What’s that? You want MORE GLAM data? Well, I’ve started a list of sources for Australian GLAM data. Metadata, full text, images & more. Contributions welcome! #dhhacks
What’s that? You want MORE GLAM data? Well, I’ve started a list of sources for Australian GLAM data. Metadata, full text, images & more. Contributions welcome! #dhhacks
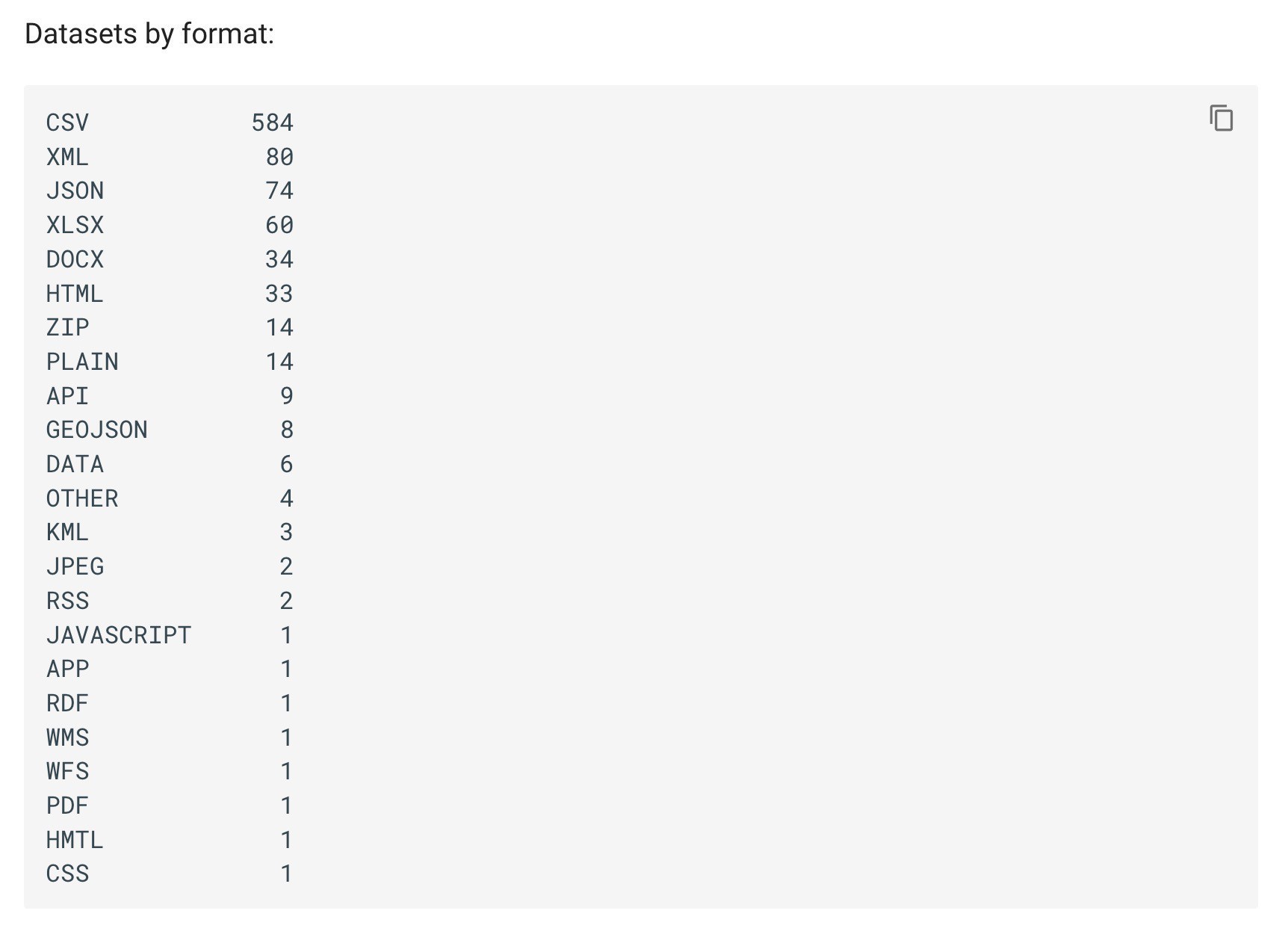
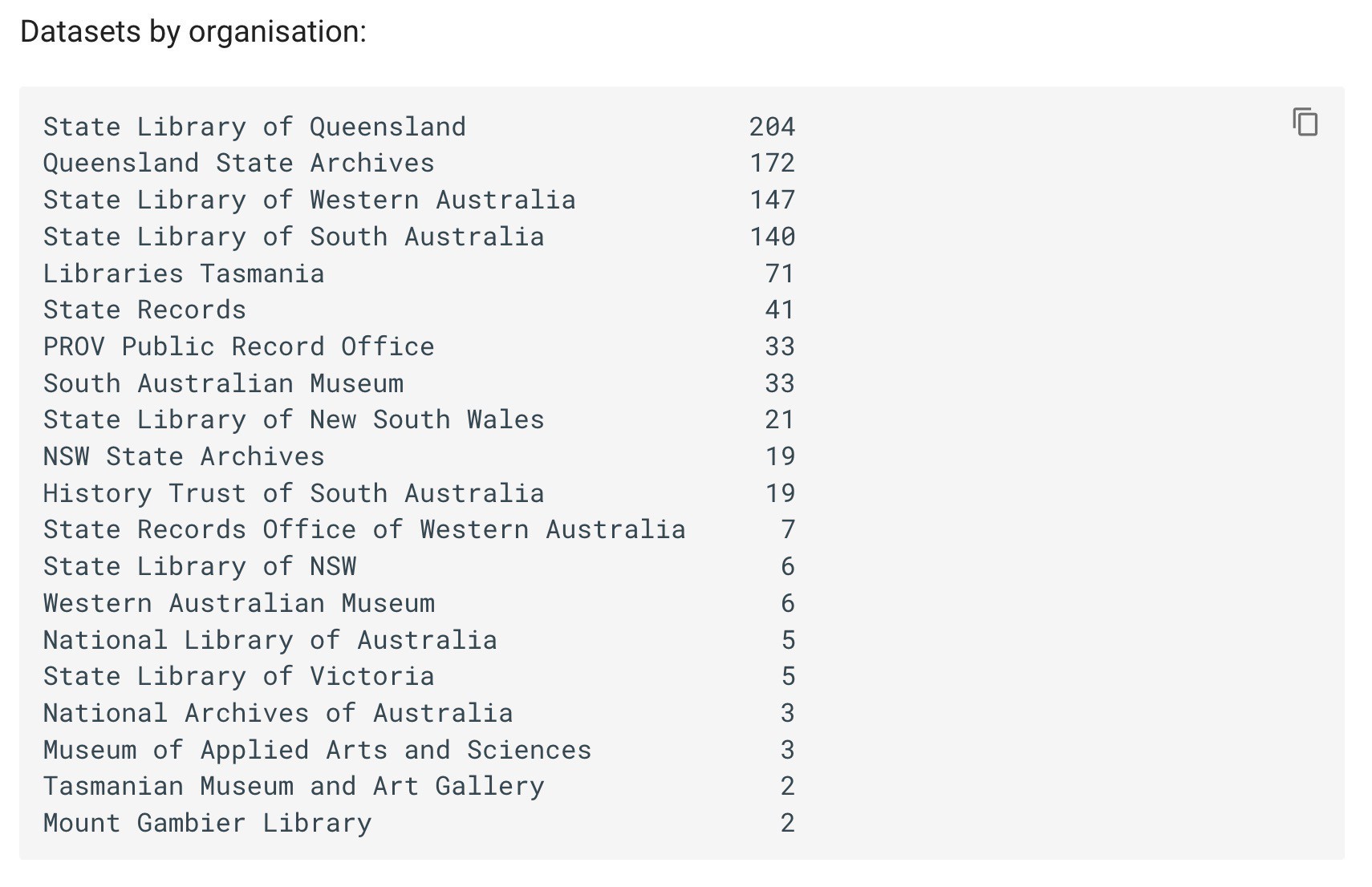
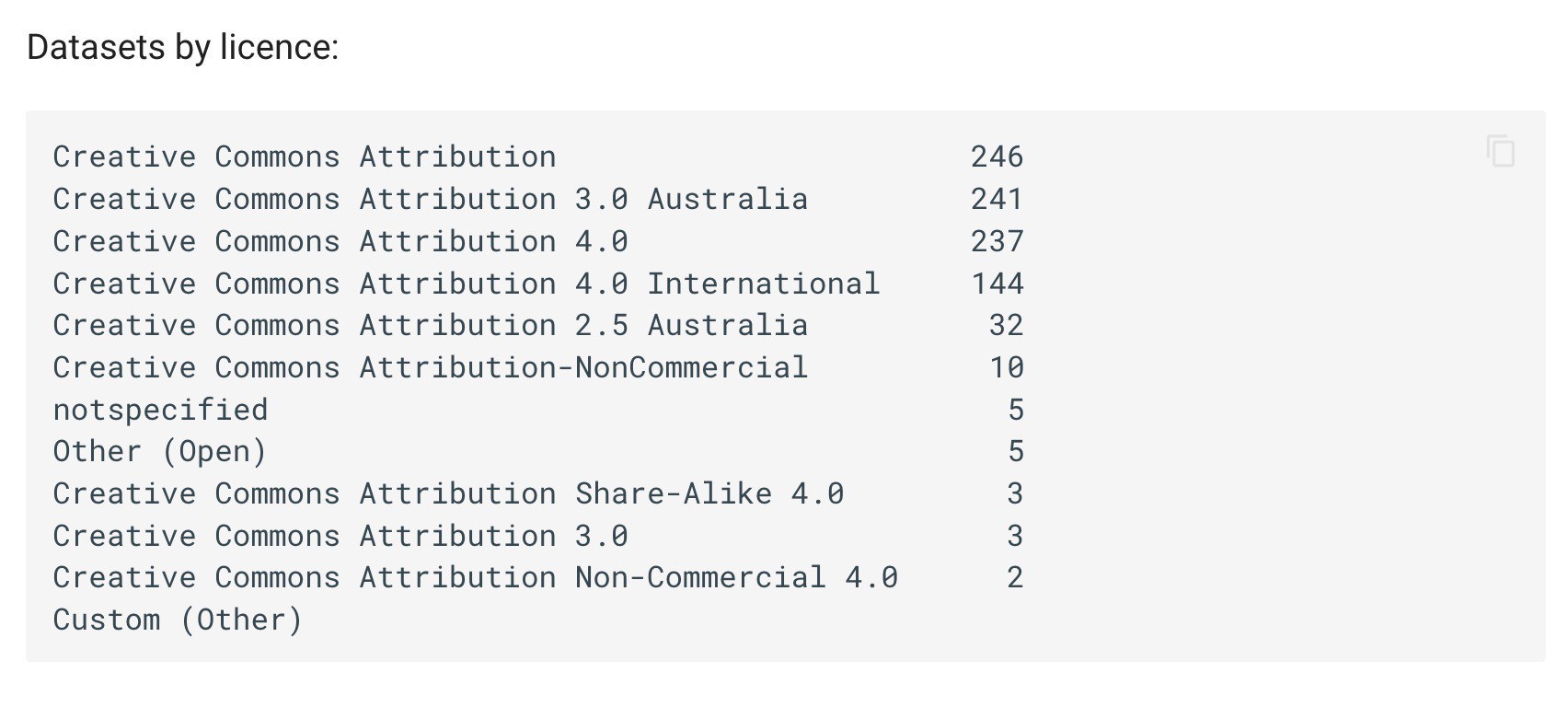
I’ve updated my harvest of GLAM datasets from data.gov.au. Now there’s 584 CSV files available for download! #dhhacks
I’ve put a copy of my article on using @TroveAustralia for digital research/play, written for the @HTANSW journal, up on my blog. #dhhacks

I’ve updated the list of orgs who have supported the digitisation of @TroveAustralia’s journals. As usual @statelibrarynsw leads the way, but great to see @dvaaus supporting online access.
Today I finished updating a harvest of all OCRd text available from Trove’s digitised journals. That’s about 7gb of text from 30,462 issues of 384 different journals — a fab corpus for text analysis! Here’s all the metadata, links, and harvesting code. @TDHASSN #dhhacks

Update time! Yesterday I updated my Trove digitised journals app to include all the exciting new titles added to Trove in the last few months. This includes ABC Weekly, Current Notes on International Affairs & much more. #dhhacks

A quick interactive view of newspaper articles in @TroveAustralia by state and year. Click on the bars or legend to filter by state. Jupyter notebook on its way… vega.github.io/editor/
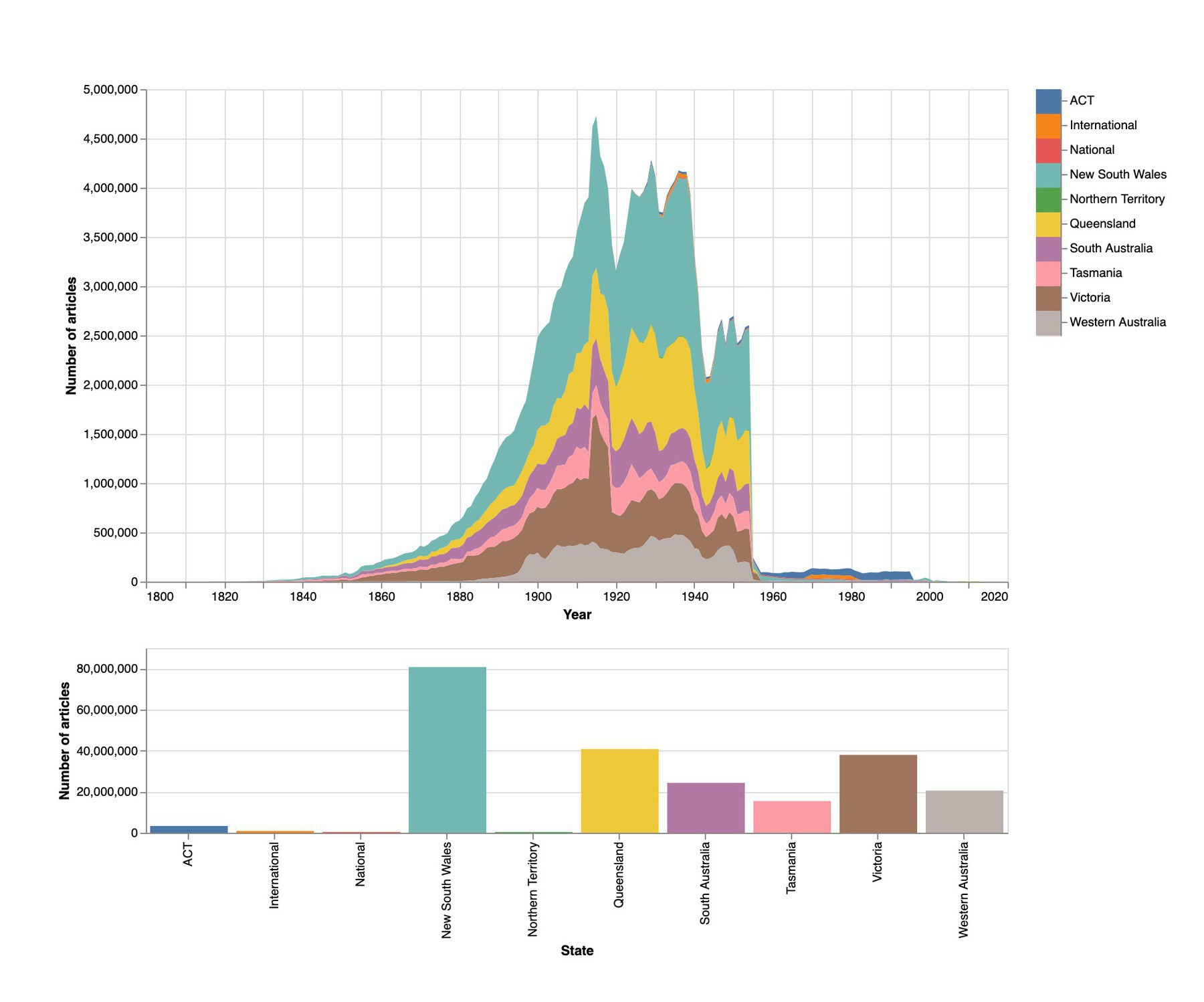
Anyone who’s been to one of my Trove workshops will be pleased to know that the WWI effect is still evident when viewing the total number of @TroveAustralia newspaper articles by year. As is the copyright cliff of death…
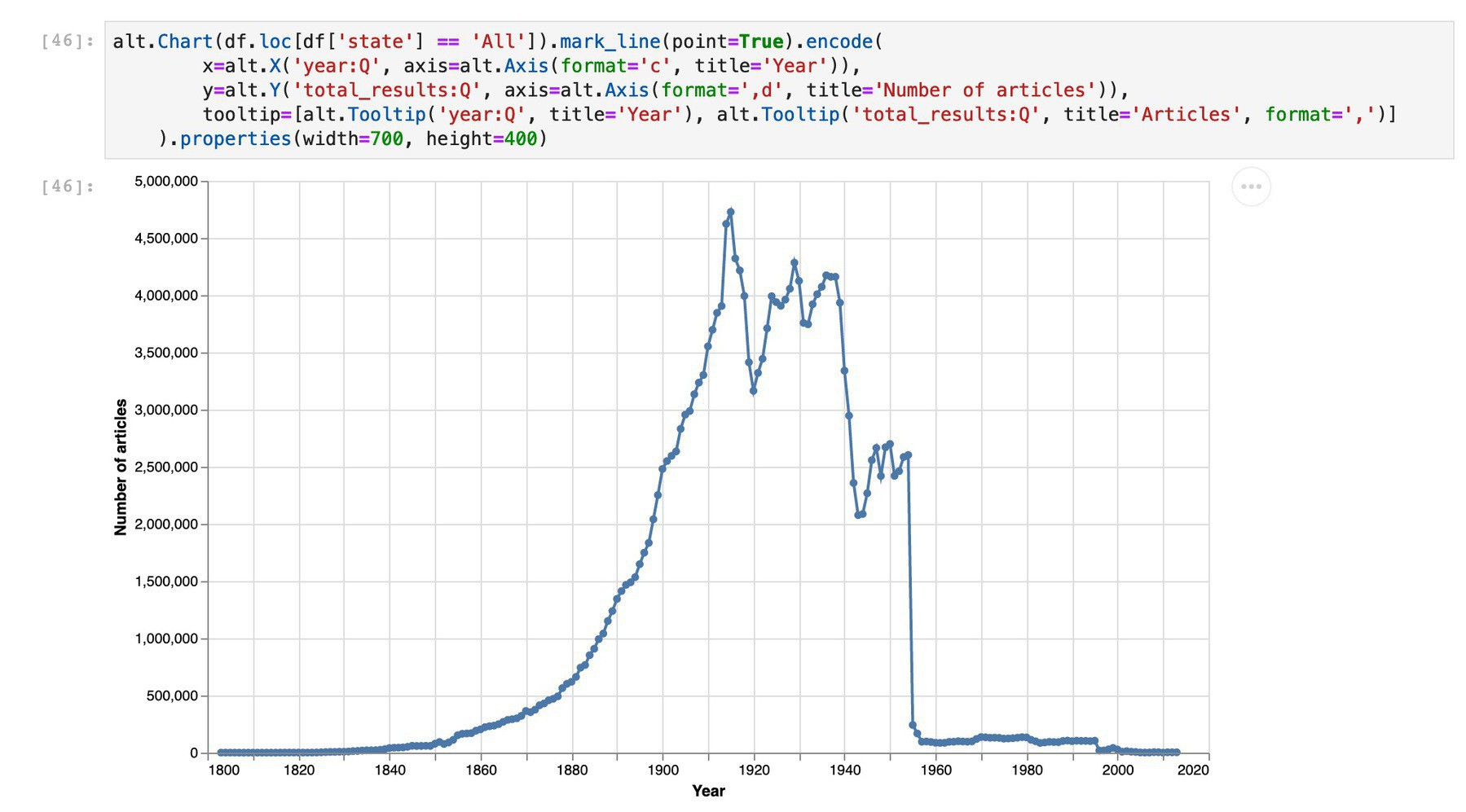
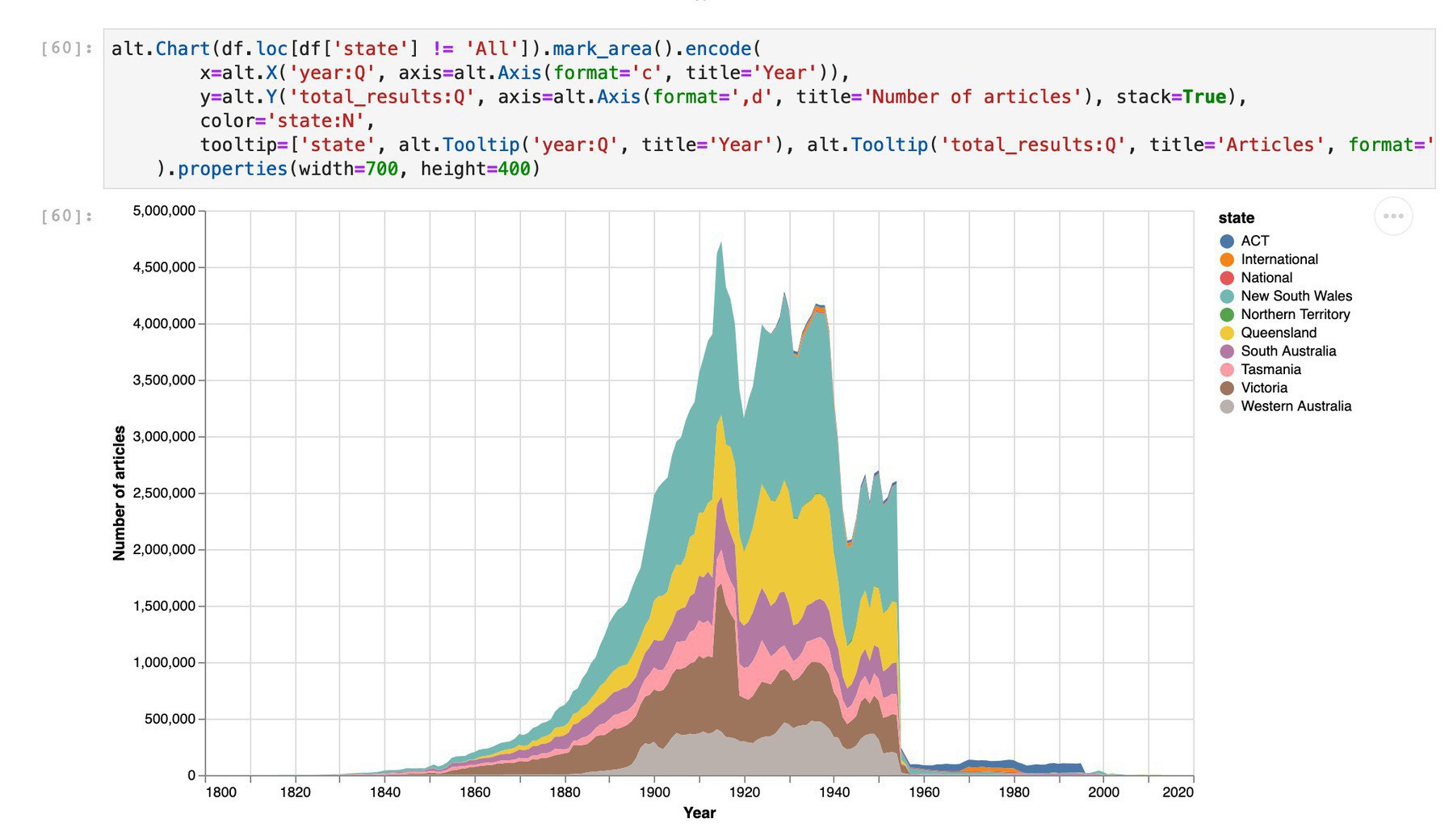
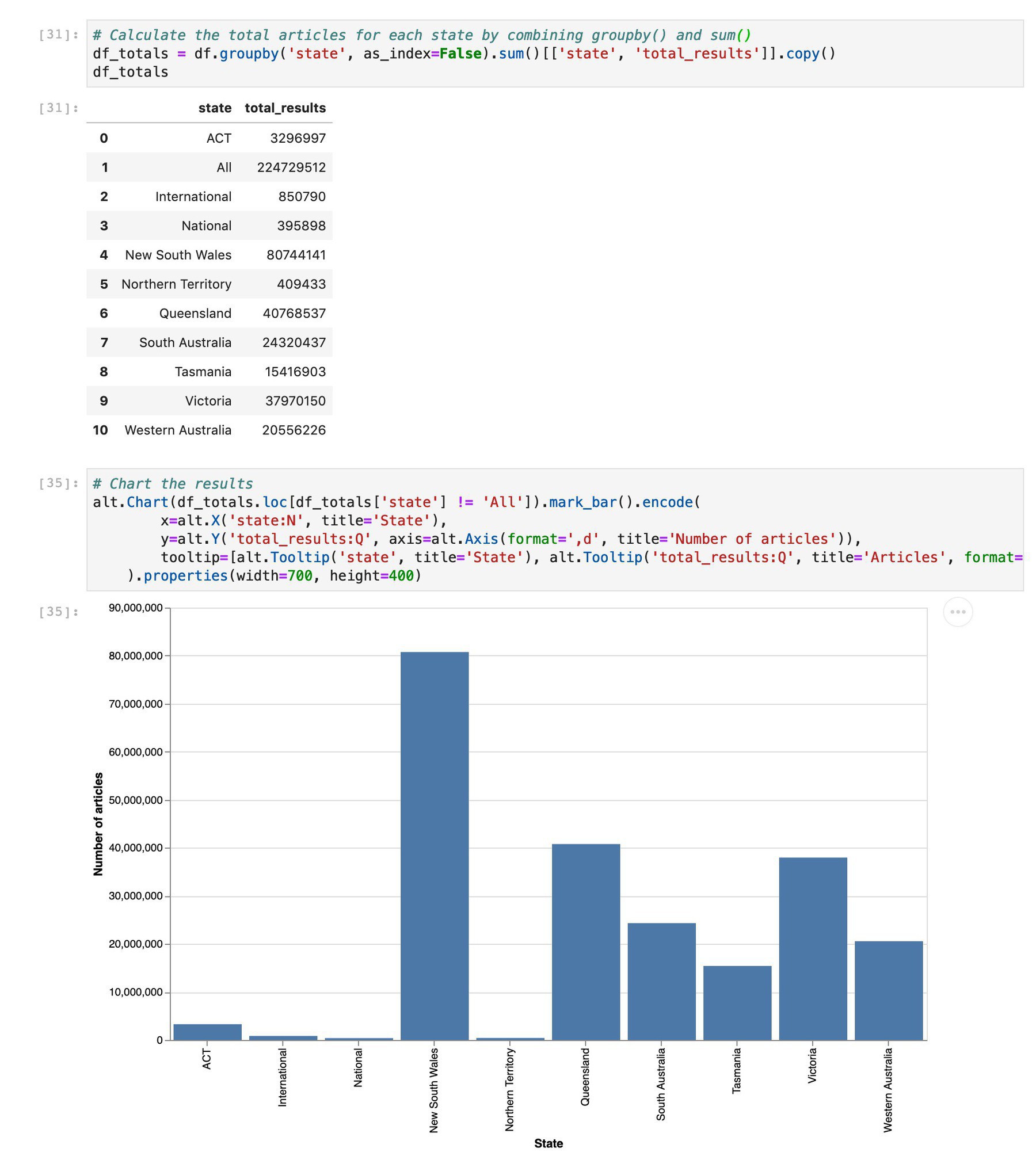
So there are now almost twice as many newspaper articles in @TroveAustralia from NSW as there are from any other state. (cc @statelibrarynsw)
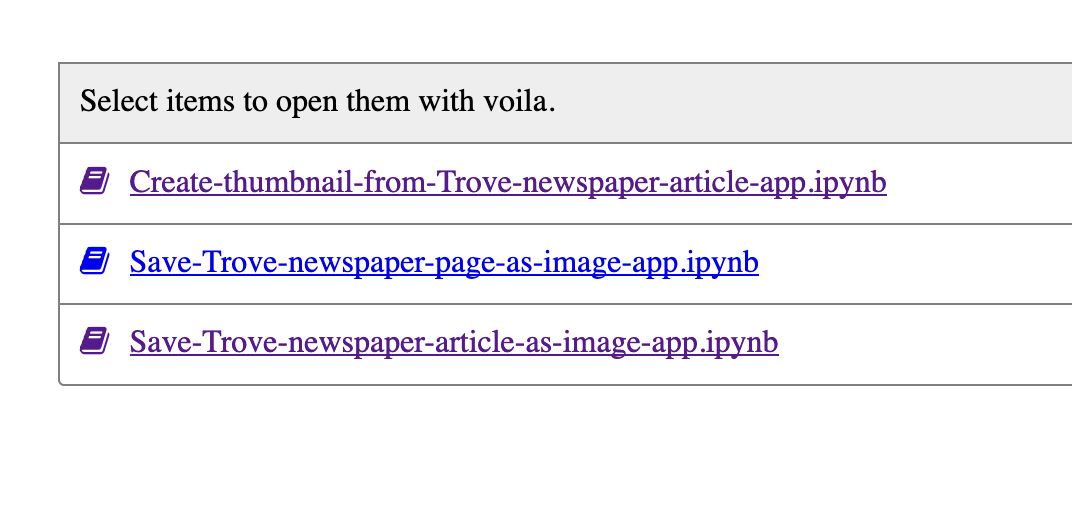
Well look at that! – a selection of my @TroveAustralia related Jupyter notebooks turned into simple apps using Voila and delivered via Heroku. Save complete newspaper articles as images, create thumbnails, or download pages! #dhhacks
Kicked off a new GLAM Workbench repository dedicated to @SLSA with a quick notebook hack to get higher res versions of digitised photos. #dhhacks

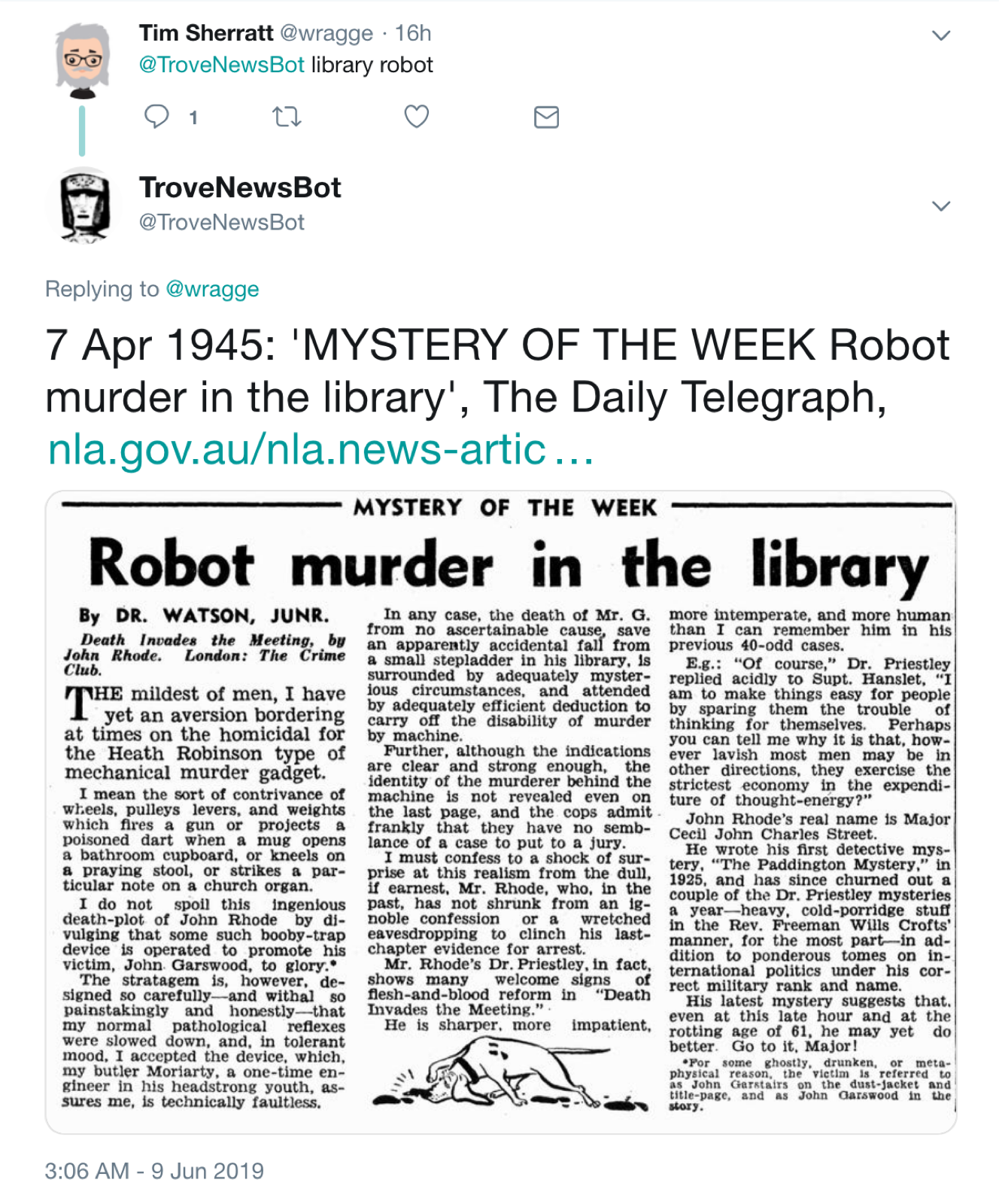
Search @TroveAustralia newspapers without leaving Twitter using the updated and enhanced @TroveNewsBot! After 6 years of regular tweeting, TroveNewsBot needed an upgrade. Check out all its new features, including article thumbnails, here. #dhhacks
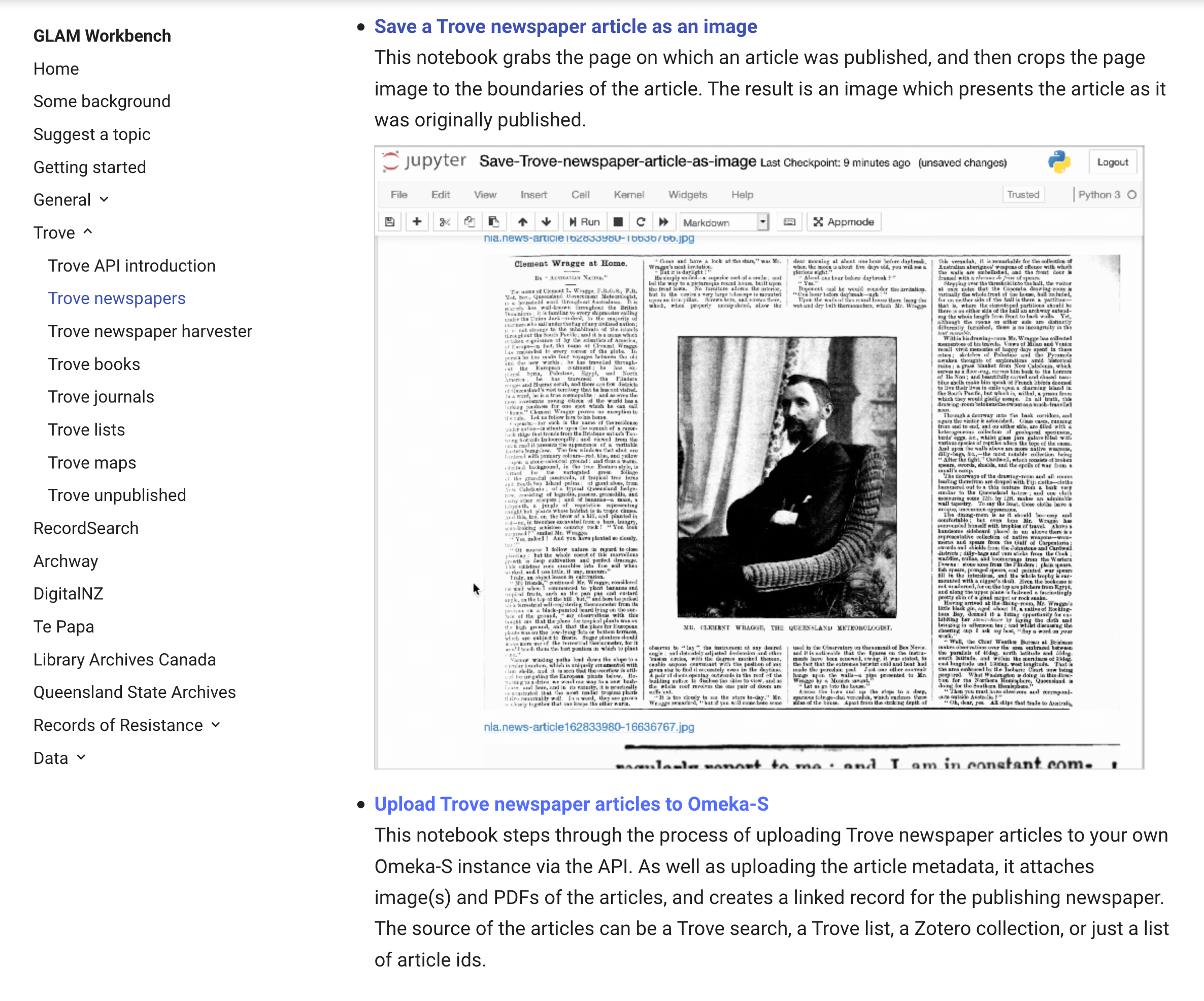
Recent additions to the Trove Newspapers section of the GLAM Workbench: getting images from @TroveAustralia newspaper articles, and uploading article to @Omeka-S: glam-workbench.github.io/trove-new…
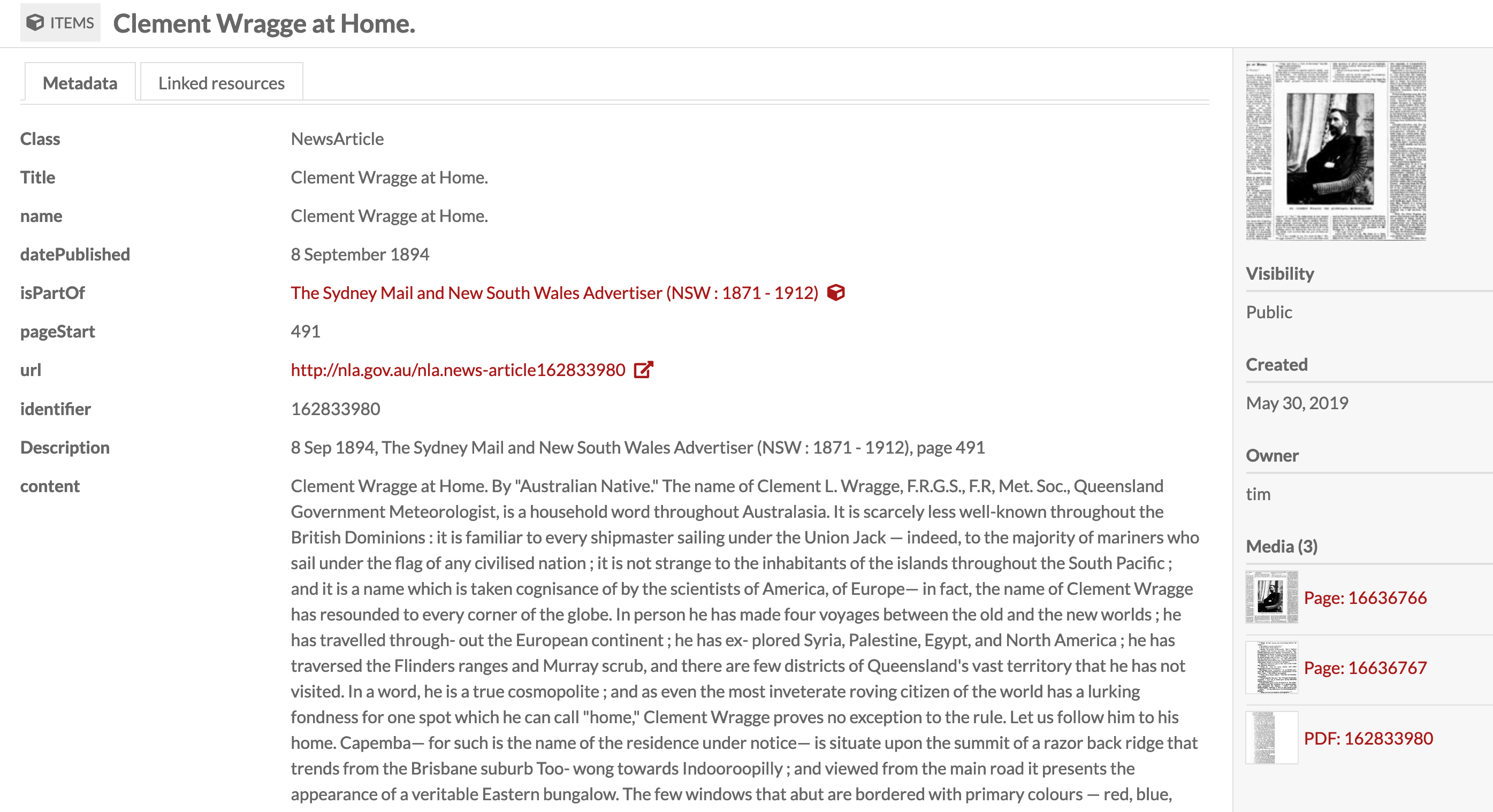
Want to upload @TroveAustralia newspaper articles to @Omeka-S to create an exhibition or populate a research database? This notebook collects article references from a search, a Trove list, or Zotero, & uploads metadata, images & PDF to your Omeka site. #dhhacks
Slides ready for tomorrow’s workshop at @unicanberra – Trove as a pltform for digital research & creativity. Here’s a sneak peek: slides.com/wragge/tr…
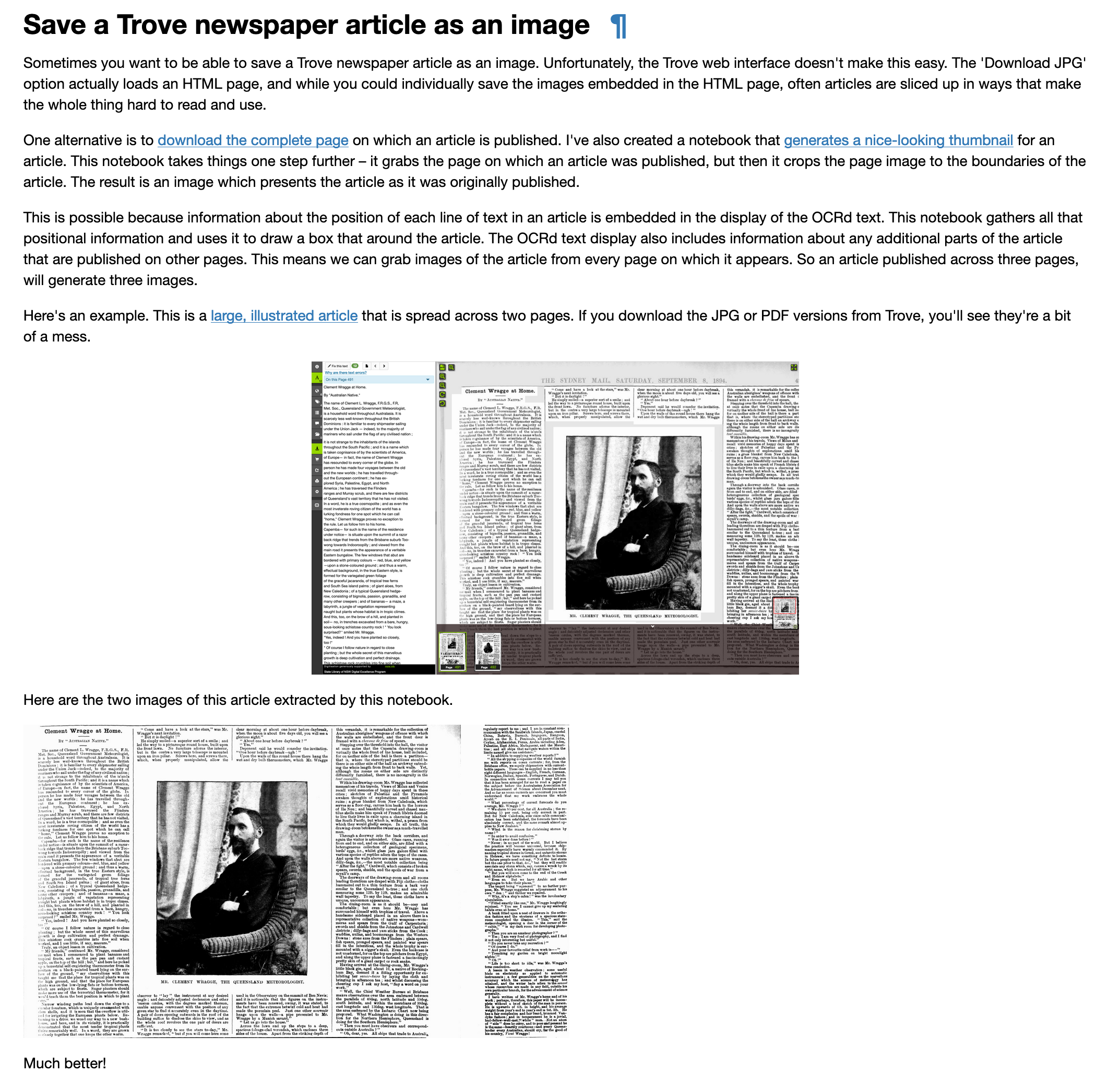
Ever wanted to save a @TroveAustralia newspaper article as an image? This notebook lets you do just that. Paste in an article url and you get nice big JPGs to download. It even works with article spread across multiple pages. #dhhacks
More GLAM Workbench updates! More full text of Australian books! I’ve added the notebook & data from my harvest of @TroveAustralia books in the @InternetArchive. There’s metadata and text of 1,153 books to explore. #dhhacks
2019 has been pretty busy so far! I just compiled a list of tools, updates, and examples from the last few months for my @Patreon supporters.
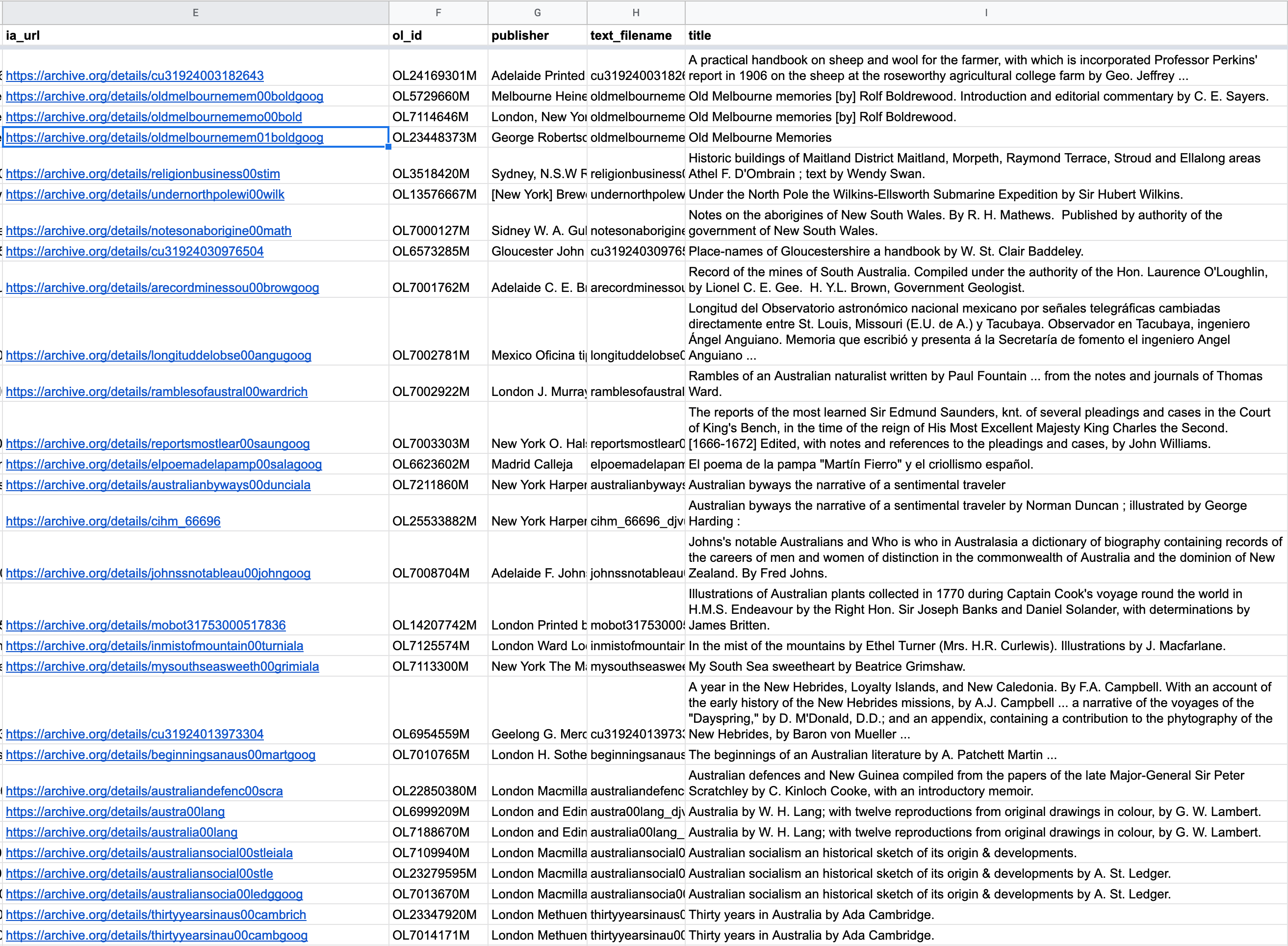
Here’s how you can get the text of Australian books in @TroveAustralia from the Internet Archive (via the Open Library). #dhhacks

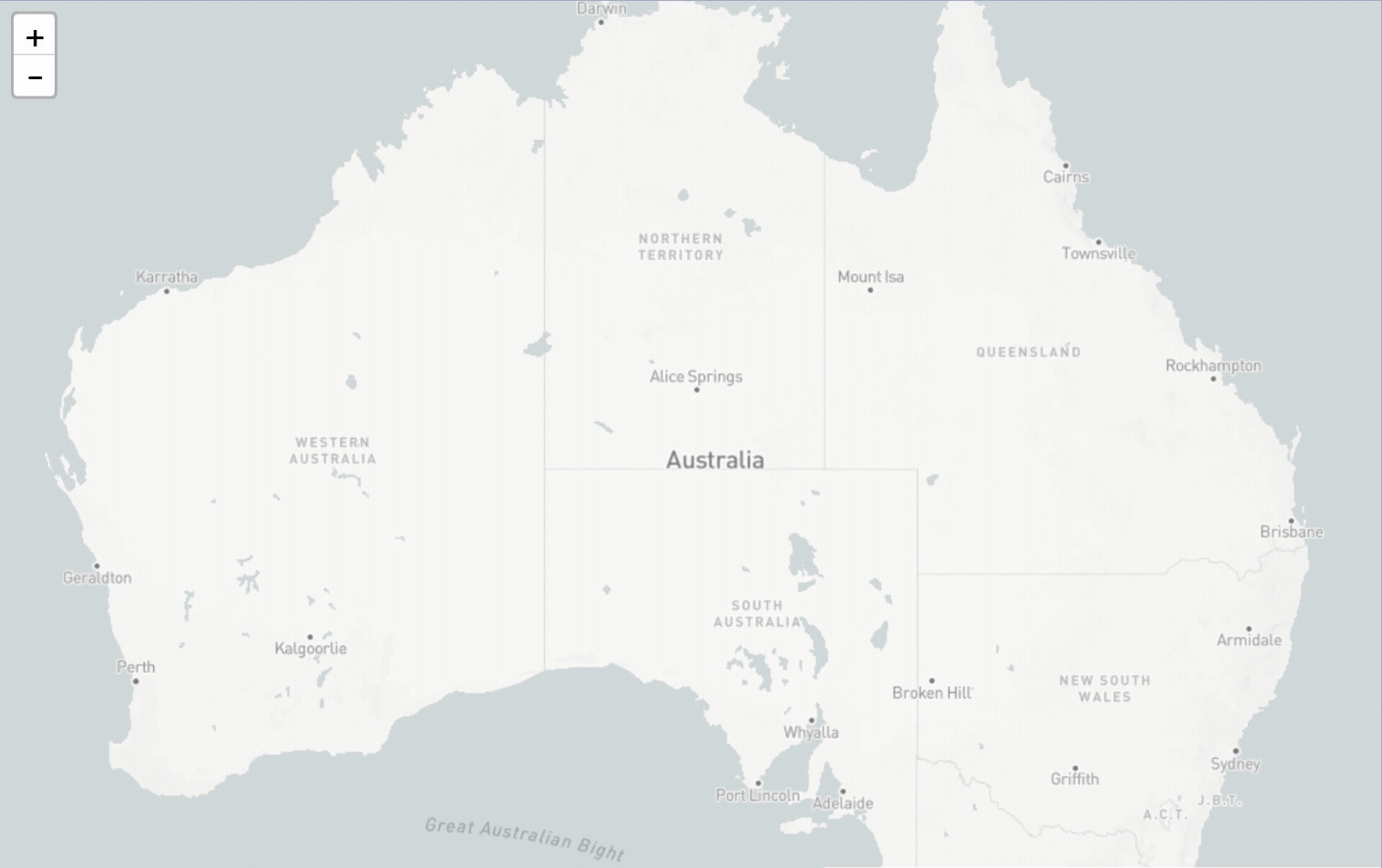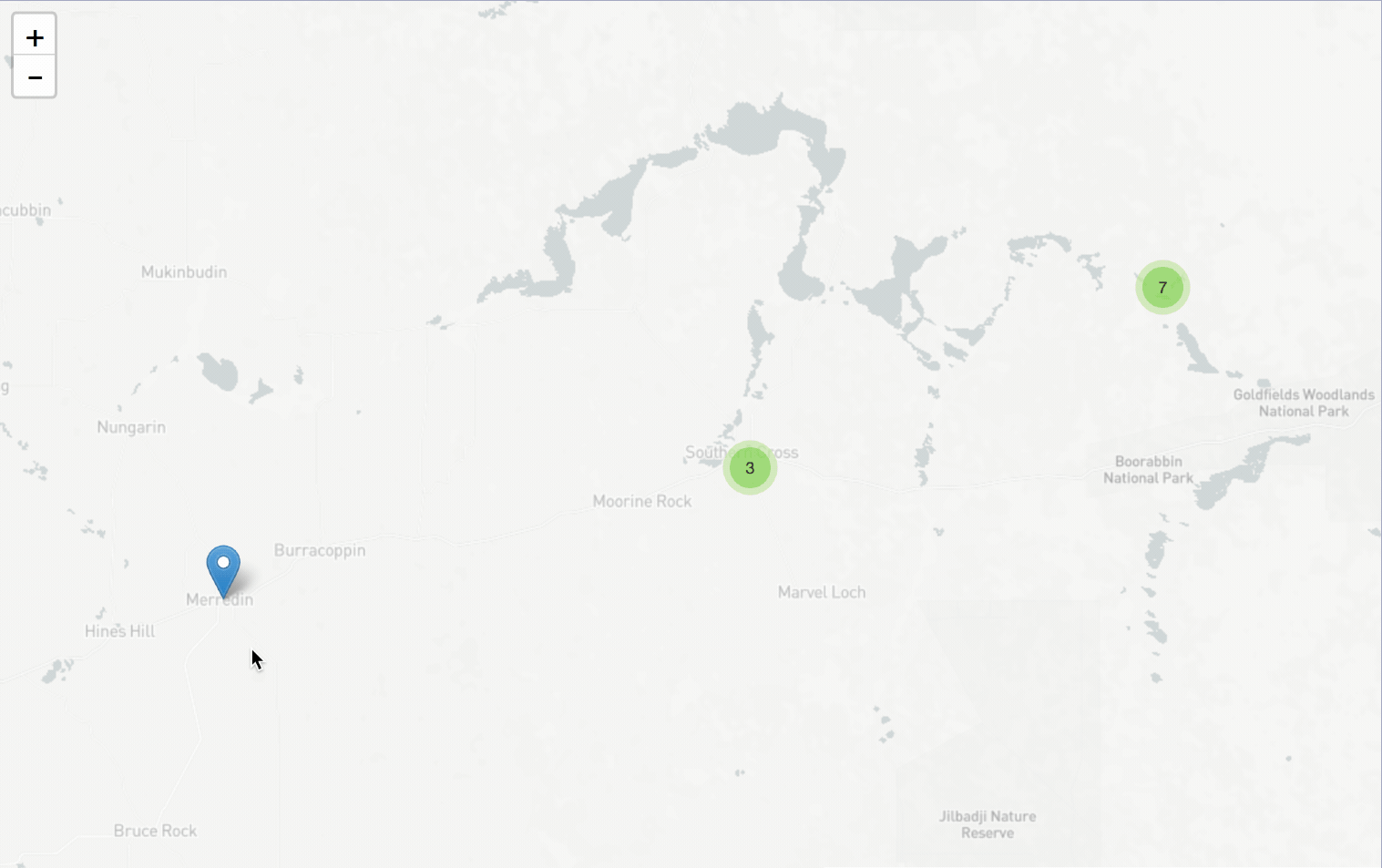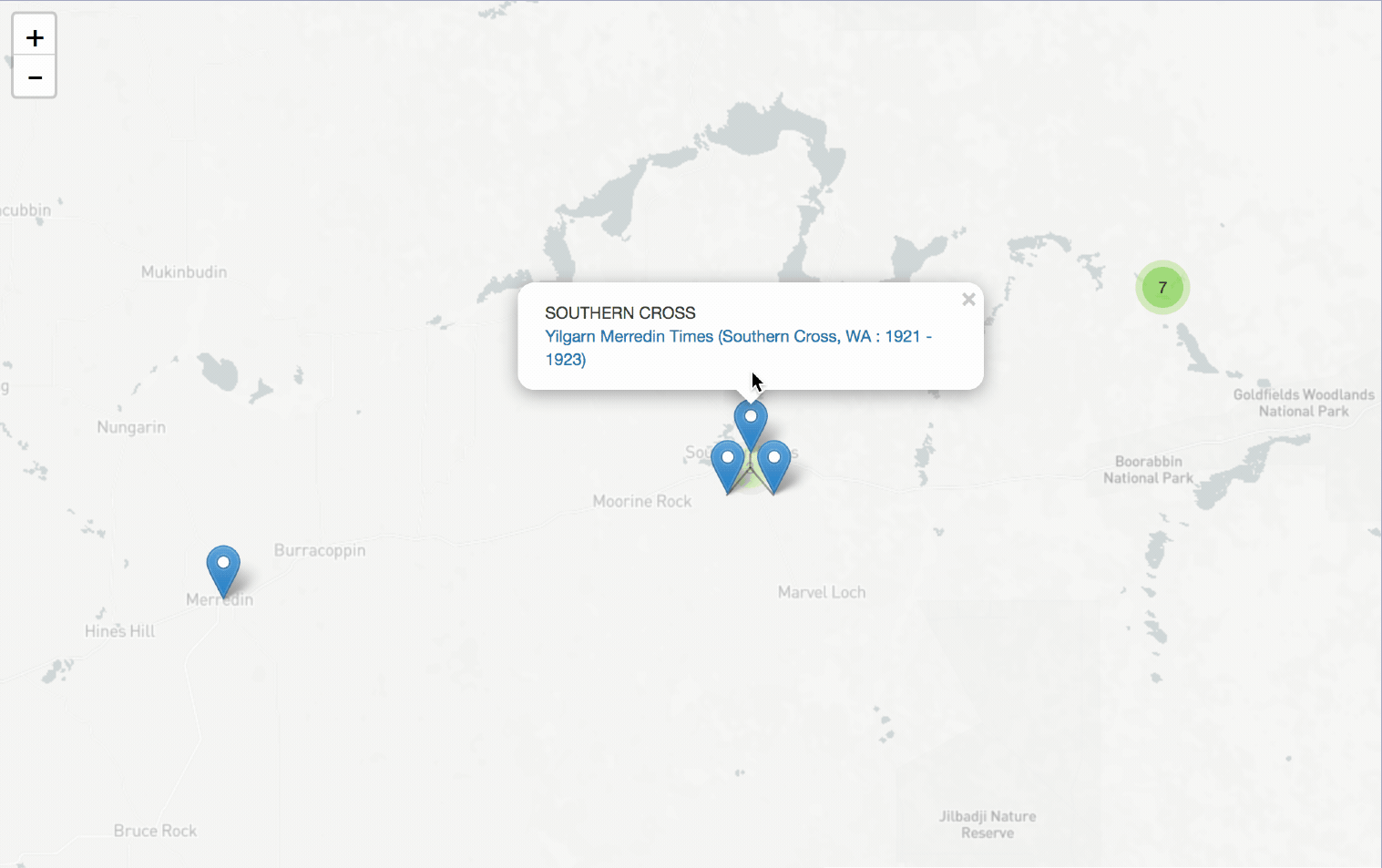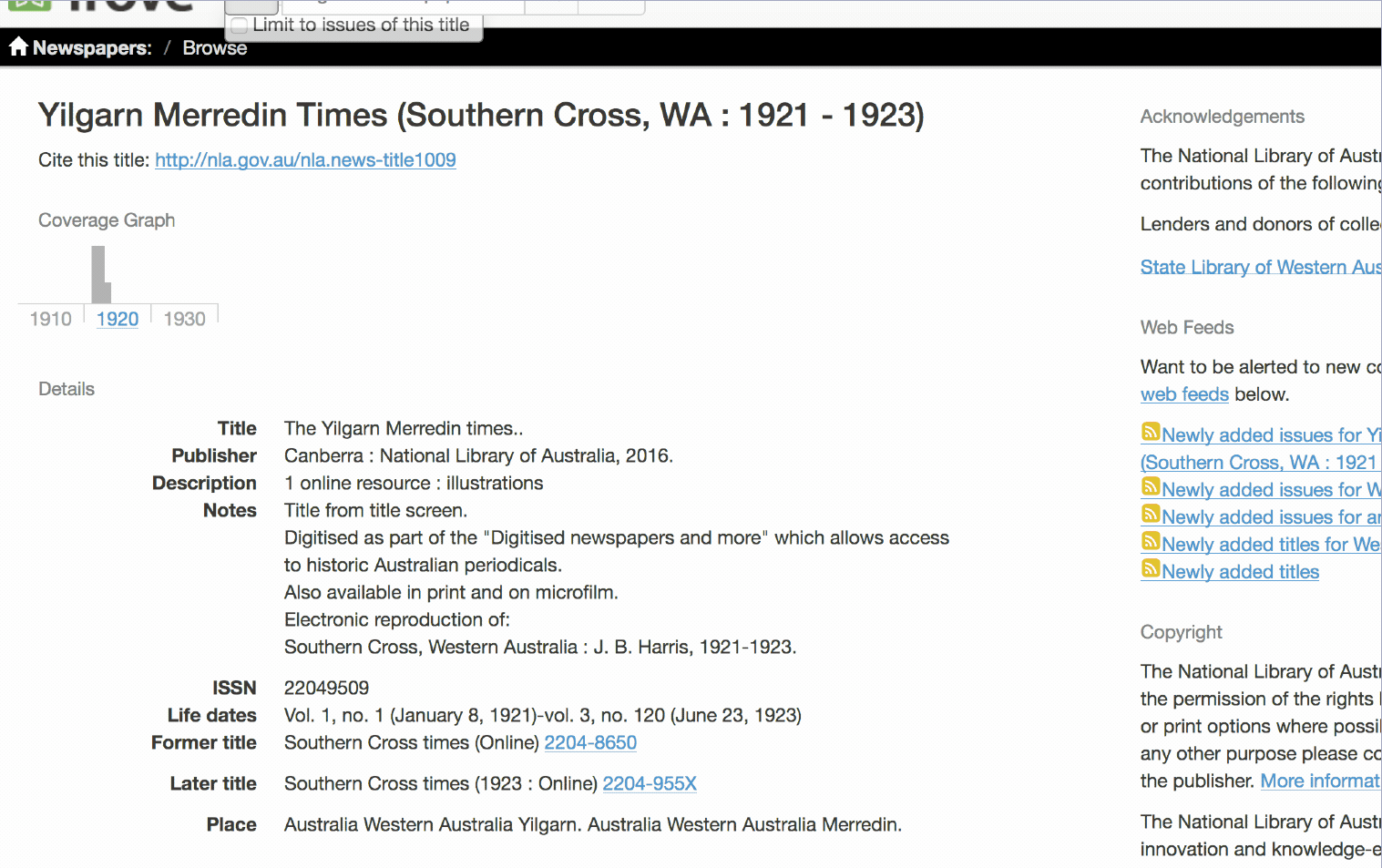
I’ve updated the data that sits behind my Trove Places app and added more than 140 newspaper titles. To find @TroveAustralia newspapers published in any region of Australia simply click on the map! #dhhacks