A brief and biased history of Trove Twitter bots
The socials recently alerted me to an interesting article by Dominique Carlon, Jean Burgess, and Kateryna Kasianenko on the history of community-created Twitter bots. The article explores bot-making within the context of Twitter’s rise and fall, and provides a handy taxonomy of bot species. However, it doesn’t include any Australian bots amidst the examples. That’s a bit disappointing, as I remember the bot-building years as a time of great fun and creativity. My own contribution to the world of Twitter bots was mainly focused on Trove (what a surprise!), so I thought I might as well jot down a few incomplete and biased notes about the history of Trove Twitter bots.
Trove tweeting trends
It just so happens that I recently packaged up some data about Trove links shared on Twitter. Using this data, we can get a broad perspective on the activity of Trove Twitter bots between 2009 and 2020. The identification of bots is based on the Trove bots list I maintained on Twitter, so it’s possible I’ve missed some.
In total, 43 bots posted 318,767 tweets containing 270,474 unique Trove urls between June 2013 and December 2020.
Here’s a chart showing the total number of links to Trove shared by Twitter bots each year.
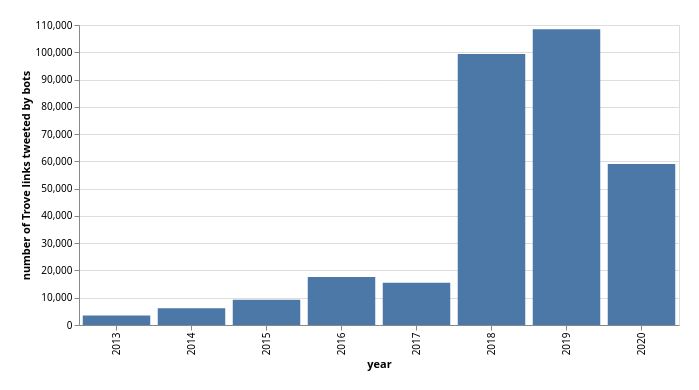
Most of the bots shared digitised newspaper articles, but some shared works from other Trove zones. This chart breaks the links down by the type of resource (‘article’ equals newspaper article).
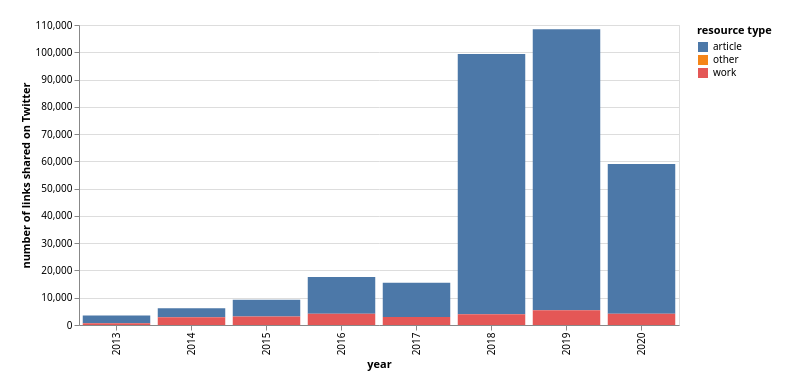
And one final chart showing the number of active bots per year.
| year | active bots |
|---|---|
| 2013 | 4 |
| 2014 | 4 |
| 2015 | 6 |
| 2016 | 8 |
| 2017 | 12 |
| 2018 | 34 |
| 2019 | 38 |
| 2020 | 22 |
From the data above you can see that bot activity grew slowly between 2013 and 2017, before taking off dramatically in 2018. The peak year for Trove bots was 2019, when 38 individual bots shared more than 100,000 links to Trove. But a mass extinction event in 2020 almost halved the number of active bots. So what happened?
Build-a-bot begins
In June 2013, inspired by bot creators like Mark Sample, I hooked the Trove API up to Twitter to see what would happen when GLAM collections joined online social spaces. The result was @TroveNewsBot, sharing digitised newspaper articles from Trove.

Twitter bots started popping up around the world, sharing collection items from Europeana, the Digital Public Library of America, DigitalNZ, the Cooper Hewitt Museum, and the Brooklyn Museum, amongst others. But @TroveNewsBot was always a bit different. Instead of just sharing randomly selected resources, @TroveNewsBot helped people explore Trove without leaving Twitter. If you tweeted keywords at the bot, it would run a search using the API and tweet back the most relevant result. By adding hashtags, users could control a variety of search parameters – for example, if you included the hashtag #luckydip you’d get back a random article from your search results.
My favourite bot behaviour was its ‘opinionator’ mode. If you tweeted a url at @TroveNewsBot, it would retrieve the link, extract keywords from the text, and then search for those keywords in Trove’s newspapers. This enabled @TroveNewsBot to have conversations with other online resources – for example, it replied to tweets from DPLA and DigitalNZ, finding connections between different collections. I also used the ‘opinionator’ mode to set up a dialogue between past and present. Several times a day, the bot would grab keywords from the latest news items on the ABC (later the Guardian) website, search for historic newspaper articles, and then tweet both stories, old and new.
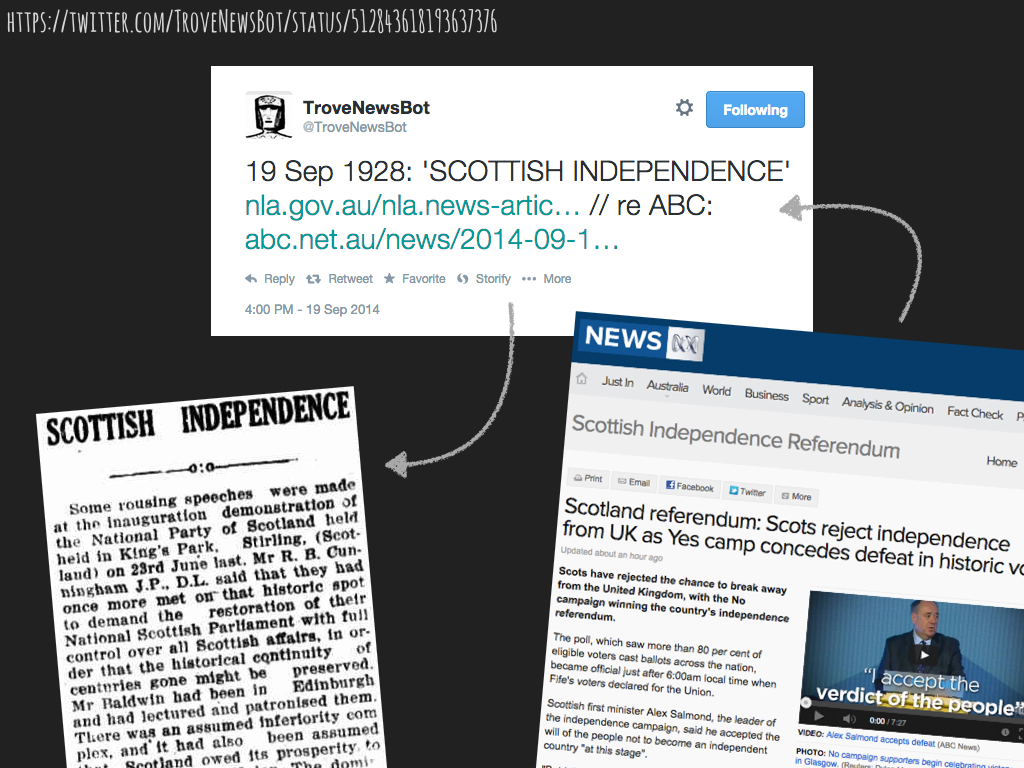
@TroveNewsBot’s opinionator mode in action – a slide from my keynote presentation ‘Life on the outside: connections, contexts, and the wild, wild web’ for the Annual Conference of the Japanese Association of Digital Humanities in 2014
As well as providing digitised content, such as the newspapers, Trove aggregates collection metadata from hundreds of organisations around Australia and makes it available through its own API. This meant that any organisation could use the Trove API to create a Twitter bot that shared items from their own collection. To encourage more of this sort of experimentation, I created the Build-a-Bot Workshop GitHub repository. This repository included instructions and code for anyone wanting to build their own collection bot on top of the Trove API. Like @TroveNewsBot, these collection bots could share random items and respond to user queries.
Before long, @CurtinLibBot was sharing photos from the Curtin University Library’s image collection, and @Kasparbot was tweeting about objects from the National Museum of Australia. By the end of 2013, I’d added to the family by creating @TroveBot. While @TroveNewsBot dug into the digitised newspaper articles, its younger sibling looked for inspiration amongst Trove’s other zones – sharing books, journals, photos, maps and more.
In 2015, Steve Leahy unleashed @TrovePenguinBot upon the world, searching for sardines amongst the digitised newspapers. In 2016, one of my students at the University of Canberra modified the NYPL Emoji Bot code to create @TroveEmojiBot – if you tweeted an emoji at the bot, it would respond with a suitably-themed newspaper article. In 2017, the Digitise the Dawn campaign bot-ified their Twitter account, posting an article each day from Louisa Lawson’s journal, The Dawn. Meanwhile, @astrove_bot started sharing newspaper articles relating to astronomy.
And then there was The Vintage Face Depot…
Things get weird
I’d been experimenting for a few years with faces as a way of connecting to GLAM collections –as alternative entry points, based not on metadata but the people inside. In 2015, this led me to create The Vintage Face Depot. If you tweeted a photo of yourself to @facedepot, the bot would select a face at random from a collection I’d compiled from Trove newspapers and superimpose that face over yours, tweeting you back the result and a link to the original article, so you could find out more about the person you’d been matched with.
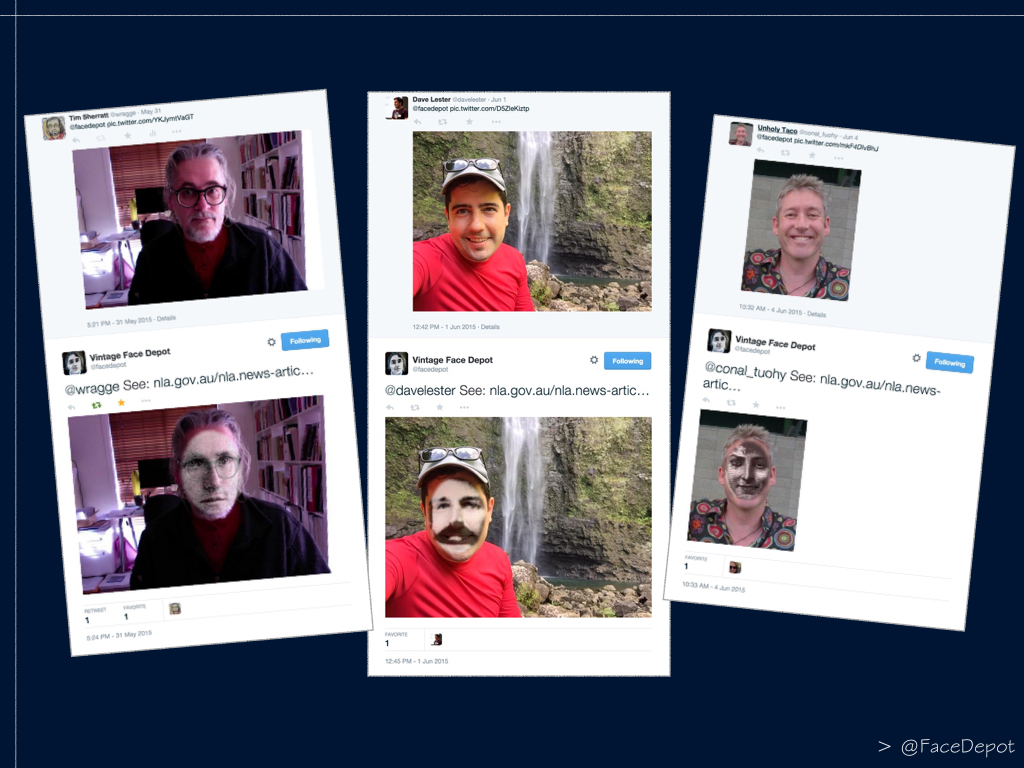
@facedepot in action – a slide from my keynote presentation ‘Unremembering the forgotten’ for the Alliance of Digital Humanities Organizations Annual Conference in 2015
Now, in a time of deep fakes and AI generated images, @facedepot’s efforts seem quaint and kludgy. But that was always the point. I wanted to mess around with the barriers that put some people on the other side of this wall we call the past – to explore what historian Devon Elliot suggested on Twitter was an ‘uncanny temporal valley’. As I argued in The Perfect Face, a presentation at NDF2015:
The Vintage Face Depot tells you nothing about yourself. I built it at about the same time as Microsoft launched their How-Old bot that uses machine learning to estimate your age. Face Depot does nothing clever, and yet sometimes the results are uncanny, even unsettling. Microsoft might be able to tell you how old you are, but Face Depot asks who you are and pushes you in the direction of a past life, linked merely through chance.

Glitch bots for all
While I’d shared some bot-building code, rolling your own bot still required access to a web-connected server – a significant barrier for most would-be experimenters. This changed in 2017 with the arrival of Glitch, a platform that enabled anyone to build simple web apps for free. Perhaps most importantly, Glitch apps were remixable – simply by clicking a button, you could open an editor and create your own customised version of any app.
Glitch seemed like an ideal environment in which to experiment with bots, so I created four remixable Trove Twitter bot recipes:
- trove-collection-bot – sharing resources from a partner collection
- trove-list-bot – sharing items from a Trove list
- trove-title-bot – sharing articles from specific newspapers
- trove-tag-bot – sharing items with specific tags
These were supported by a detailed tutorial that walked through the process of customisation and suggested ways in which the basic recipes could be extended – for example, by adding a specific search query to a title bot.
This was the beginning of the bot explosion, with more than 30 Trove Twitter bots born between 2017 and 2019.
One of these, @NTTimesGazette, was created by curator and journalist Caddie Brain to tweet articles from the Northern Territory Times and Gazette. The bot was featured on ABC radio in Darwin under the headline: Twitter bot offers a rare look inside the Darwin’s forgotten first newspaper.
Historian Brett Holman created a series of bots related to aviation history. More than just a source of amusement, the bots became part of Brett’s research practice, as described in his History Australia article '@TroveAirRaidBot, a 24/7/365 research assistant'.
Perhaps the best part of this bot-making extravaganza was the number of self-professed ‘non coders’ who were able to take their first steps into the world of programming and actually create something. I have memories of sitting in the shade at Canberra’s now defunct Big Splash water park, troubleshooting someone’s Twitter bot on my phone, while the kids played on the water slides – it was fun, and it was exciting. Together, Trove, Twitter, and Glitch opened up new possibilities for learning and experimentation, and new ways of knowing Australia’s cultural heritage.
2019 bot roll call
As new bots emerged, I added them to my Trove bots Twitter list (here’s a partially archived copy).
You can get an idea of their diversity from the bot names – a mix of collections, subjects, and places. Here’s a list of Trove Twitter bots active in 2019:
- astrove_bot
- AustWWBot
- BotCBR_QLD
- CatsofTrove
- digitisethedawn
- DoSonTrove
- facedepot
- Kasparbot
- KellyGangBot
- LAAL_bot
- NTTimesGazette
- PenrithPictures
- RemixHistorical
- suthlib
- TroveAirBot
- TroveBot
- TrovecakeBot
- TroveCHIAbot
- TroveDutchbot
- TroveEmojiBot
- trovefacesbot
- TroveHoroscopes
- Troveknitbot
- Trovelandbot
- trovelistbot
- TroveMirrorBot
- TroveNewsBot
- TrovePenguinBot
- TroveRefereeBot
- trovesportsmel
- trovetribunebot
- TroveXmasBot
- TsvBulletinBot
- WomenAtWarBot
I also overhauled @TroveNewsBot in 2019, adding a number of new features, including article thumbnails.
Decline and fall
This golden age of bot-making came to an end late in 2019.
The first blow came when Trove updated its API. The bots needed some way of selecting random items from the millions available on Trove. This was fairly easy with version one of the API, but version two overhauled the way you accessed items within the result set, making random selections impossible. I eventually managed to hack together a random-ish method that added multiple facets to whittle down the results set until a selection could be made. Using this method, I created new versions of my Glitch bot recipes and updated the tutorial. But it seemed that the moment had passed, and many bot authors just let their creations die when version one of the API was switched off.
Surviving bots faced further challenges when Glitch started imposing limits on its free services. Glitch apps were designed to sleep when not in use, so to get your bot tweeting you had to fire regular web requests at it using a cron service. Glitch blocked access by these services and introduced a paid tier for ‘always on’ apps. More bots died as a result.
I was thinking about switching my recipes from Glitch to GitHub, making use of templates and scheduled actions. But while I prevaricated, Twitter started on its long, drawn out death spiral – first imposing new limits on API use, and later becoming the preferred networking site for nazis and transphobes. It was no place for creative bot-making.
The serious side of serendipity
Bot-making wasn’t just about fun – Trove Twitter bots had a serious purpose as well. In ‘Unremembering the forgotten’ I wrote:
Twitter bots can interrupt our social media meanderings with pinpoints of surprise, conflict, and meaning. And yet they are lightweight, almost disposable, in their development and implementation. No committees were formed, no grants were obtained—they are quick and creative: hacks in the best sense of the word. Bots are an example of how digital skills and tools allow us to try things, to build and play, without any expectation of significance or impact. We can experiment with the parameters of access.
A number of articles on the value of serendipity have considered how collection bots, like @TroveNewsBot, can puncture our research expectations. The random offerings of bots might offer new modes of discovery. In ‘Technologies of Serendipity’, Paul Fyfe argues:
For scholars or other readers, discovery results less from directed searching than from all the tangents encountered on the way. Thus, sources which are plural, redundant, and tangent-rich help promote discovery by the proliferating contingencies of their usage.
Similarly, Brett Holman notes that his own Trove bots help him make connections in his research:
By impinging on my consciousness when I am preoccupied by other things, @TroveAirRaidBot’s tweets draw my mind back to this research topic that is always sitting at the back of my mind somewhere, and it makes me make connections – randomly, haphazardly, but often very fruitfully leading me to think of something I hadn’t thought of before, or reminding me of something I’d forgotten, or juxtaposing some seemingly unrelated things. It’s a kind of directed serendipity.
Trove Twitter bots were also entry points and interventions – challenging our understanding of access. They offered playful demonstrations of how our experience of GLAM collections might be different. Mitchell Whitelaw suggested that such creations:
reflect an emerging interest in collections as active sites of meaning-making, and experimentation with how we might encounter such collections in an everyday digital environment.
In ‘Life on the outside’, I considered the lives that GLAM collections might lead beyond institutional confines:
These bots do not simply present collection items outside of the familiar context of discovery interfaces or online exhibitions, they move the encounter itself into a wholly new space. … Twitter bots loosen the institutional context of collections to allow them to participate in a space where people already congregate. They send collection items out into the wilds of the web, to find new meanings, new connections and perhaps even new love.
The promise of serendipitous discovery has now faded with the poisoning of social media spaces, and the retreat of many GLAM organisations from experimentation and openness. The need to control now carries more weight than the gift of creativity.
What remains
I migrated @TroveNewsBot to the Fediverse in May 2023, but sadly it was killed when NLA gatekeepers cancelled my Trove API keys without warning in January 2025.
A number of other Trove bots have survived the Twitter implosion and found their way to alternate platforms. @DigitiseTheDawn now shares articles on the Fediverse, while @TrovePenguinBot is pursuing sardines on Bluesky. Brett Holman has created new versions of his aviation-themed bots – @TroveAirBot, @TroveAirRaidBot, and @TroveUFOBot – on Bluesky. I’d be happy to add the details of any other survivors I might have missed.
In an odd coincidence, recent months have brought new restrictions on access to Trove API keys, and an announcement of the end of Glitch. There’s no going back.
ActivityPub and the Fediverse seem to offer new digital channels through which collections might flow and connect. See, for example, Aaron Straup Cope’s work at the SFO Museum. But how do we support and encourage this type of experimentation?
Personally speaking, this year’s been pretty shit so far, and I’ve been having trouble finding any motivation. But in pulling together these notes I found a section in ‘Unremembering the forgotten’ that reminded me of what’s at stake:
There is no open access to the past. There is no key we can enter to recall a life. I create these projects not because I want to contribute to some form of national memory, but because I want to unsettle what it means to remember: to go beyond the listing of names and the cataloging of files to develop modes of access that are confusing, challenging, inspiring, uncomfortable, and sometimes creepy.
There’s still plenty of work to do.
![]()