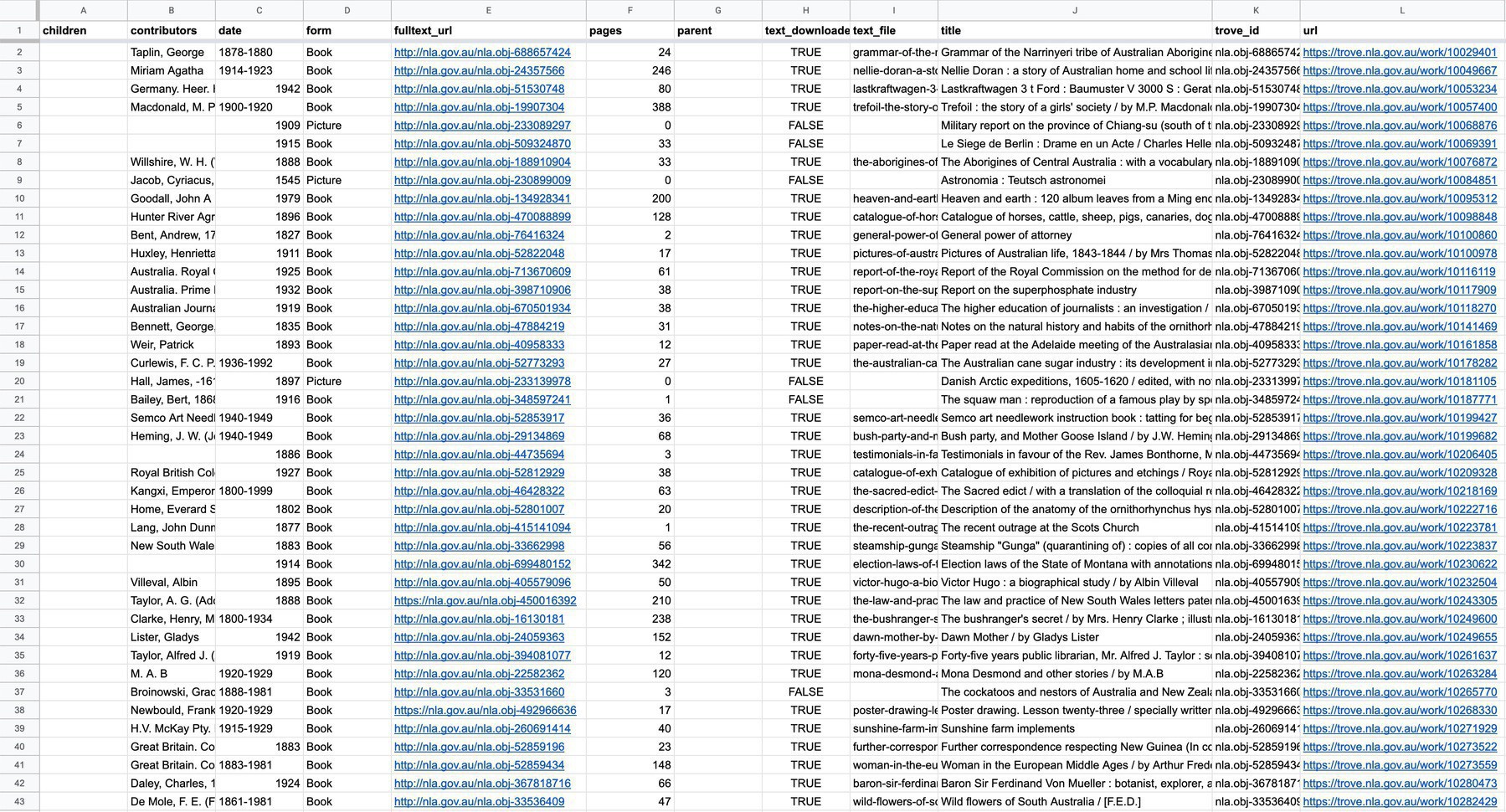
And what can you do with 400 CSV files? Well, you could explore their contents using my GLAM CSV Explorer. Select one of the files to peek inside, or upload your own CSV. #dhhacks
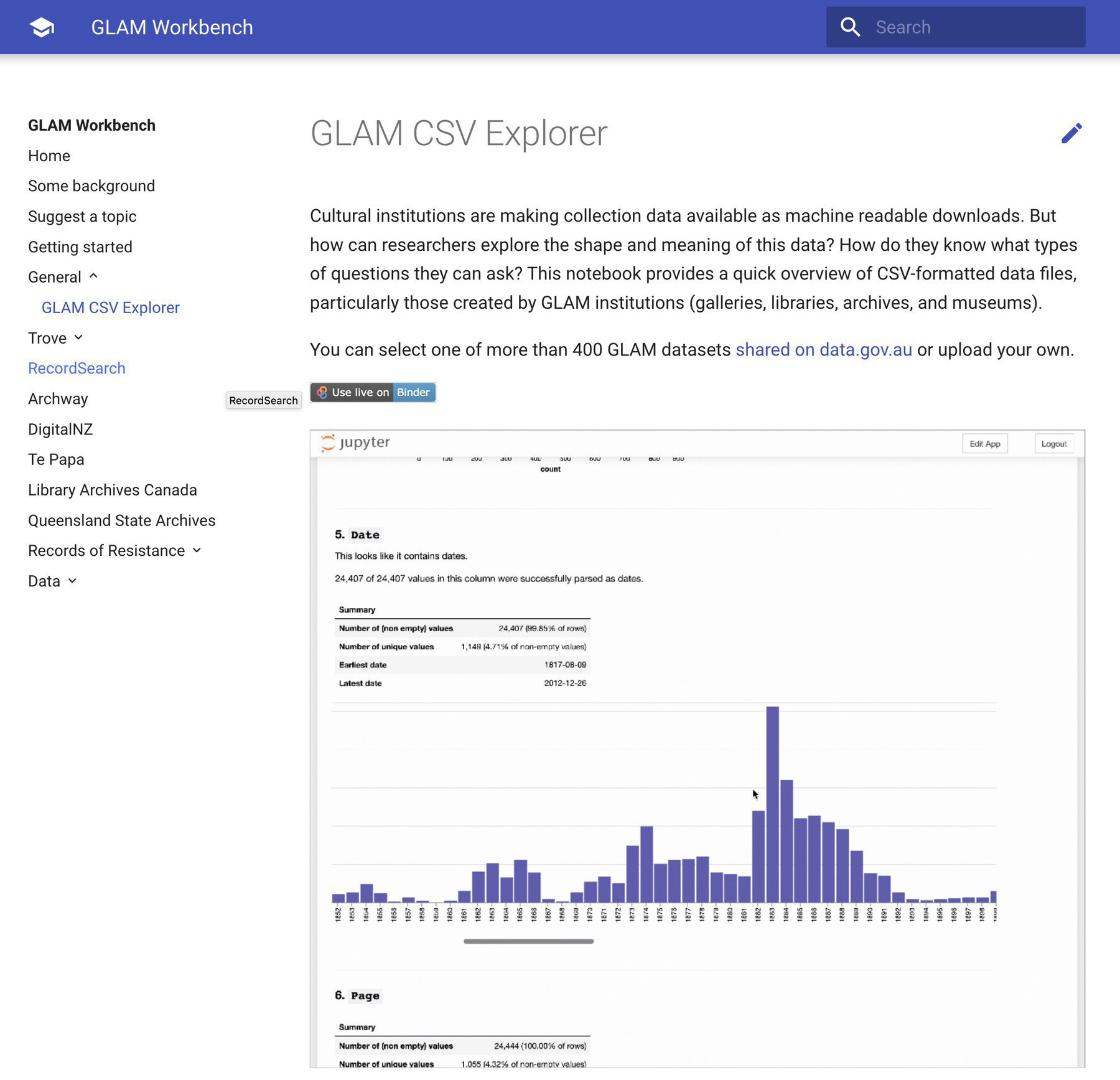
And what can you do with 400 CSV files? Well, you could explore their contents using my GLAM CSV Explorer. Select one of the files to peek inside, or upload your own CSV. #dhhacks
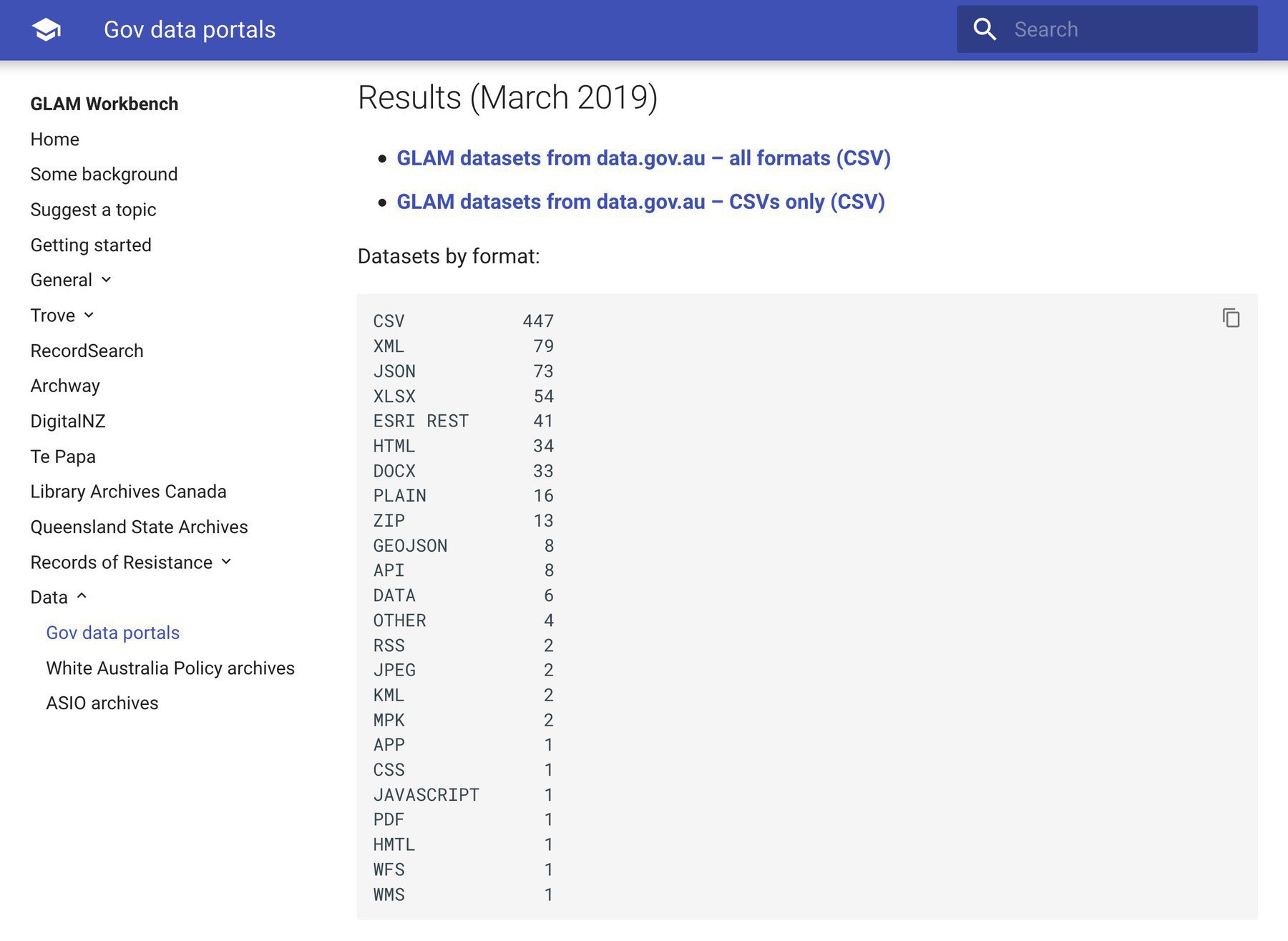
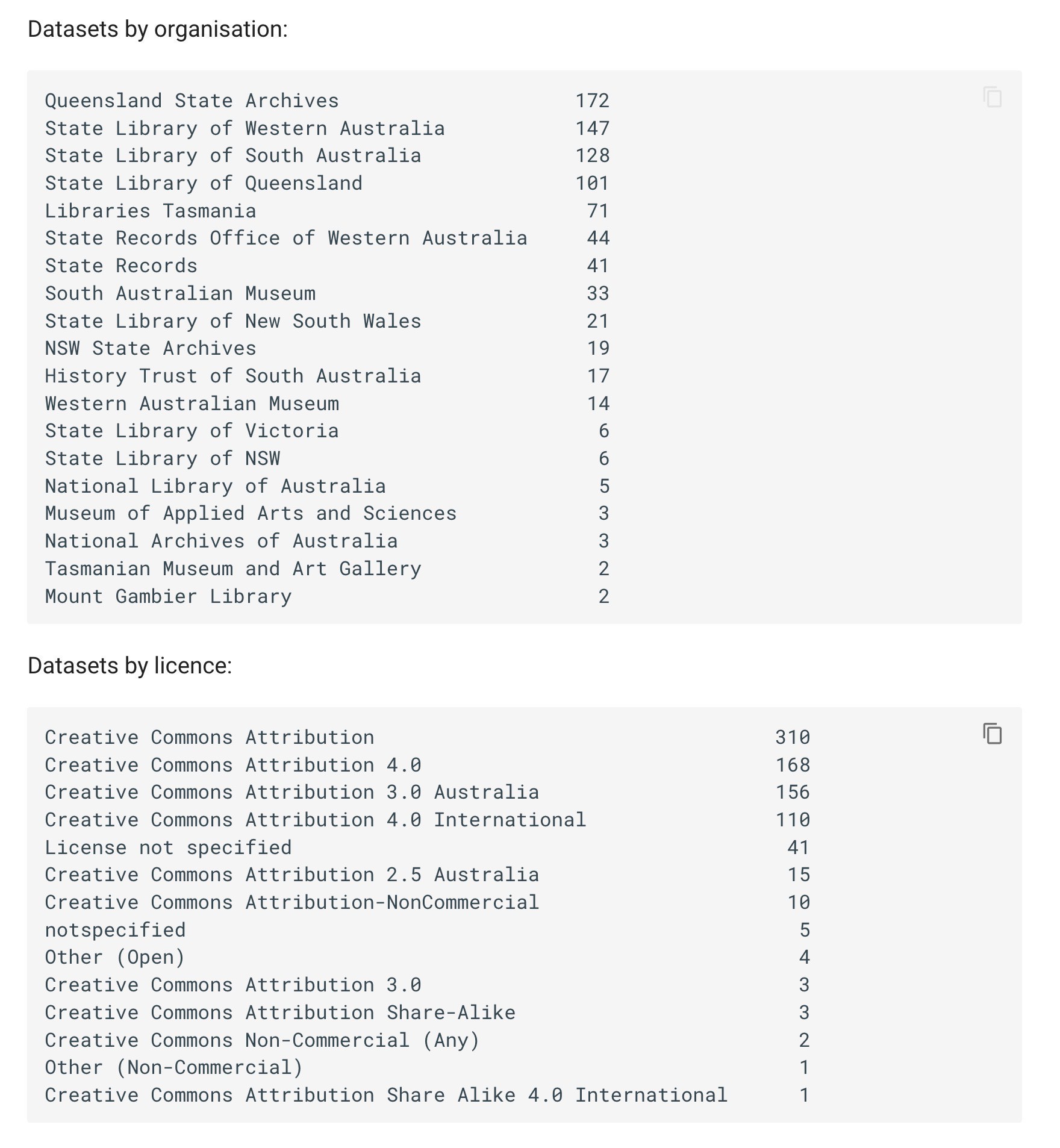
Some overdue updates to the GLAM Workbench. First here’s details, data, and code from a harvest of GLAM datasets on @datagovau. Includes details of more than 400 CSV datasets. #dhhacks
Over the last week I’ve been downloading editorial cartoons published in The Bulletin from @TroveAustralia. There’s 3,471 cartoons – at least one from every issue published between 4 Sep 1886 and 17 Sep 1952. And you can browse them all…
To make it easier to explore the images, I’ve compiled them into a series of PDFs – one PDF for each decade. The PDFs include lower resolution versions of the images together with their publication details and a link to Trove. They’re all available from DropBox:
The complete collection of high resolution images (about 60gb in total) can be downloaded from CloudStor. The names of each image file provide useful contextual metadata. For example, the file name 19330412-2774-nla.obj-606969767-7.jpg tells you:
19330412 – the cartoon was published on 12 April 19332774 – it was published in issue number 2774nla.obj-606969767 – the Trove identifier for the issue, can be used to make a url eg [nla.gov.au/nla.obj-6...](https://nla.gov.au/nla.obj-606969767)7 – on page 7There’s some details of the method that I used to find the cartoons in this notebook. I’ve also documented everything in the Trove Journals section of my GLAM Workbench.
Be warned – the language, images, and ideas presented in The Bulletin were often racist, anti-Semitic, and sexist. You won’t have to look far within this collection to find something offensive. This was, after all, the journal whose slogan for many years was ‘Australia for the white man’. This is our history… #dhhacks

After a number of unsuccessful attempts, I seem to be getting The Bulletin title art fairly reliably now. Tricky because it’s not always on the same page…

Here’s the notebook-ified version of the code I used to harvest all the Australian Commonwealth Hansard XML files from 1901 to 1980: nbviewer.jupyter.org/github/GL…
I’ve reharvested Commonwealth Hansard from 1901 to 1980 and updated my repository of XML files. This should pick up the work of @ParlLibrary staff over recent years to improve the XML output. #dhhacks
And now my GLAM Workbench has a ‘Trove Maps’ section to document examples and explorations using data from @TroveAustralia’s ‘map’ zone: glam-workbench.github.io/trove-map… Includes a list of 20,158 maps with high-res downloads. #dhhacks
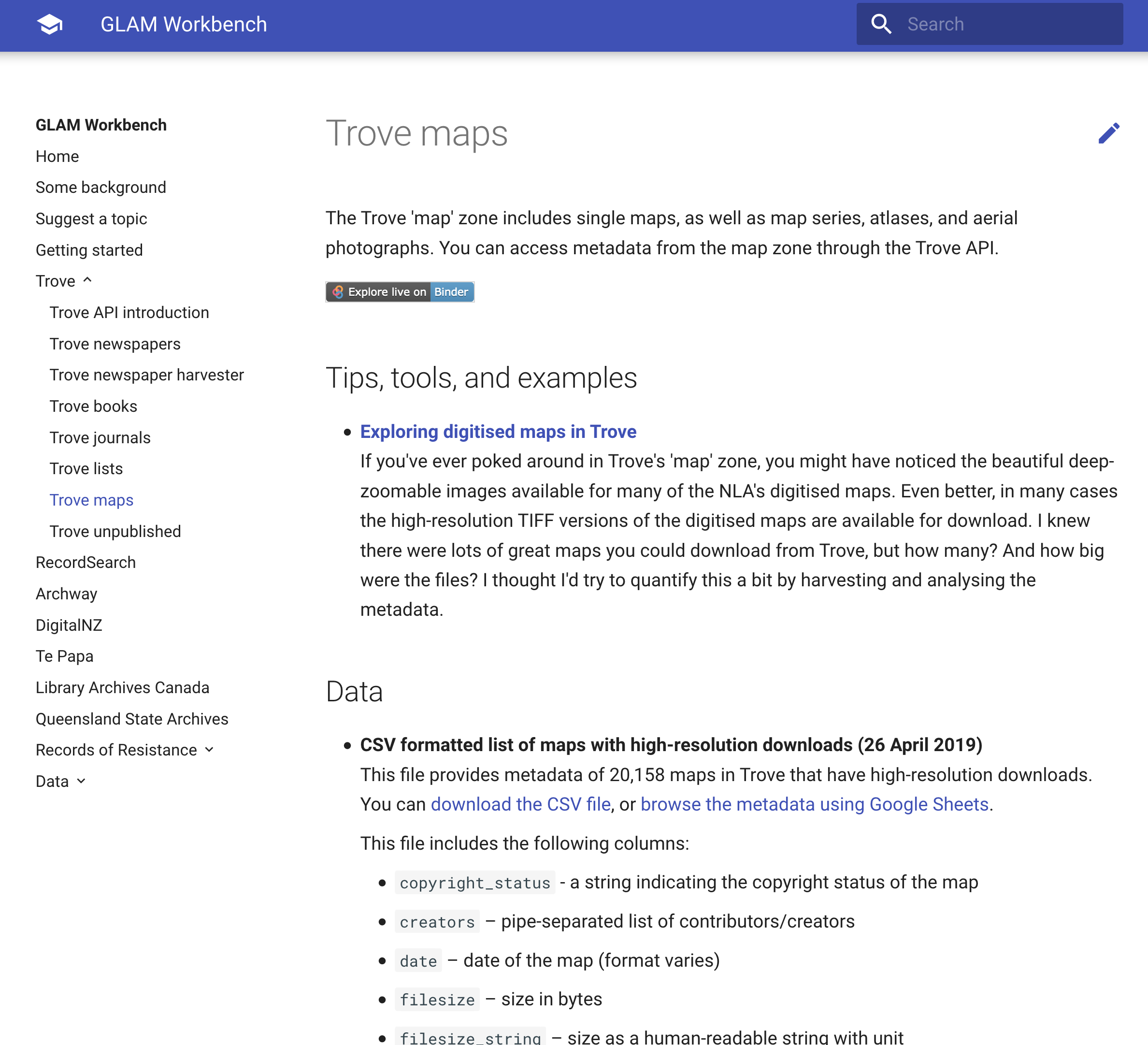
The other night @OpenGLAM was sharing collections of high-res images from GLAM orgs that are free to download. That got me thinking about @TroveAustralia’s digitised maps because there’s lots of them, most are out of copyright, and the images are BIG. #dhhacks
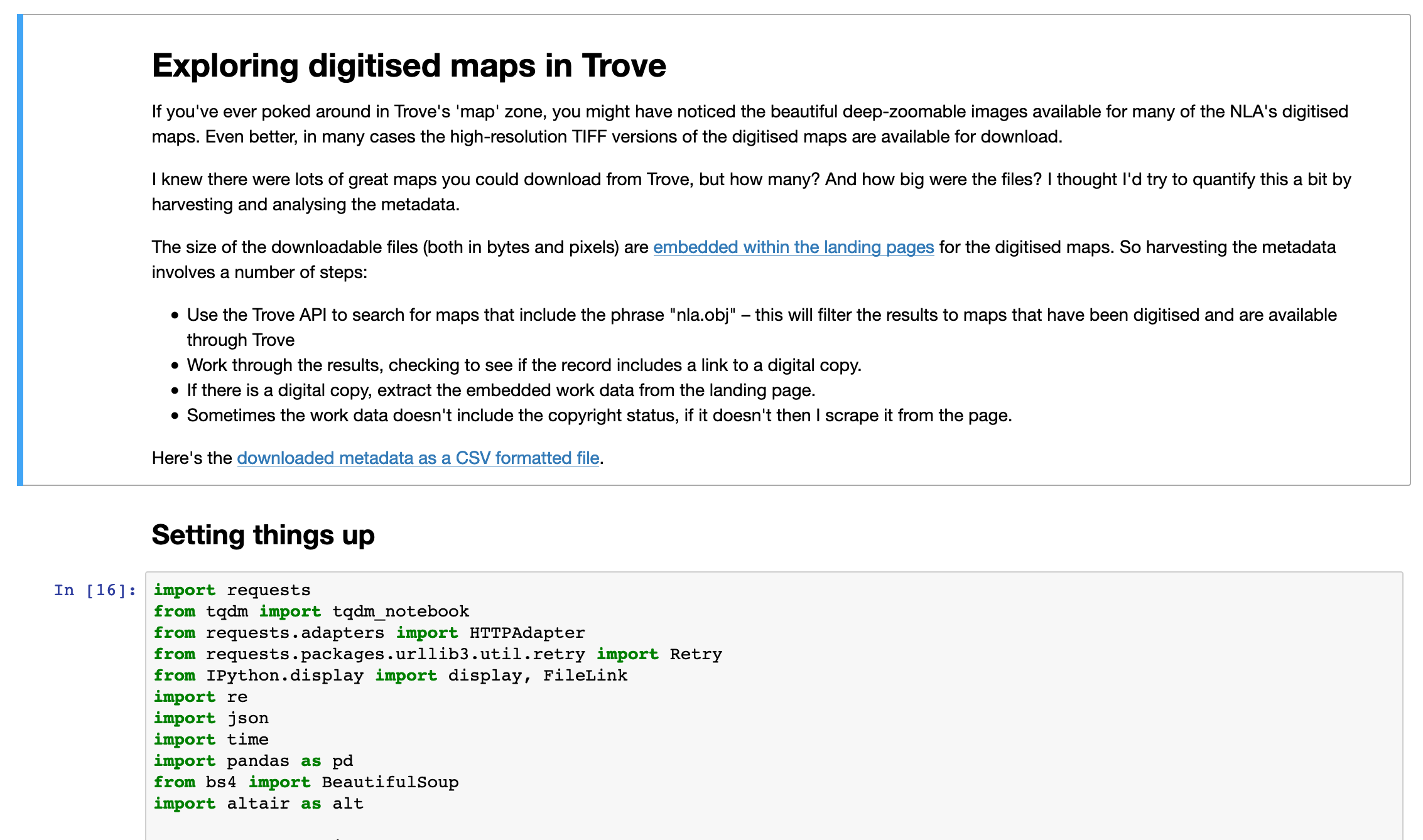
If you’d like to make your own big, composite images from lots of @TroveAustralia newspaper thumbnails, here’s a notebook that shows you how.
Australian pilots, aviators, airmen, and flyers — 4,950 thumbnails from a search in @TroveAustralia’s newspapers combined into one very big, zoomable image.

I’ve been busy lately harvesting LOTS of full text data from @TroveAustralia’s digitised journals – so many opportunities for research! You should be able to get to all the code & data from the new Trove journals section of my GLAM Workbench. #dhhacks
I’ve added a section for the @TroveAustralia ‘book’ zone to the GLAM Workbench.
Ok, so I’ve downloaded the OCRd text from 27,426 issues of 358 digitised journals/series in @TroveAustralia. That’s 6.6gb of full text. Tune in tomorrow for full details…
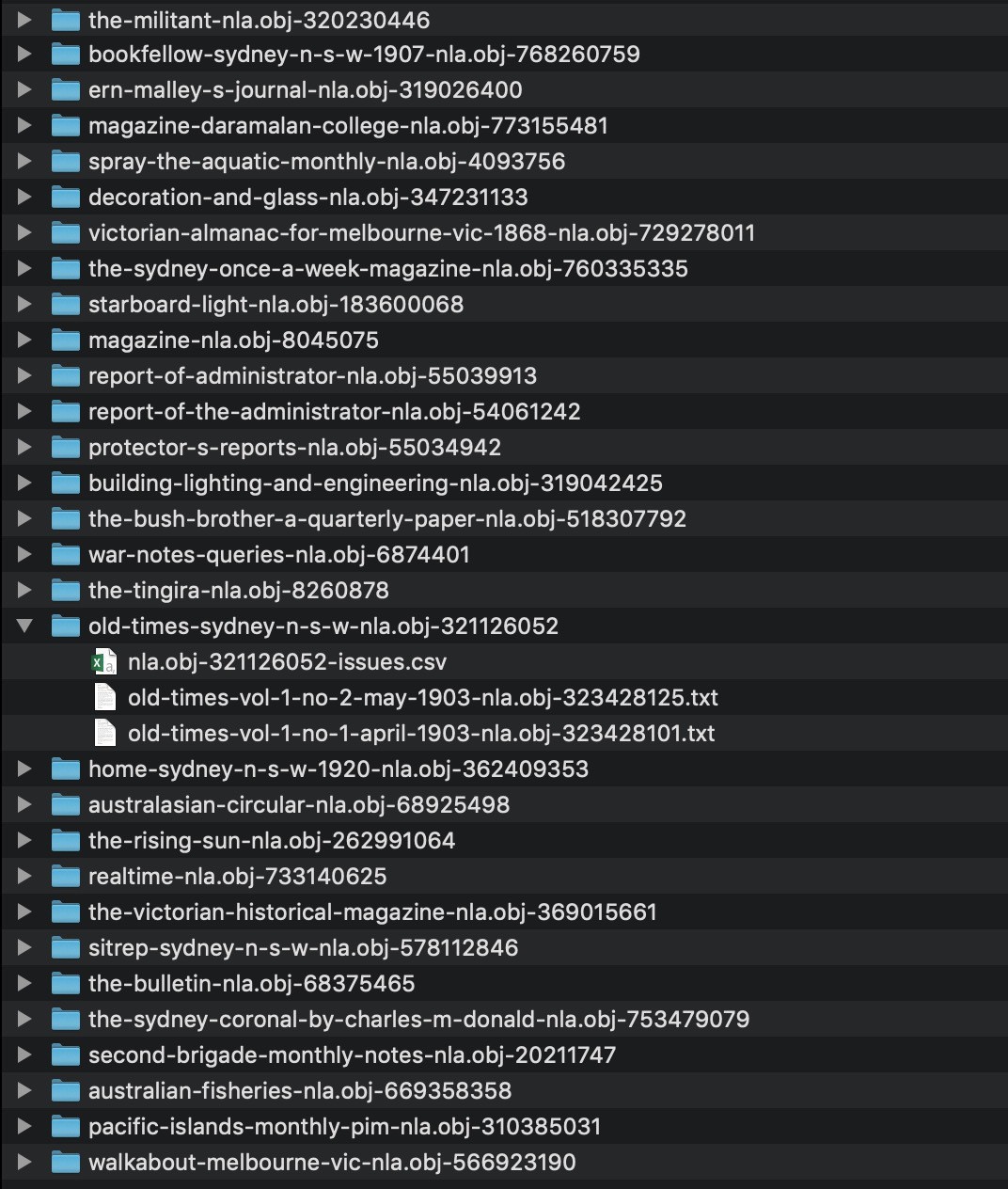
All 9,738 OCRd text files harvested from books, pamphlets and leaflets in @TroveAustralia’s ‘book' zone have been uploaded to @aarnet’s CloudStor for easy browsing/download. There’s also a 400mb zip file if you want the whole lot.
The harvesting method and code is available in this notebook. All this and more will be documented soon in my GLAM Workbench. #dhhacks
So @TroveAustralia includes more than 370,000 press releases, speeches, and interview transcripts issued by Aust federal politicians & saved by the Parliamentary Library. Learn how to harvest metadata & full text to create your own datasets in this notebook. #dhhacks

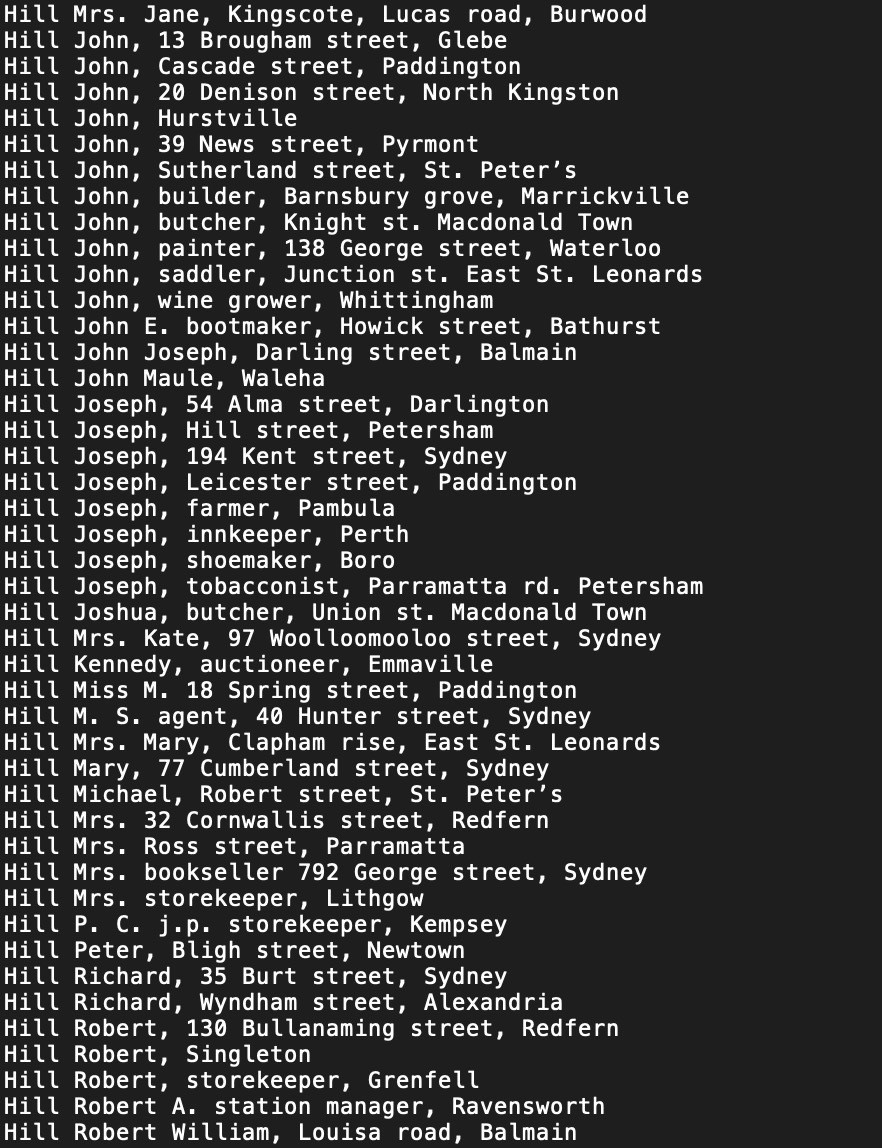
Among the OCRd texts I’m currently harvesting from Trove’s journals zone are things like the NSW Post Office Directories from 1886 onwards. Useful sources for compiling data about occupations, locations etc?
Wow, there are now over 371,000 press releases, interview transcripts and more from the @ParlLibrary available through @TroveAustralia. Just working on a new notebook to harvest sets for research…
Another collection of OCRd text from @TroveAustralia is on its way…
Playing with @TroveAustralia newspaper results. Here’s illustrated articles with ‘White Australia Policy' in their title…

The final tally – after much tweaking I’ve downloaded OCRd text from 9,738 works in the @TroveAustralia books zone. This includes ephemera such as pamphlets and posters as well as more booky books. Here’s the full metadata, all the text files, & harvesting code. #dhhacks
![mp-photo-alt[]=](https://cdn.uploads.micro.blog/8371/2019/9c8cd20e47.jpg)