Some Archives Week goodies
It’s International Archives Week and I’m feeling a bit crook after being double-vaxxed yesterday, so instead of doing something productive, I’m just going to make a list of potentially handy archives-related resources from the Wonderful World of Wragge(TM).
The theme of Archives Week is #ArchivesAreAccessible, which you’d have to regard as rather aspirational given the various ways access is limited by law, policy, practice, technology, and history. But what the heck, discussions about the meaning of access are always welcome. It’s also a little jarring to see the #ArchivesAreAccessible theme being promoted by the National Archives of Australia just a few weeks after they implemented new restrictions that make it impossible to get machine-readable data out of their online database, RecordSearch. But I’m trying to move on, so…
Zotero
All Australian archives users should have Zotero installed. Through the magic of user-contributed ‘translators’, Zotero can capture structured data and digitised images from a variety of collections, including:
- National Archives of Australia
- PROV
- Queensland State Archives
- State Library and Archives of Tasmania
- State Records Office of WA
The first four are my work, so let me know if you have any suggestions or problems.
Indexes to records
Archives are well represented in the GLAM Workbench’s list of GLAM datasets shared through government open data portals. Many of these datasets are indexes that link records to people and places. They’re openly licensed and under used!
NSW State Archives has also compiled a lot of indexes. These aren’t shared through a portal, but you can harvest them from their website. To save you the effort, I’ve created a repository of the harvested indexes.
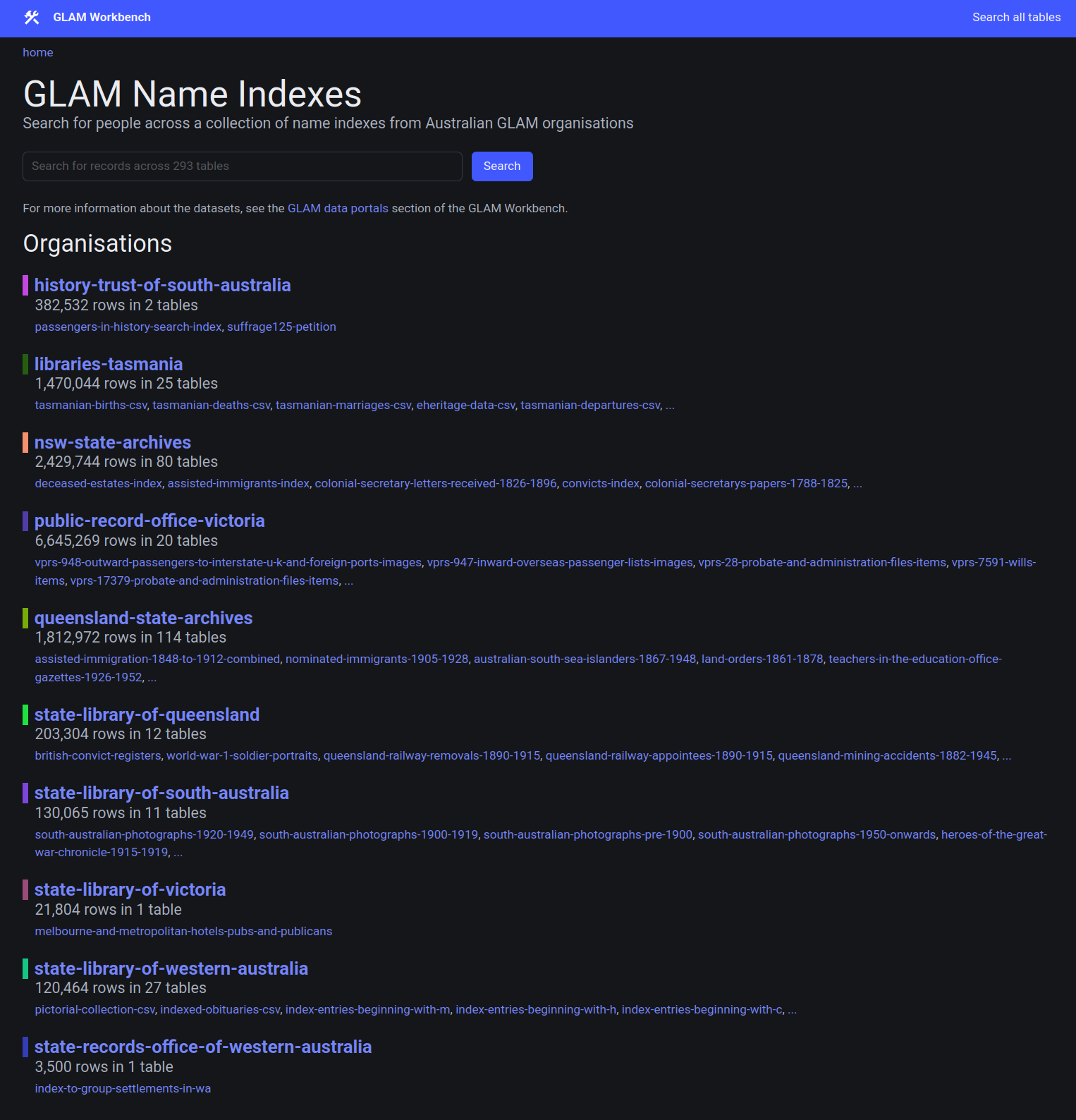
I’ve pulled many of these sources together to build a mega database of name indexes that lets you search for people across millions (yes millions) of records. As well as the sources described above, it also includes people-related records from the Public Record Office Victoria’s API. All together, the GLAM Name Index Search contains almost 13 million records in 293 datasets from 10 GLAM organisations. And unlike the commercial genealogical databases, it’s free! (If only Australian libraries and archives would link to it from their family history guides…)
Other datasets
Before my scrapers were scuppered by the NAA, I managed to compile a few datasets. Much of this data documents the way RecordSearch itself has changed, and while it might not be of use to researchers seeking particular records, it could help future researchers who are trying to understand the impact of online collections on the practice of history. This includes:
- Summary data about all series in RecordSearch – a CSV file containing basic descriptive information about all the series currently registered on RecordSearch as well as the total number of items described, digitised, and in each access category. Harvests from May 2021 and April 2022 are currently available, and I’ll soon be adding May 2025.
- Files digitised by the National Archives of Australia since 2021 – annual compilations of data harvested from RecordSearch’s list of recently digitised files. (The automated weekly harvests are now dead.)
- Records held by the National Archives of Australia with the access status of ‘closed’ – a whole decade of annual harvests of records held by the NAA that have the access status of ‘closed’ (withheld from public access). The harvests were run on or about 1 January each year from 2016 to 2025. The aim in saving this data is to enable long-term analysis of the NAA’s access examination process.
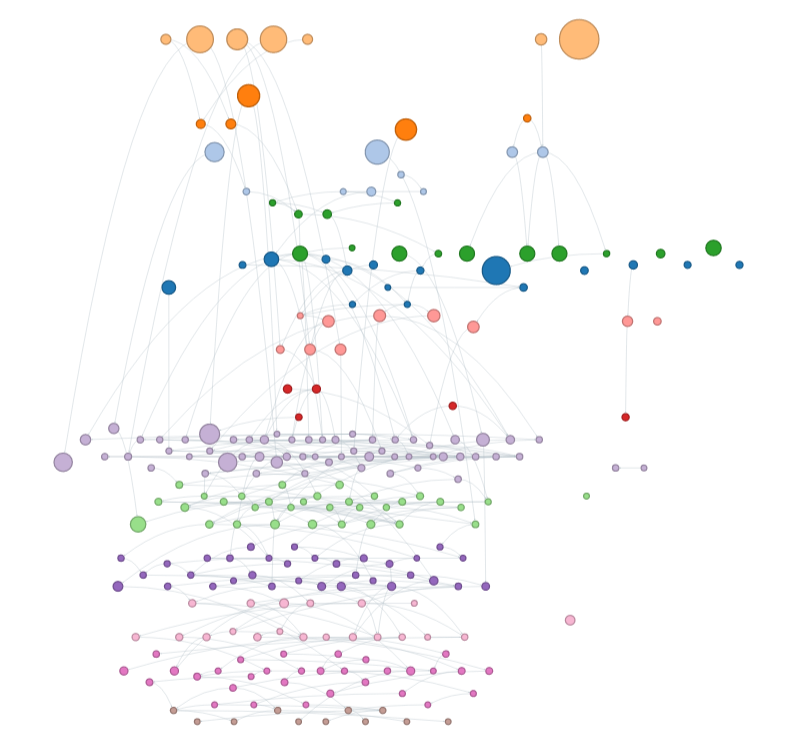
Thanks to support from Wikimedia Australia, I’ve also added information about Australian government agencies from RecordSearch to WikiData. As a result you can get a list of Australian government departments since Federation using this Wikidata query. I’ve used the data to build this interactive visualisation of the relationships between government departments. There’s some more examples in the Wikidata section of the GLAM Workbench.
Also from the NAA is my collection of #redactionart found in ASIO surveillance files.
As part of the Real Face of White Australia project, we’ve been transcribing records created by the administration of the White Australia Policy, now held by the NAA. Some of the results are available in this data repository. (Note to self – I need to update this with the latest data!)
The ANU Archives section of the GLAM Workbench includes some datasets extracted from the Sydney Stock exchange stock and share lists. (Just noticed some CloudStor links in there that I need to fix…)
Public Record Office Victoria
PROV gets it’s own section because, as far as I know, they’re the only Australian archives with a functioning public API. (Brief moment of silence to remember the APIs that have come and gone over the years…).
There’s now a PROV section of the GLAM Workbench, that includes a ‘getting started’ notebook to document the basic functionality of the API. There’s some more information in this blog post.
I’ve also used the PROV API to create an automated data dashboard that provides an overview of their collection. It’s updated every Sunday.
Other things
RecordSearch users will understand the frustration of trying to share a url to a record, only to get an annoying error. There are a few ways around this (Zotero saves persistent links to things you save), but for a quick fix I created a simple tool to create persistent links in RecordSearch.
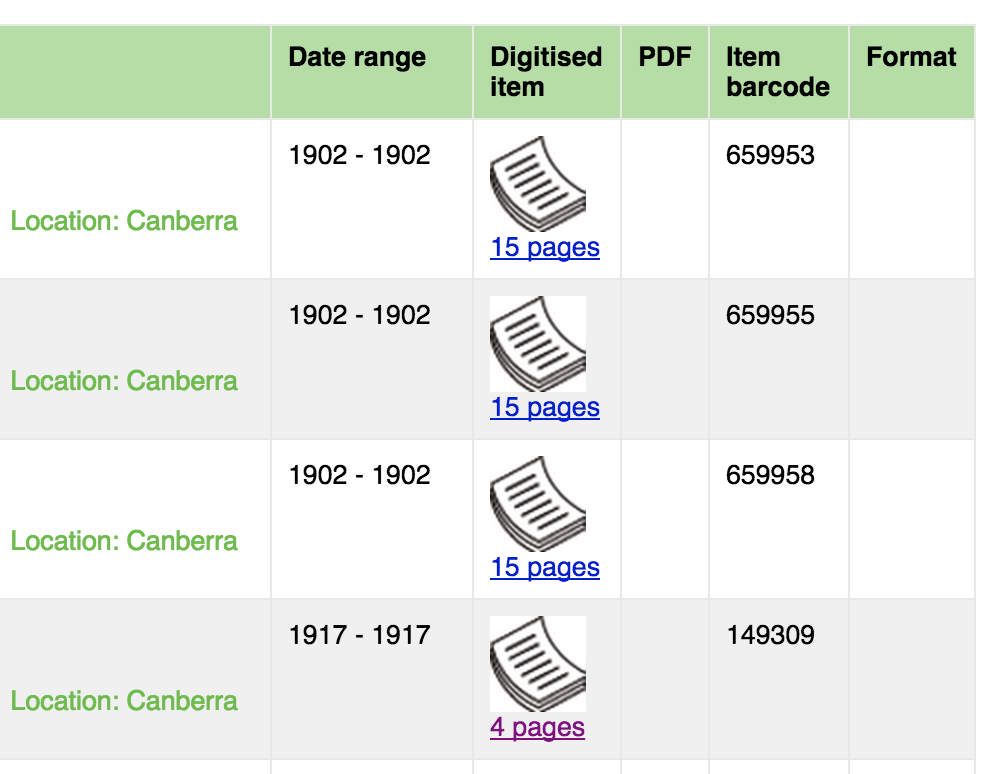
If you’re comfortable with a little browser hacking, you can also install this handy RecordSearch userscript (scroll to the bottom for installation instructions). It improves the functionality of RecordSearch in a few different ways, such as by indicating the number of pages in a digitised file.
Any ideas?
If you have any ideas for additional resources or datasets, or you’re having problems with an online collection, feel free to drop a note in the GLAM Workbench repository.