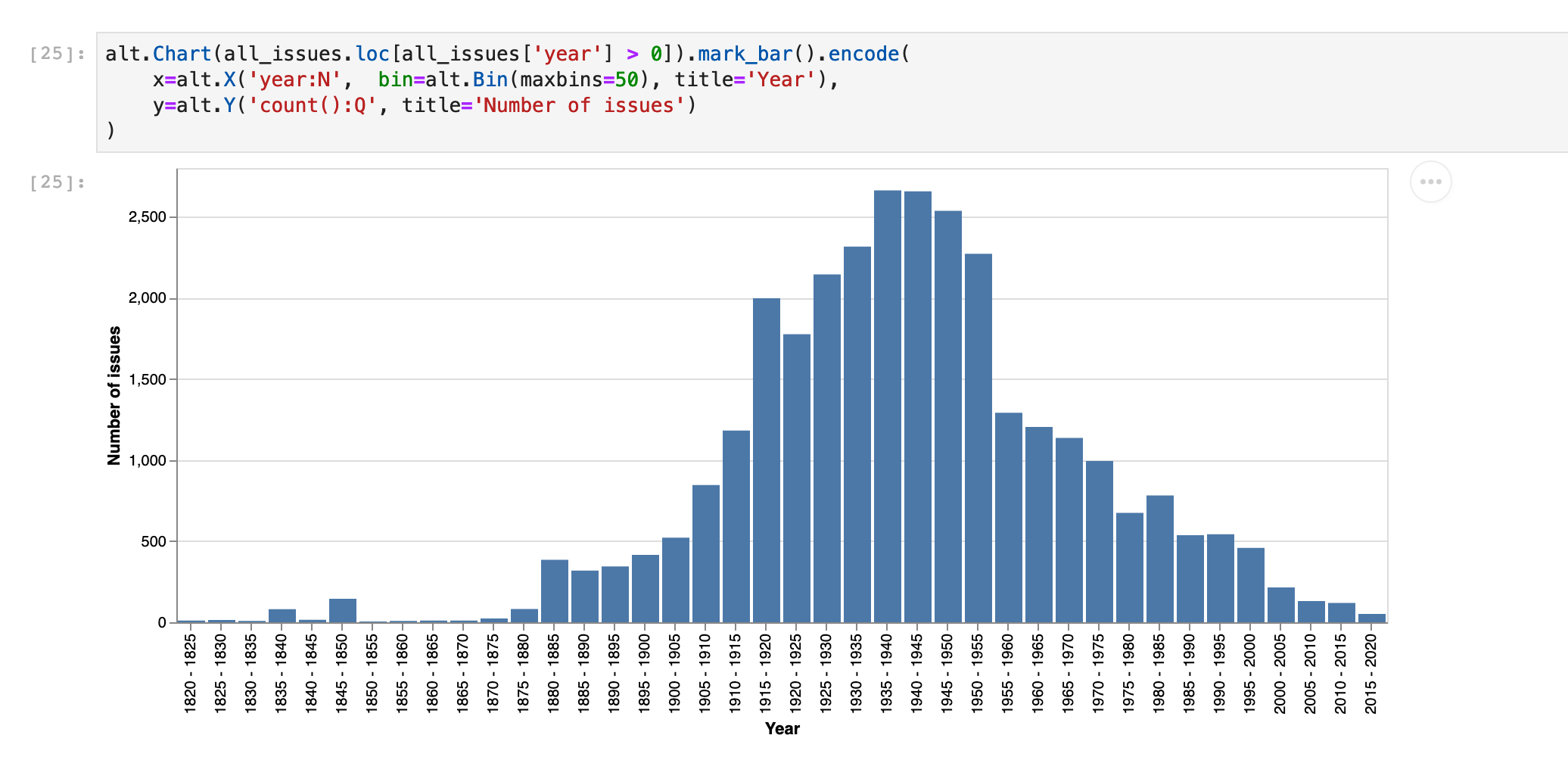
According to my last harvest, @TroveAustralia’s digitised journals comprise 31,216 separate issues. Here are the number of issues by year.
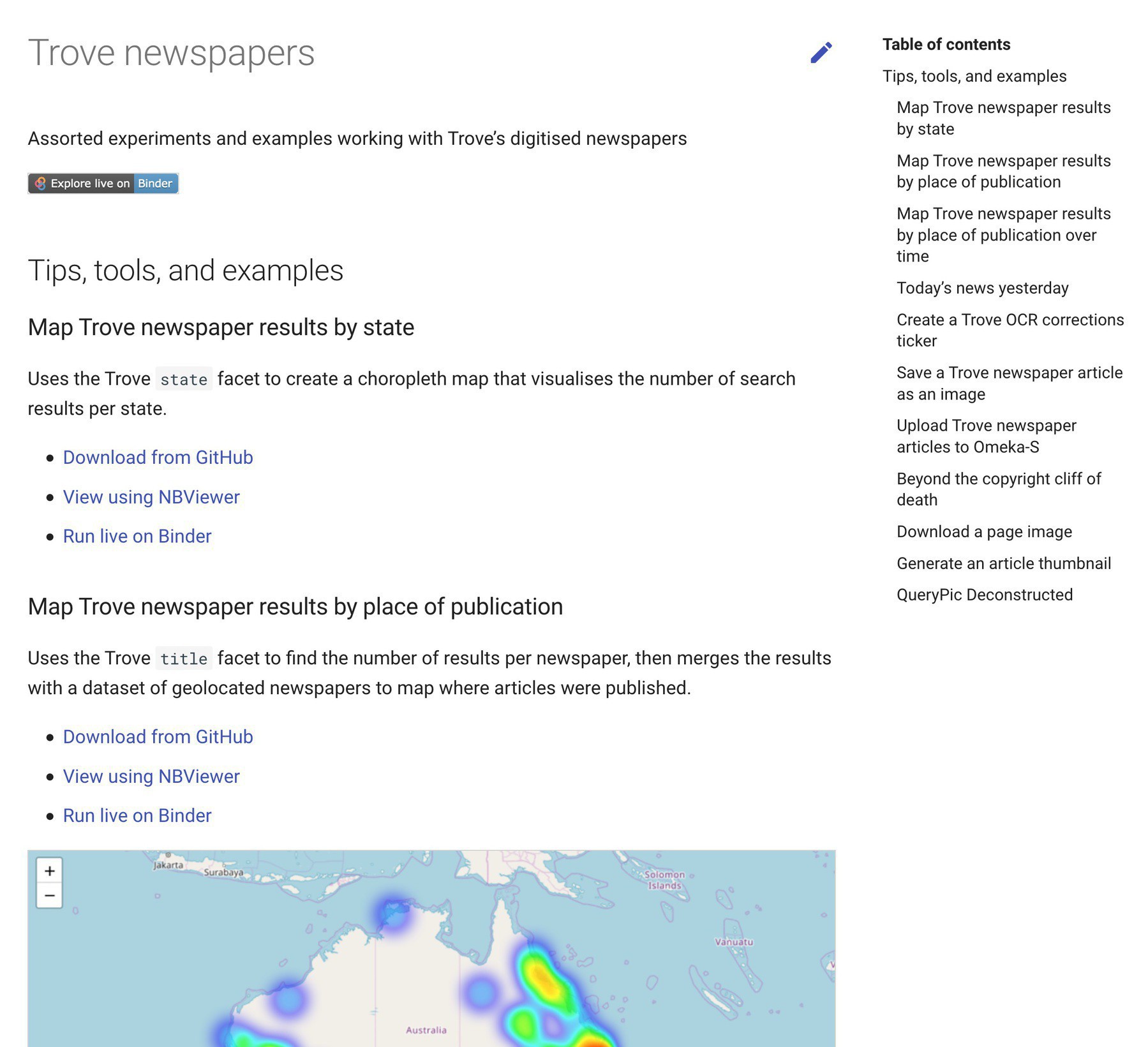
Updates to the Trove newspapers section of GLAM Workbench – adding links to app-ified versions of some notebooks, & direct links to @mybinderteam for everything. If you work with @TroveAustralia newspapers you might find it useful.
NSW State Archives publishes a number of detailed indexes containing data manually extracted from their records. These provide additional entry points to the records, such as a person’s name, or a place. But they also provide useful data for analysis. However, to explore the index data we need to get it out of the web interface and into a form that can be easily downloaded and manipulated.
I’ve created a series of Jupyter notebooks to harvest the all the indexes and save the data in a series of CSV-formatted files.
Visualising CV-detected column widths across 100 volumes (30,000+ pages) of Sydney Stock Exchange records from @TheANUArchives…
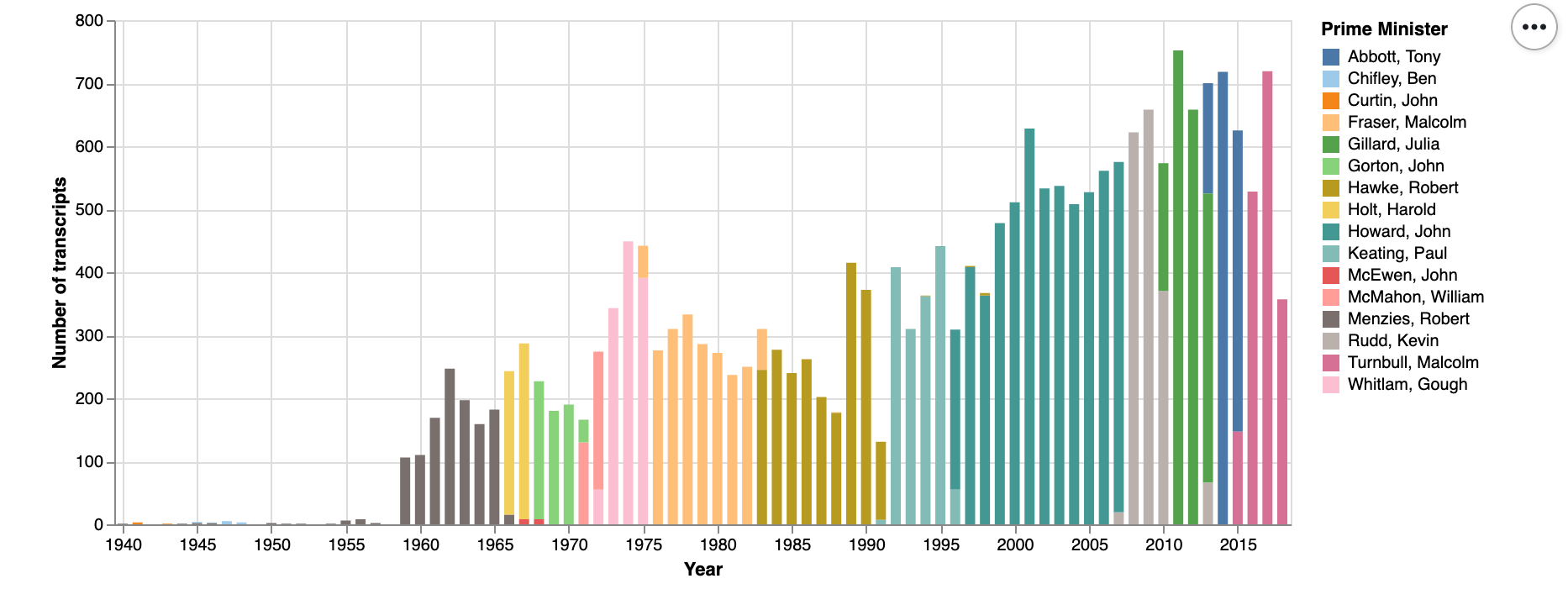
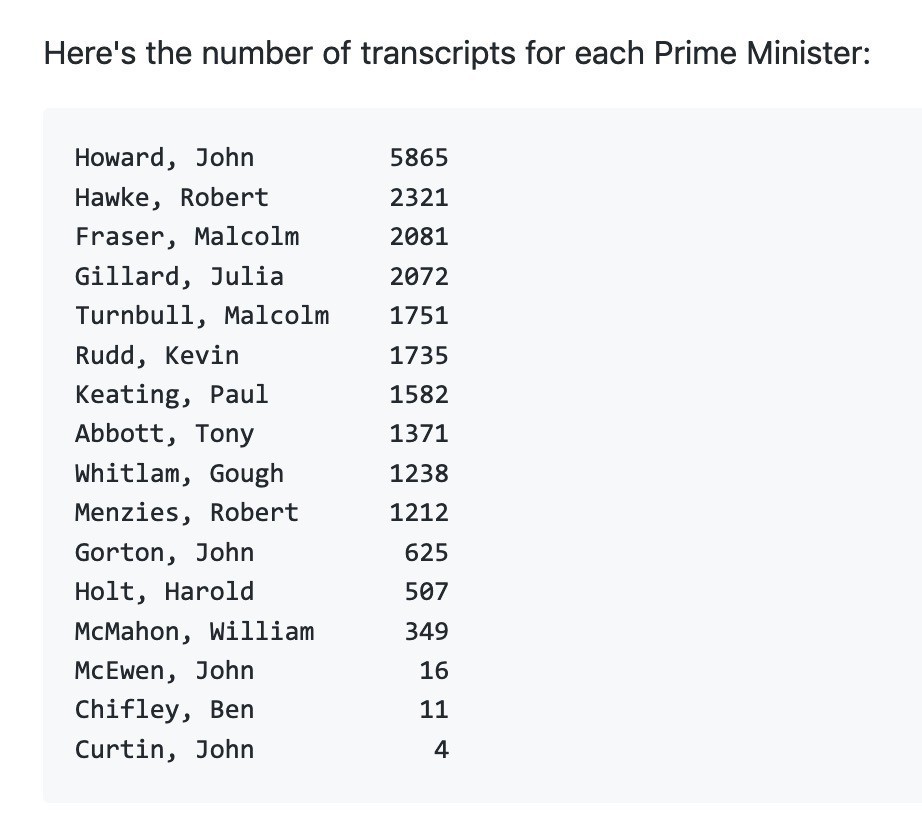
New in GLAM Workbench! Notebooks to harvest, index, analyse, and aggregate transcripts of speeches & interviews by Australian prime ministers. Plus links to harvested data and aggregated files. #dhhacks
I’ve updated my harvest of the PM Transcripts site — 22,814 XML files with transcripts of speeches, interviews, media releases etc by Australian Prime Ministers. Now with added @TurnbullMalcolm…
Repository includes an index of the files, and aggregations by PM. #dhhacks
Reorganising things a little at GLAM Workbench. @statelibrarynsw gets its own section. Hansard and @datagovau GLAM datasets now under ‘Australian government’. Making some space for further additions…
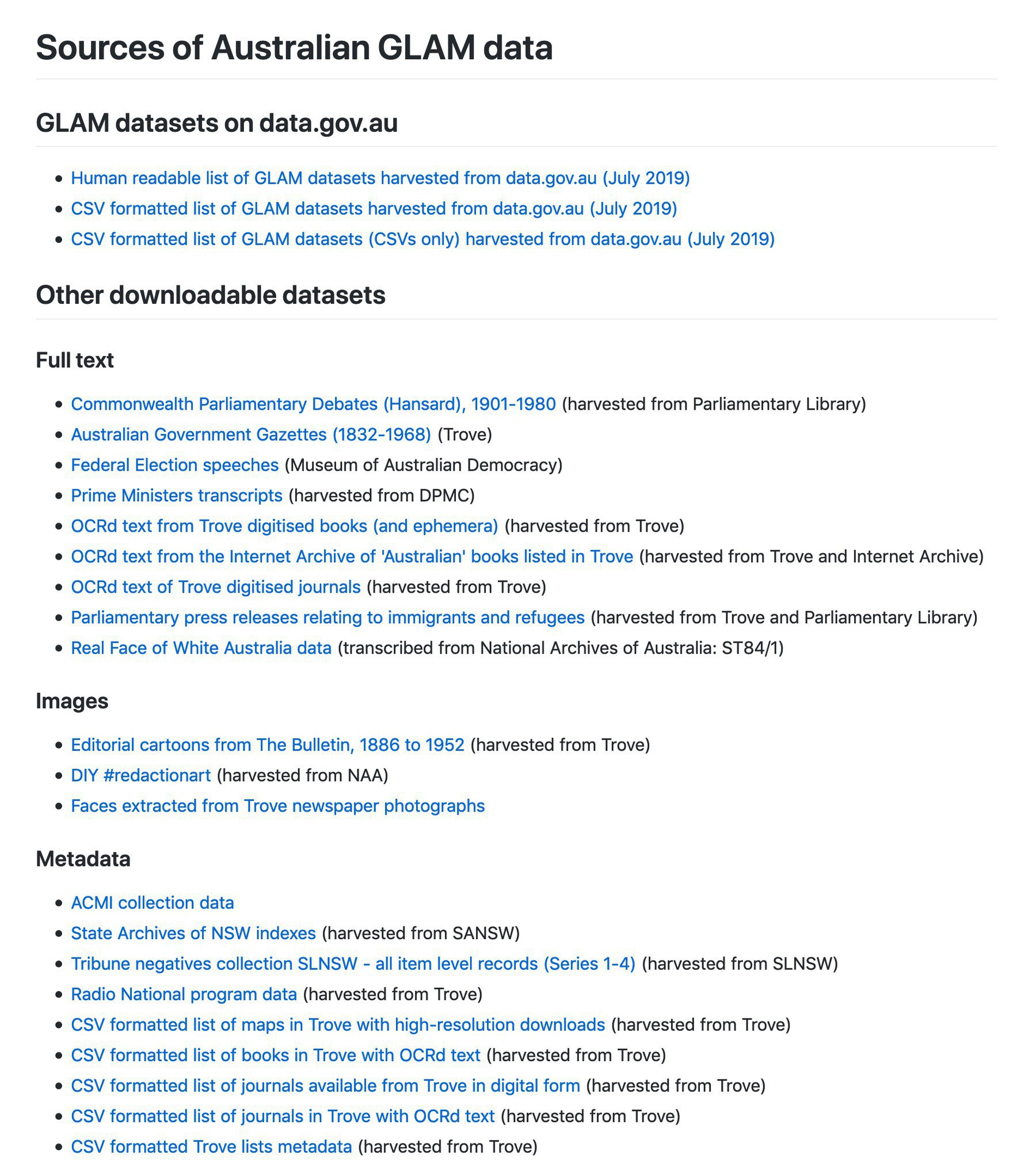
What’s that? You want MORE GLAM data? Well, I’ve started a list of sources for Australian GLAM data. Metadata, full text, images & more. Contributions welcome! #dhhacks