So in case you’re wondering, the @qsarchives ‘Naturalisations 1851 to 1904’ index actually collates names from these 10 series (and therefore has multiple entries for a single person).
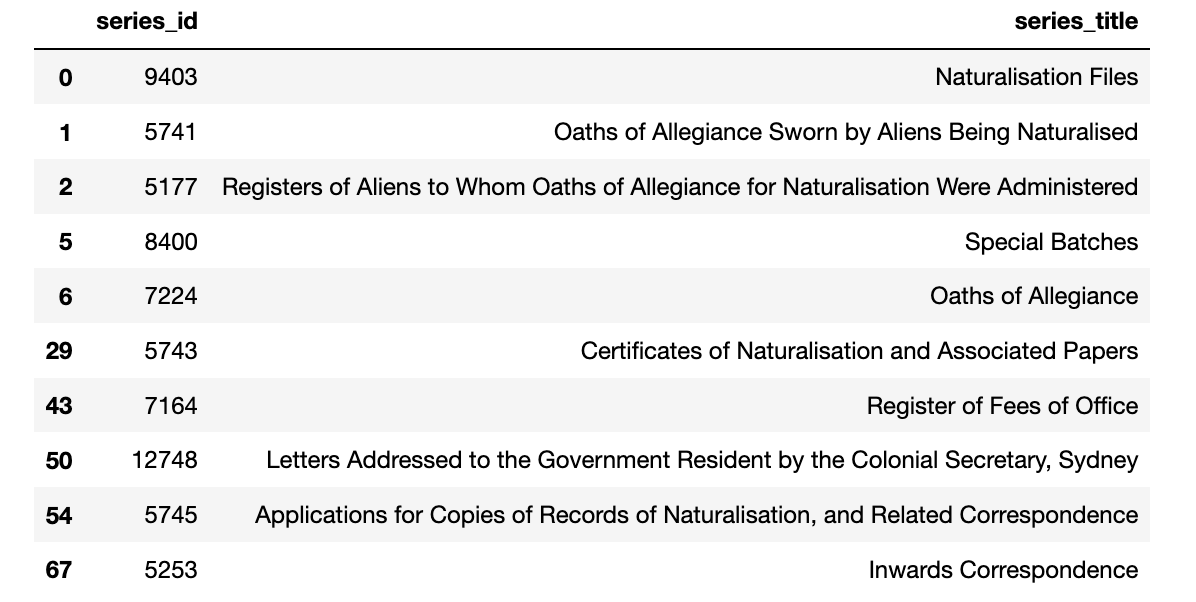
So in case you’re wondering, the @qsarchives ‘Naturalisations 1851 to 1904’ index actually collates names from these 10 series (and therefore has multiple entries for a single person).
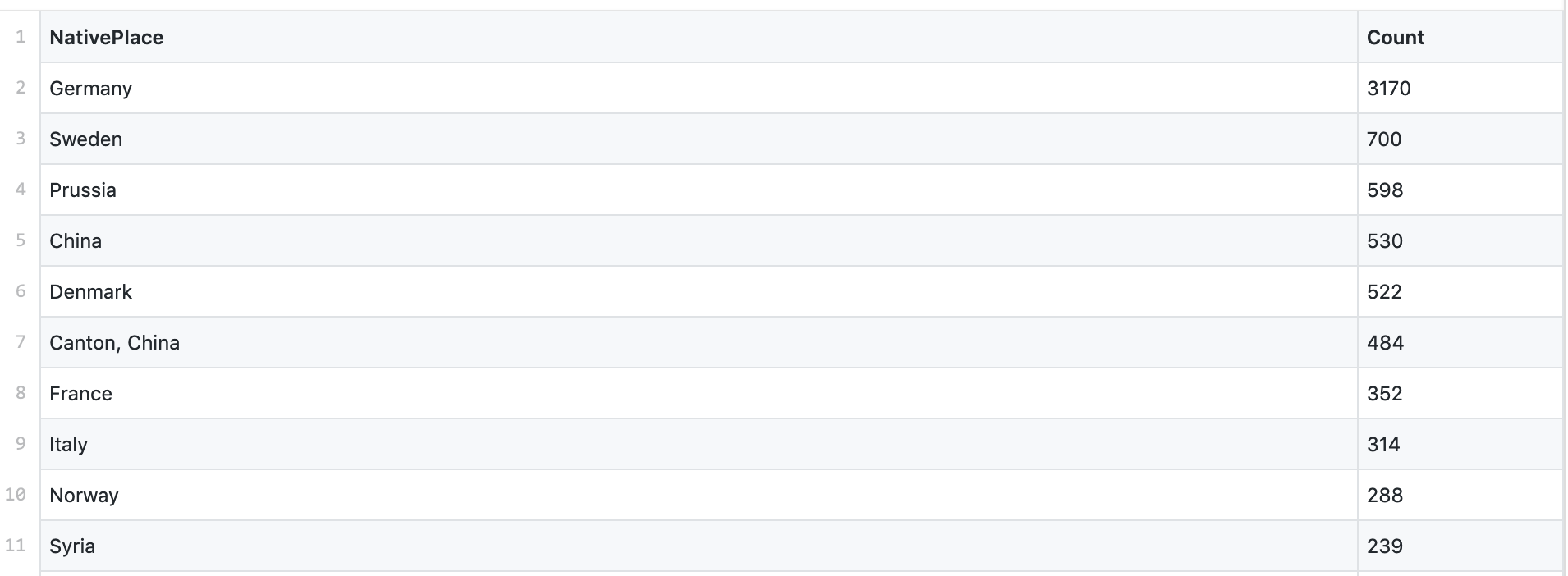
Whoops. Here’s the actual full list of countries of origin from the @nswarchives NSW naturalisations data (and not just the screenshot!).
Here’s the full list of countries of origin from the NSW naturalisations data, 1834-1903.
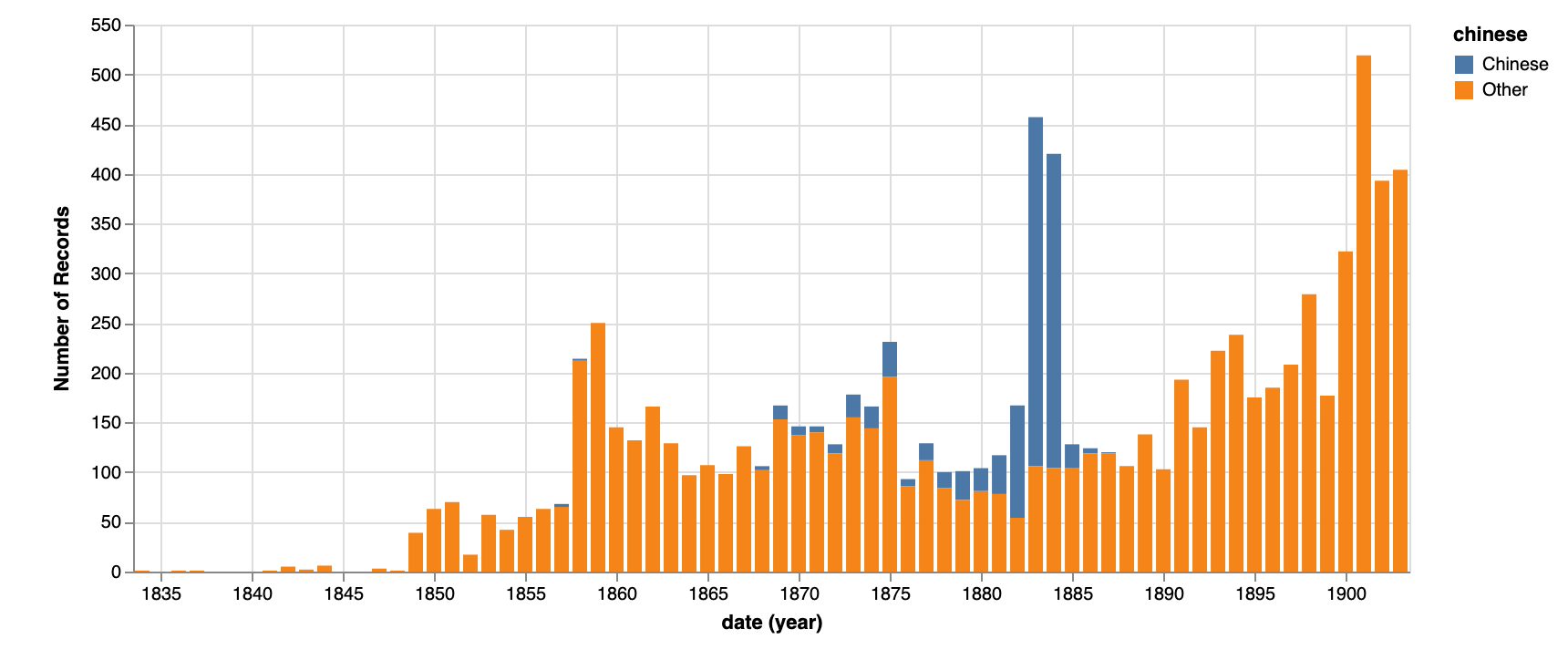
NSW naturalisations 1834 to 1903. The sudden rise in Chinese naturalisations followed the introduction of the poll tax. More restrictions soon followed… Using (deduped) naturalisations data from @nswarchives.
Suggestions of new topics and collections for my GLAM workbench are welcome!
Here’s an example dataset harvested from Library and Archives Canada’s naturalisation database. It’s all the people with ‘China’ as their country of origin, supplemented with wives and children (who are not included in a country search).
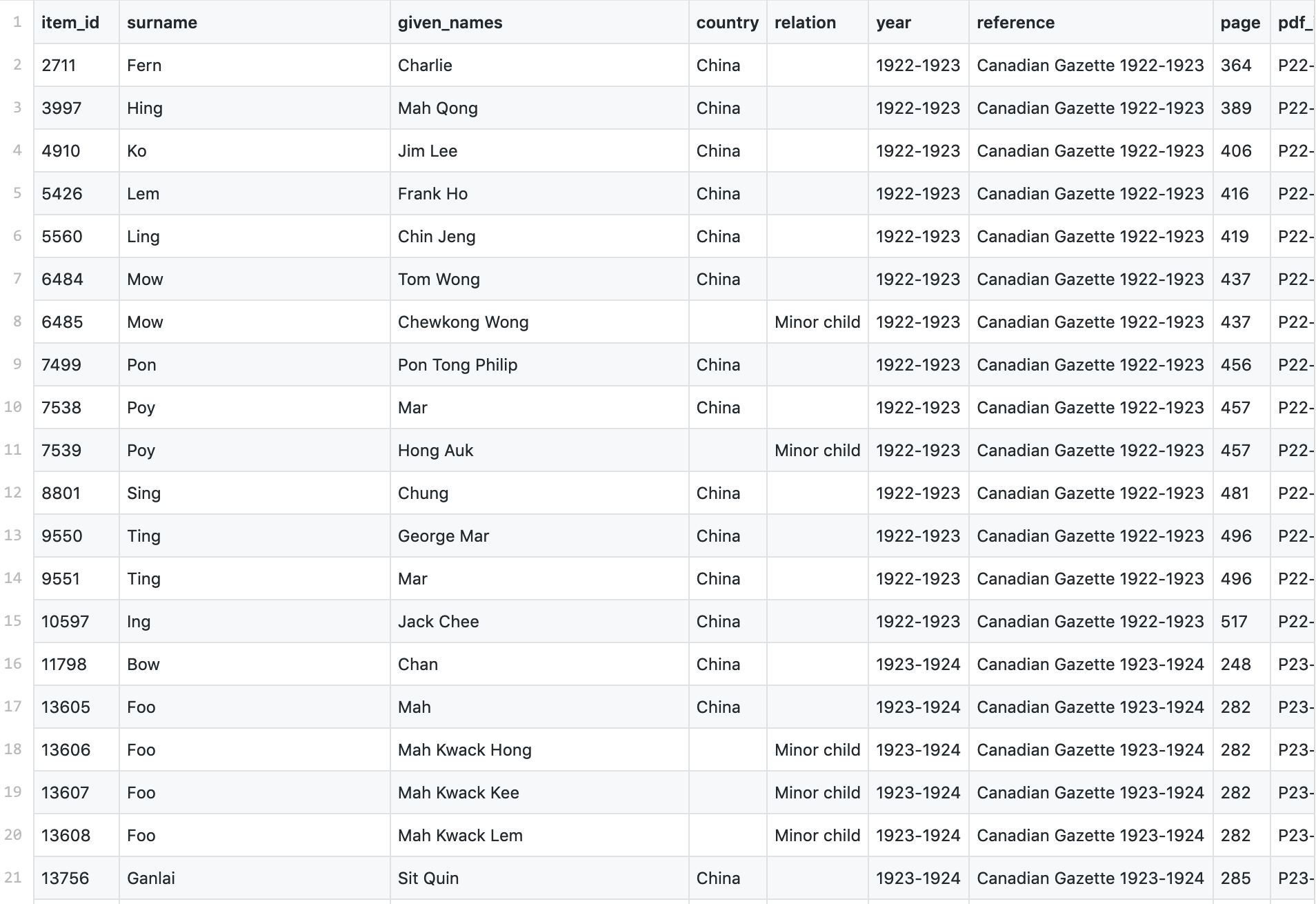
I’ve added a section for Library and Archives Canada to my GLAM workbench. The first notebook extracts records of people from a specific country from their naturalisations database and saves the results as a CSV file. #dhhacks
Current status — extracting data from Library and Archives Canada’s 1915-1946 naturalisation database. Coming soon to my GLAM Workbench…
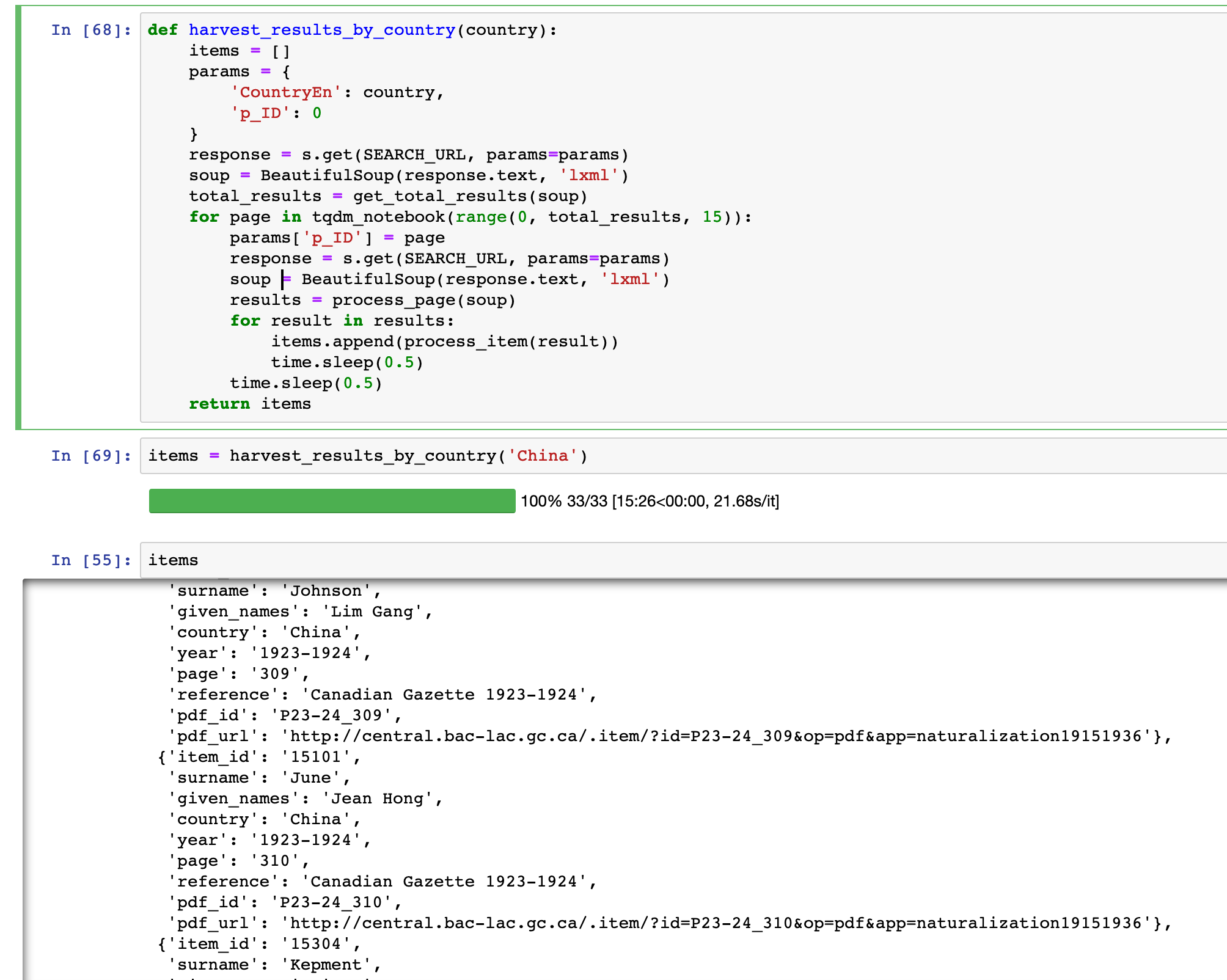
The full text of ‘Who belongs? Reading identity, ownership, and legitimacy’, my talk for #text2data last week, is now online. Includes slides, code, data & more… #dhhacks
My talk for #text2data at the National Library of Sweden looks at occurence of the words ‘aliens’ & ‘immigrants’ in @TroveAustralia newspapers, The Bulletin, & Hansard. The slides, code & data are online. #dhhacks
Back to school report — what I did on my holidays…
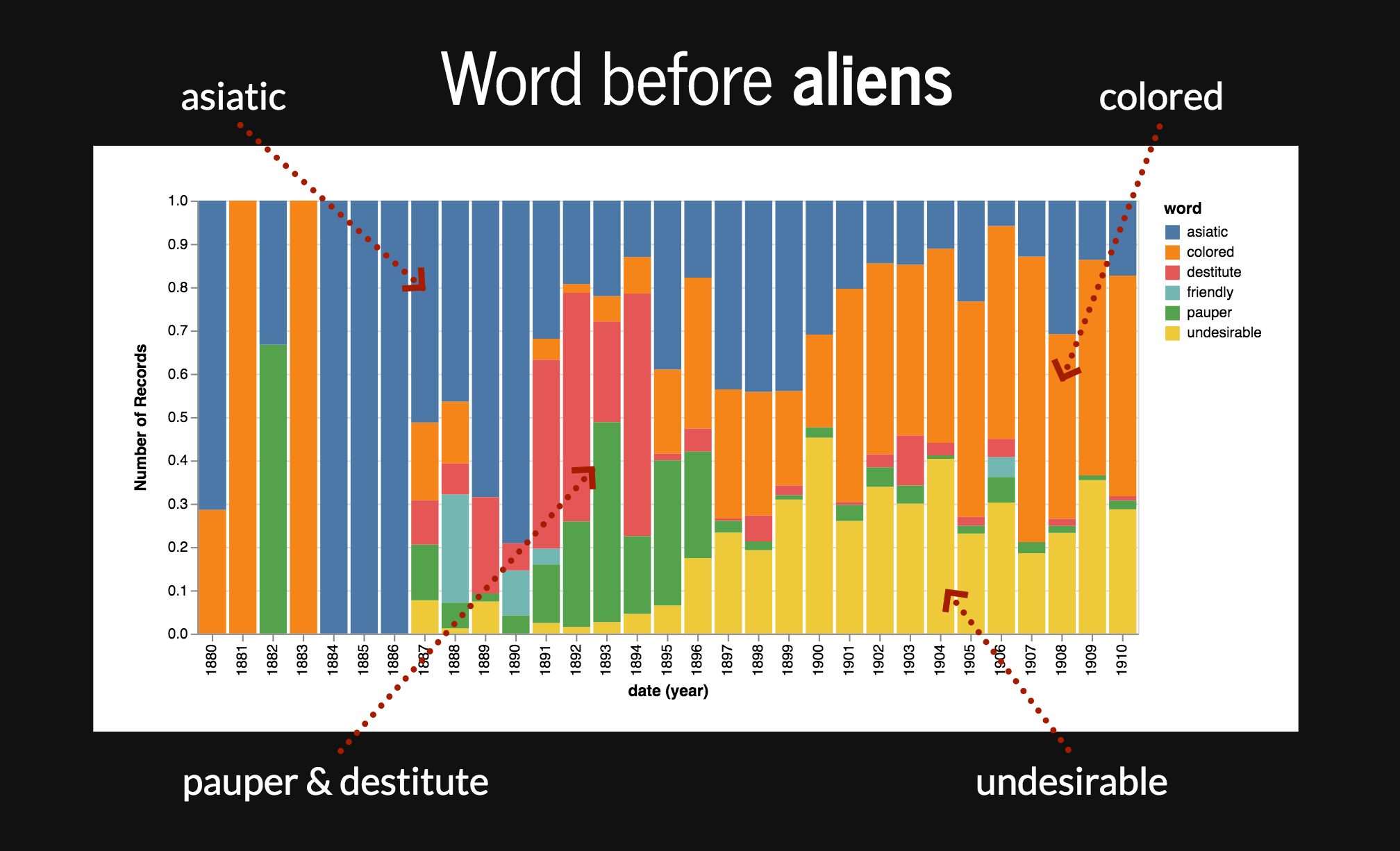
Another slide for Sweden — this one comparing words appearing before ‘aliens’ in The Bulletin and Commonwealth Hansard (1901-1980).

Working on my slides for From Text to Data in Stockholm this week…
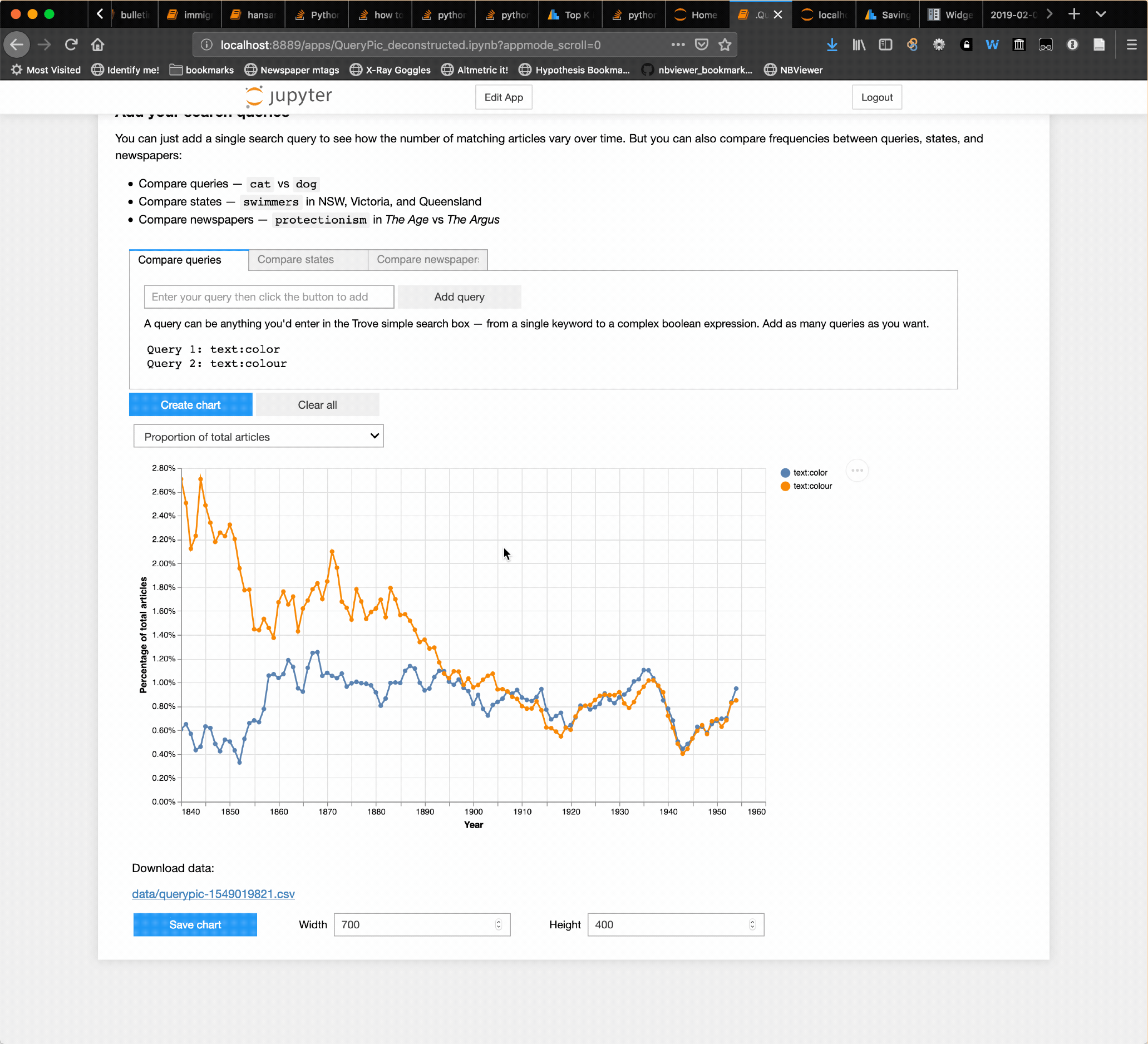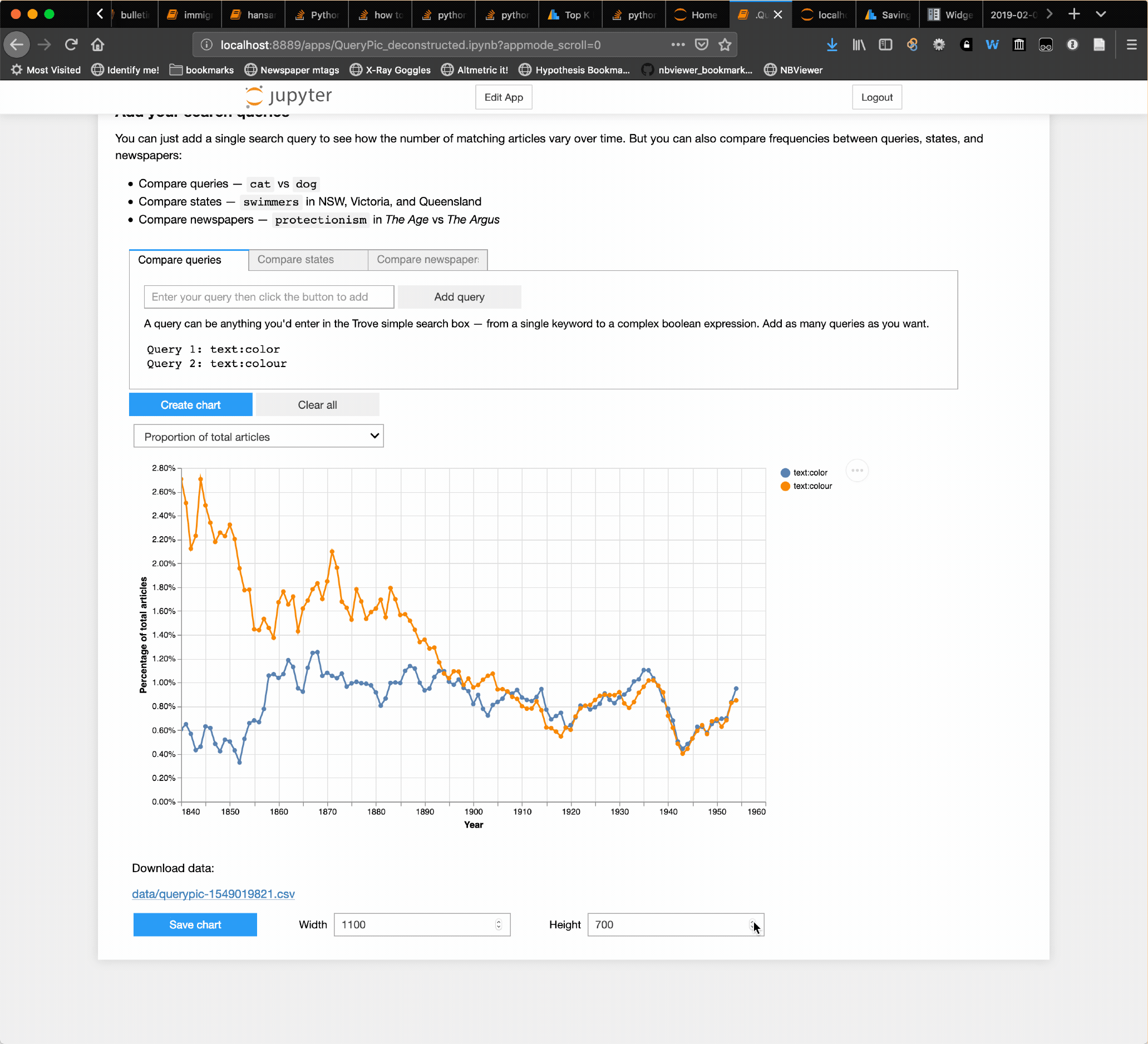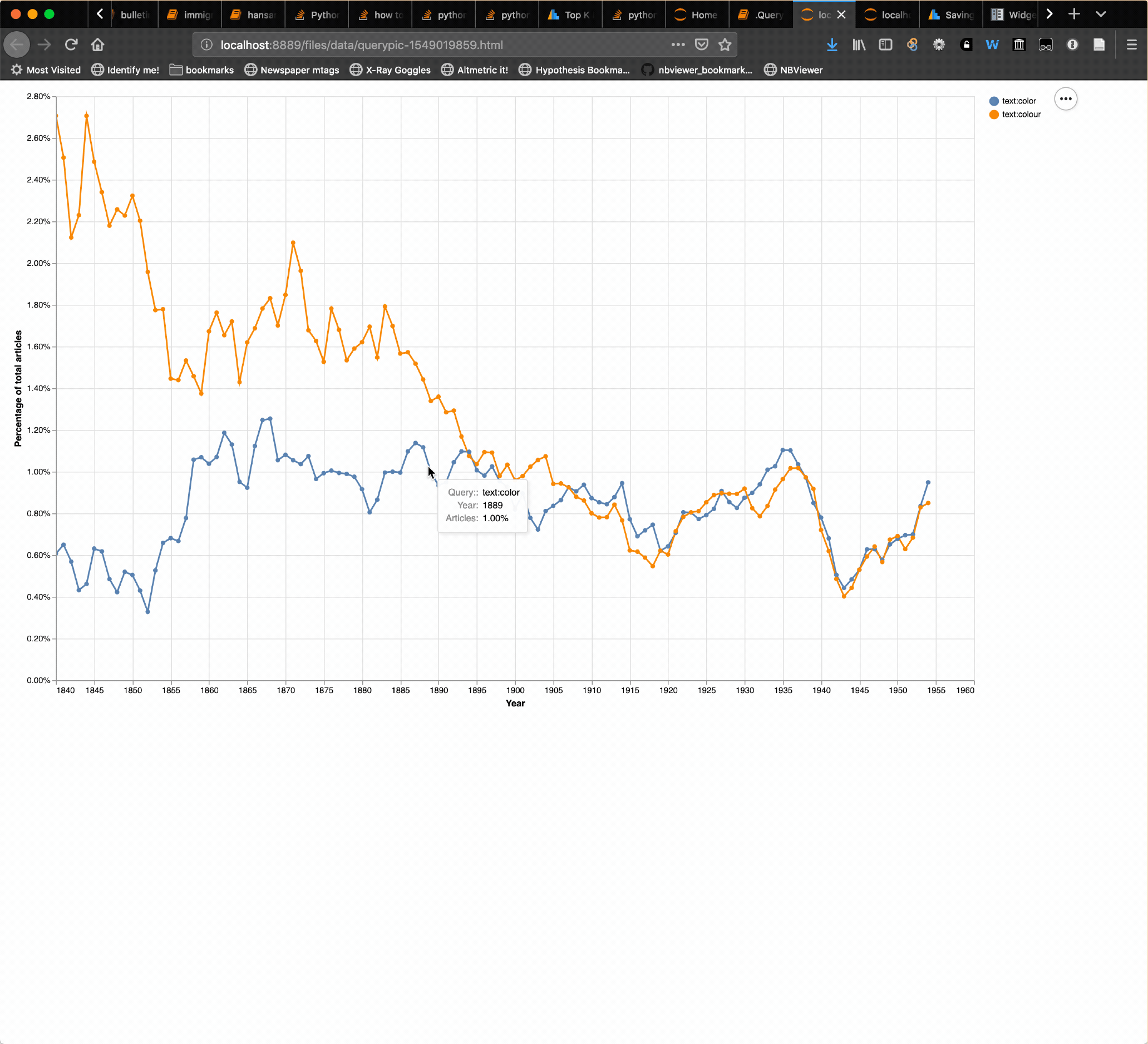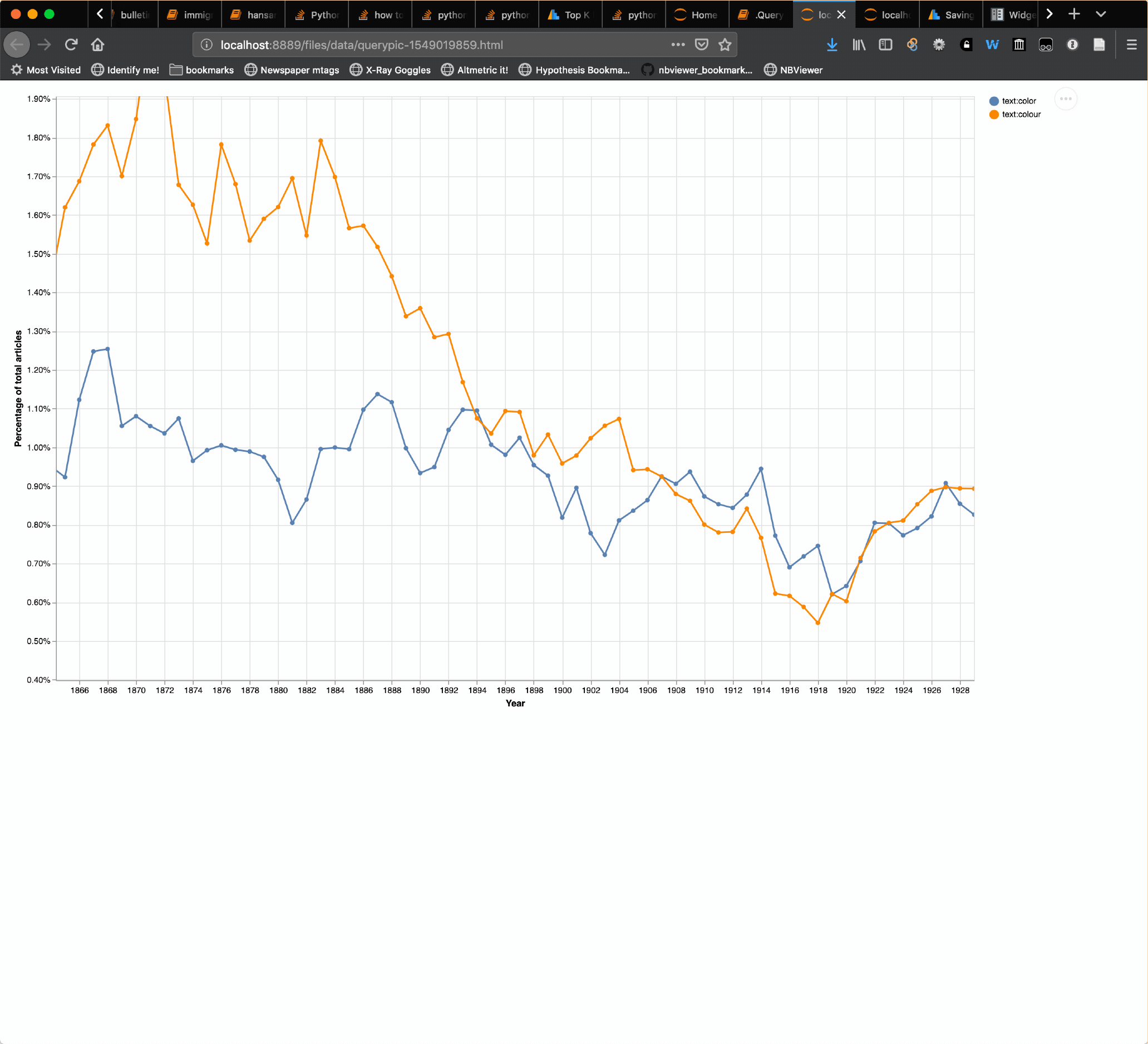
I’ve added a ‘save chart’ option to the QueryPic app in my GLAM Workbench. Visualise your searches in @TroveAustralia newspapers, then save the results as HTML for easy download. #dhhacks
Pleased and proud to see the chapter @baibi & I wrote on the Real Face of White Australia now published as part of an awesome collection. Buy now or read the CC-BY version online!

In a bit over a week I’ll be heading to Stockholm for the ‘From text to data’ conference. Preparing myself for the 40 degree temperature difference…

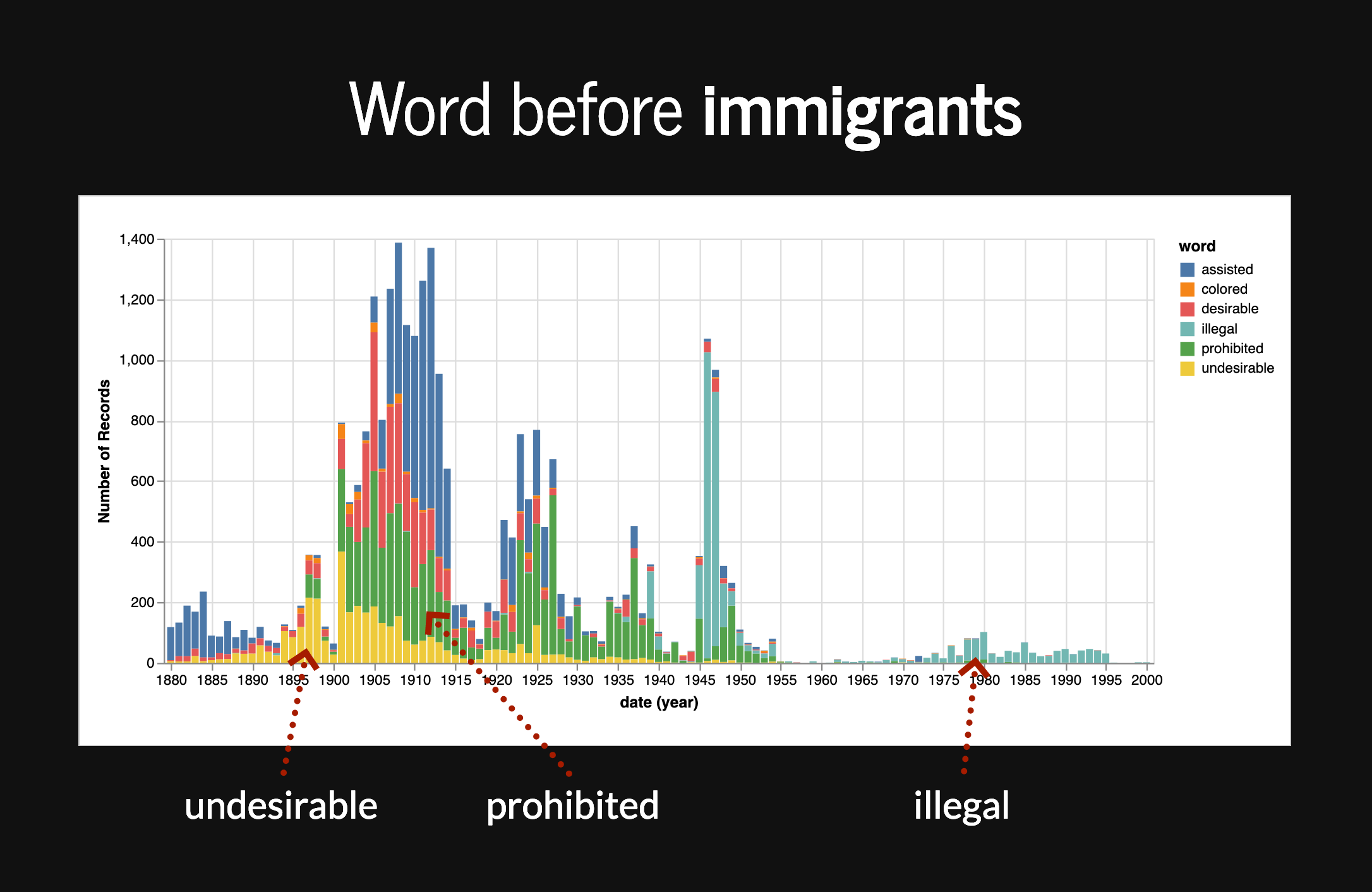
I’m giving a talk in a week or so (eep!) that looks at some of the changing contexts in which the word ‘aliens’ has been used in Australia. I thought, by way of comparison, it would be useful to do the same for ‘immigrants’. While I was playing around with the data last night, I came across something interesting, so here’s a sneak preview… Getting the data Using my TroveHarvester I downloaded the full text of all newspaper articles in Trove that included the word ‘immigrants’.
In case you’re wondering, it took about 13 hours to download the metadata and full text of more than 2,000,000 @TroveAustralia articles including the word ‘Chinese’ using my Trove Newspaper Harvester. You can try it here.
Ok, so let’s see how I go harvesting 2 million newspaper articles from @TroveAustralia conatining the word ‘Chinese’…
30,000+ occurences of the word ‘Chinese’ in the OCRd full text of The Bulletin, 1880-1968.

{kind=link}