In 2014 I pulled together a sample of web pages that included links back to digitised newspaper articles in Trove and created the ‘Trove Traces’ app. It was interesting, and sometimes disturbing, to see the diversity of sites that made use of Trove. Amongst the family and local history enthusiasts were climate change deniers and racists who found ‘evidence' for their views in past newspapers. And of course, the sample only includes links in web pages, not social media sharing.
I’ve added an API Query Builder to the DigitalNZ section of the GLAM Workbench. You can use it to learn about the different parameters available from the search API, and experiment with different queries. Just get your API key from DigitalNZ, then try entering keywords and selecting options. Once you understand how the API works, you can start thinking about how you can make use of it in your own projects.
Lately I’ve been updating and expanding the notebooks in the DigitalNZ section of the GLAM Workbench. In particular, I’ve been looking at the usage facet to understand how much of the aggregated content is ‘open’. What do I mean by ‘open’? The Open Knowledge Foundation definition states that ‘open data and content can be freely used, modified, and shared by anyone for any purpose’. Obviously things that are in the public domain, such as out-of-copyright resources, are open.
If you like browsing Trove’s digitised newspapers page by page, you might have found that the current interface is a bit clunky. To move between pages you have to hover over the page number and click on ‘Next’ or ‘Previous’. Wouldn’t it be good if you could just use the arrow keys on your keyboard? Well now you can!
I’ve created a very simple script that allows you to use the arrows on your keyboard to move between pages in Trove’s digitised newspapers.
There’s a new GLAM Workbench section for working with data from Trove’s Music & Sound zone!
Inside you’ll find out how to harvest all the metadata from ABC Radio National program records – that’s 400,000+ records, from 160 Radio National programs, over more than 20 years.
It’s metadata only, so not full transcripts or audio, though there are links back to the ABC site where you might find transcripts. Most records should at least have a title, a date, the name of the program it was broadcast on, a list of contributors, and perhaps a brief abstract/summary.
There are a growing number of non-English newspapers in Trove, but how do you know what’s there? After trying a few different approaches, I generated a list of 48 newspapers with non-English content. The full details are in this notebook).
As the notebook describes, I found the language metadata for newspapers was incomplete, so I used some language detection code on a sample of articles from every newspaper to try and find those with non-English content.
Last year I did some analysis of the availability of open access versions of research articles published between 2008 and 2018 in Australian Historical Studies. I’ve now broadened this out to cover all individual articles (with a DOI) across a number of journals. It’s pretty grim. Despite Green OA policies that allow researchers to share versions of their articles through institutional repositories, Australian history journals still seem to be about 94% closed.
A long thread exploring files in the National Archives of Australia with the access status of ‘closed’. This is the 6th consecutive year I’ve harvested ‘closed’ files on or about 1 January.
It’s January 1, the day each year when our minds turn to newly released Cabinet records from @naagovau. But while the media focuses on the records that have been made open, I’ll be spending the day looking at those that were closed. What weren’t you allowed to see in 2020?
More updates from The Real Face of White Australia – running facial detection code over NAA: SP42/1.
Finished! NAA: SP42/1 is a general correspondence series from the Collector of Customs in Sydney. It includes many files relating to the administration of the White Australia Policy. 3,375 files have been digitised (about 20% of the series), that’s 49,781 digital images. https://t.co/Y1ZoAYSXeP
I reharvested NAA: ST84/1 and ended up with 14,545 images from 461 digitised files (about 17% of the total series).
In these images I found 9,970 faces – this is a couple of thousand more than when I used OpenCV in 2010/11 for the original wall of faces. https://t.co/BAnkX7u83S
Asking questions with web archives – introductory notebooks for historians has won the British Library Labs Research Award for 2020. The awards recognise ‘exceptional projects that have used the Library’s digital collections and data’.
This project gave me a chance to work with web archives collections and staff from the British Library, the National Library of Australia, and the National Library of New Zealand, and was supported by the International Internet Preservation Consortium’s Discretionary Funding Program.
Want to relive the early days of digital humanities in Australia? I’ve archived the websites created for THATCamp Canberra in 2010, 2011, and 2014. They’re now static sites so search and commenting won’t work, but all the content should be there! #dhhacks
The Invisible Australians website has been given a much needed overhaul, and we’ve brought all our related projects together under the title The real face of White Australia. This includes an updated version of the wall of faces. #dhhacks
Repositories in the GLAM Workbench have been launched on Binder 3,529 times since the start of this year (according to data from the Binder Events log). That’s repository launches, not notebooks. Having launched a repository, users might use multiple notebooks. And of course these stats don’t include people using the notebooks in contexts other than Binder – on their own machines, servers, or services like AARNet’s SWAN. Or just viewing the notebooks in GitHub and copying code into their own projects.
Earlier this year I gave a seminar for the International Internet Preservation Consortium (IIPC) introducing the web archives section of the GLAM Workbench. The seminar is now available online: youtu.be/rVidh_wex…
Here are the slides if you want to follow along. #dhhacks
The Trove Newspaper & Gazette Harvester has been updated to version 0.4.0. The major change is that if the OCRd text for an article isn’t available through the API, it will be automatically downloaded via the web interface. What does this mean in practice? Well previously you couldn’t harvest OCRd text from the Australian Women’s Weekly because it’s not included in API results, but now you can!
You don’t need to do anything differently.
If you’ve done any searching in Trove’s digitised newspapers, you’ve probably noticed that there aren’t many results after 1954. This is basically because of copyright restrictions (though given the complexities of Australia’s copyright system, you can’t be sure that everything published before 1955 is out of copyright). We can visualise the impact of this by looking at the number of newspaper articles in Trove by year.
You can see why I started referring to it as the copyright cliff of death.
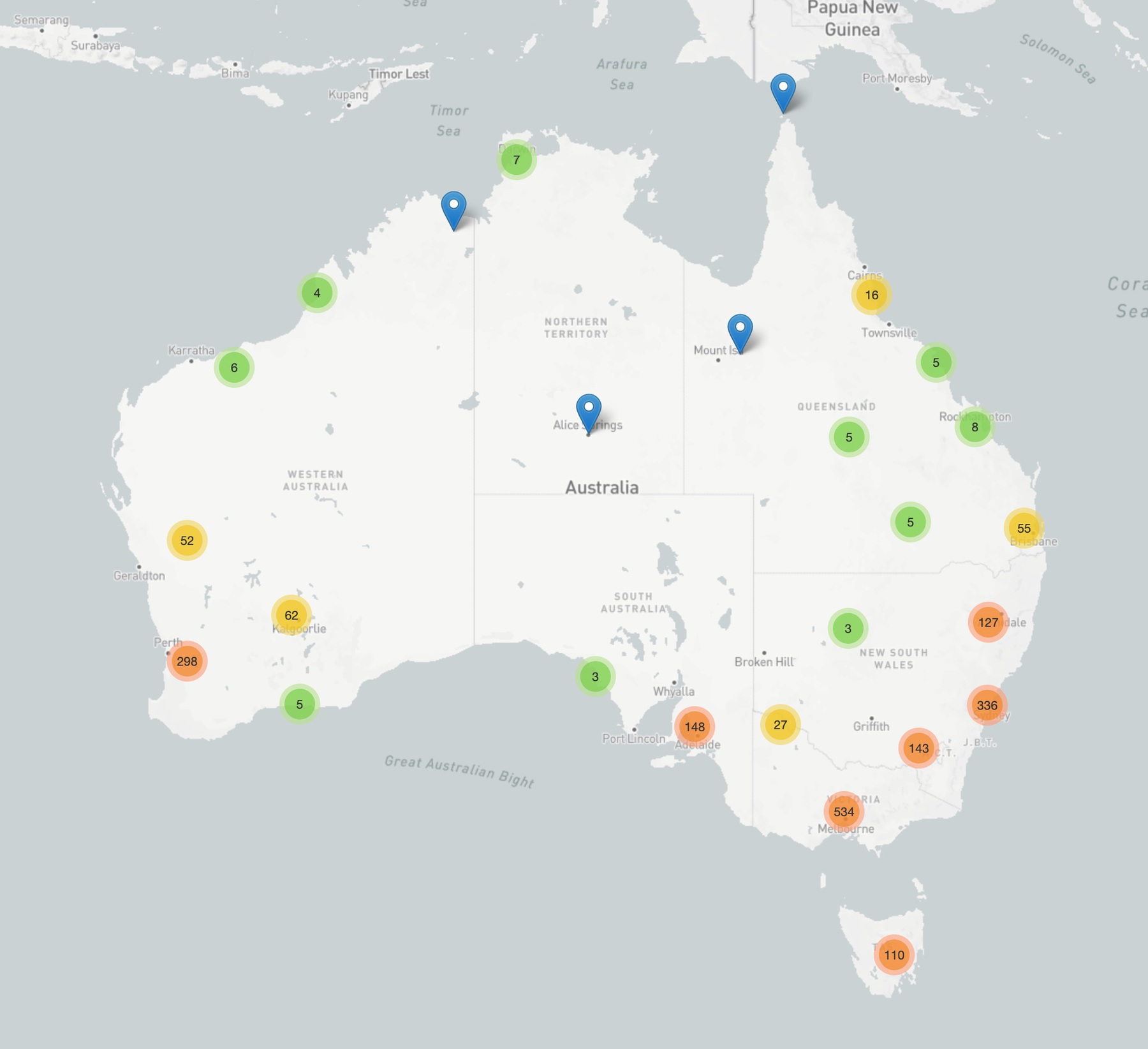
Updated! Find Trove newspapers by place of publication by using this simple interface – just click on the map to find the 10 closest newspapers. Now including newspapers added to Trove since June.
The underlying data file is available as a spreadsheet. Feel free to add a comment if you notice any problems. I’m geolocating place names found in newspaper titles, so it’s not always exact.
These are large format bound volumes of the official lists that were posted up for the public to see - 3 times a day - forenoon, noon and afternoon - at the close of the trading session in the call room at the Sydney Stock Exchange. The closing prices of stocks and shares were entered in by hand on pre-printed sheets.
The volumes have been digitised, resulting in a collection of 70,000+ high resolution images. You can browse the details of each volume using this notebook.
I’ve been exploring ways of getting useful, machine-readable data out of the images. There’s more information about the processes involved in this repository. I’ve also been working on improving the metadata and have managed to assign a date and session (Morning, Noon, or Afternoon) to each page. We these, we can start to explore the content!
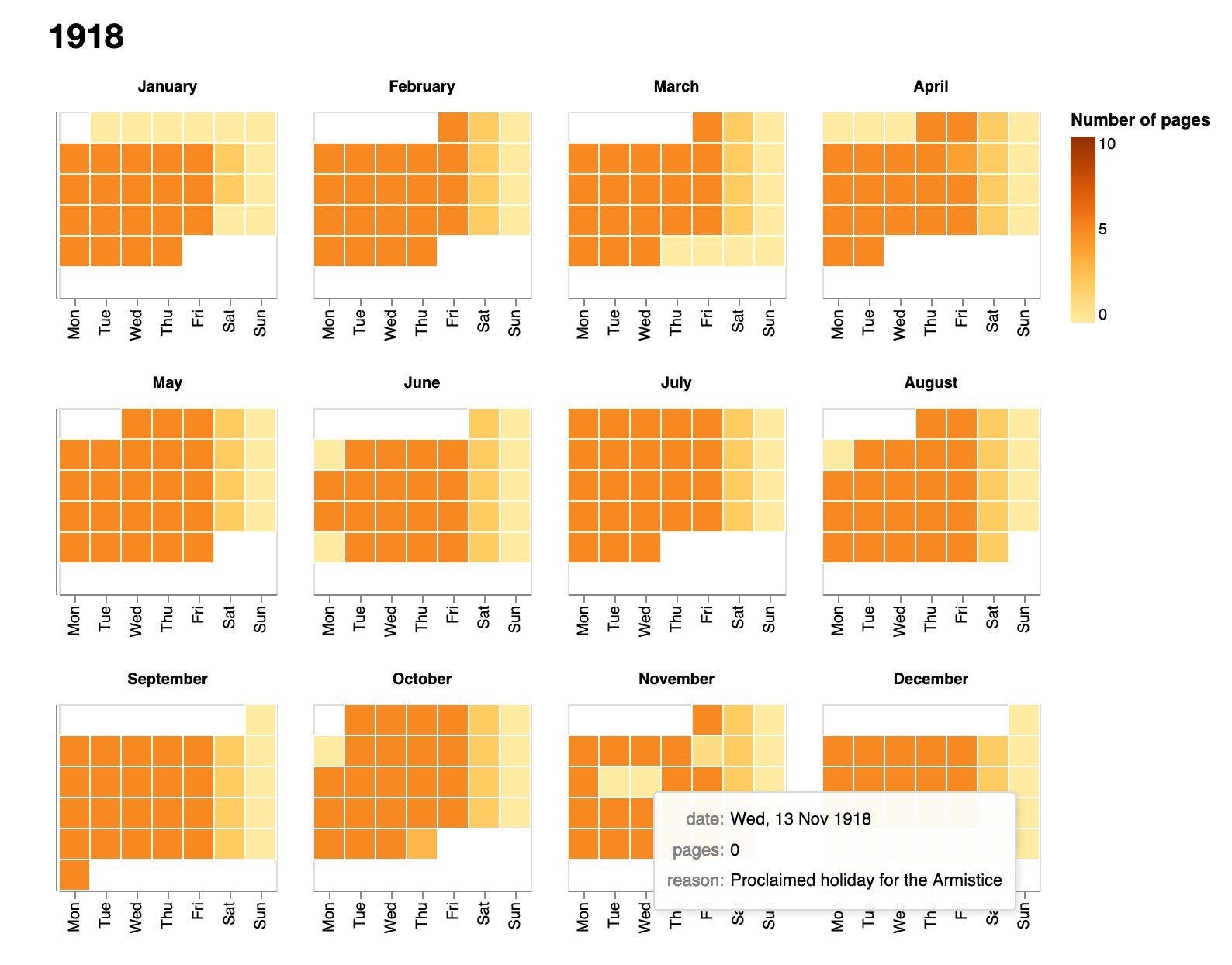
One of the notebooks creates a calendar-like view of the whole collection, showing the number of pages surviving from each trading day. This makes it easy to find the gaps and changes in process. #dhhacks
Any regular user of RecordSearch, the National Archives of Australia’s online database, will understand its frustrations. But here’s a handy little hack to fix a couple of annoying problems and add some useful functionality!
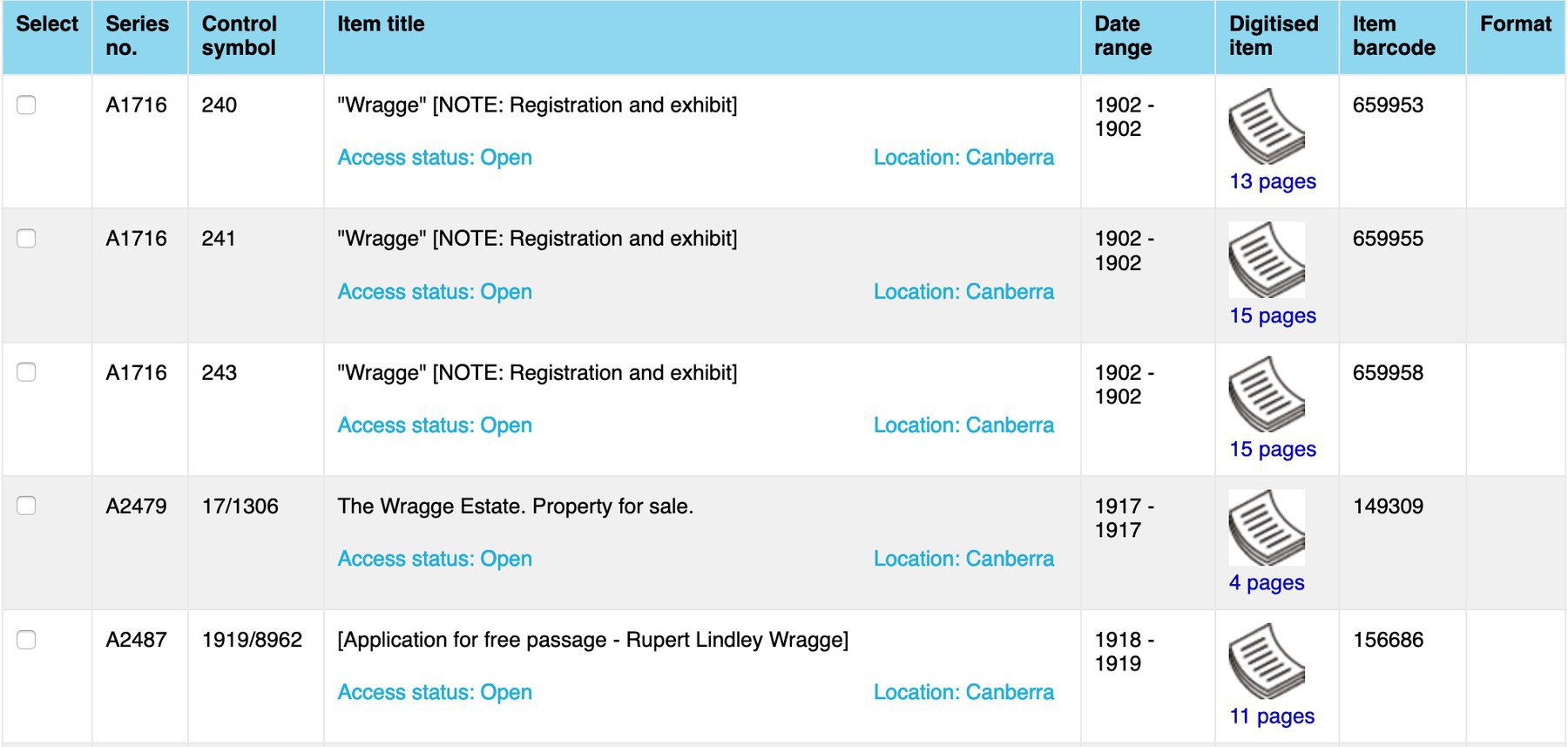
The RecordSearch Show Pages userscript updates links to digitised files in search results and item details pages, inserting the number of pages in a file. This means that you can easily scan a list of search results to see where the big fat files are, without having to click through to each one individually.
But wait there’s more! The script also rewrites the link to the digitised file viewer so that it opens in the current tab, as you would expect, and not in an annoying pop up window!
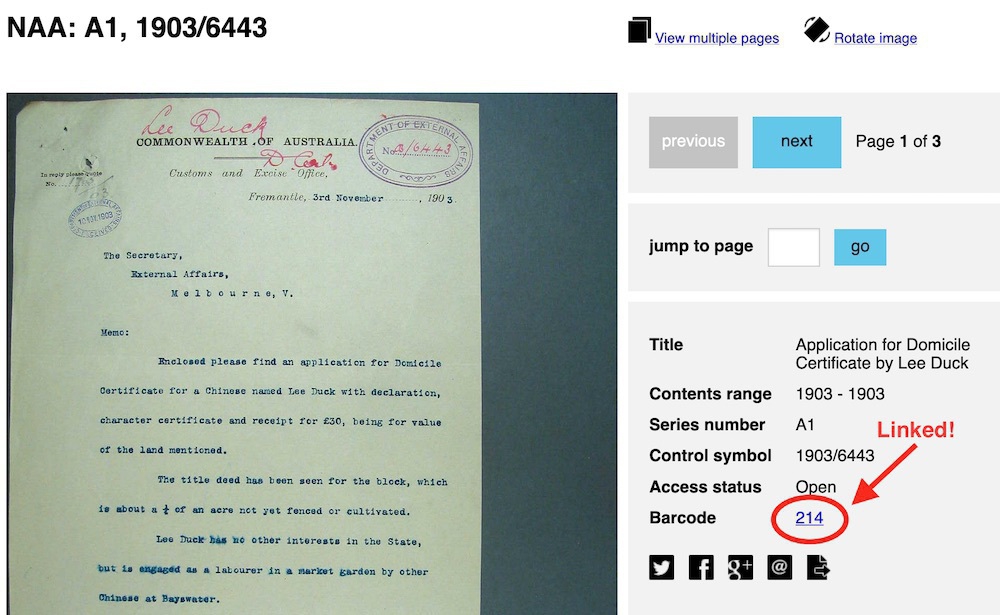
And as an extra bonus if you install now, the script also inserts a link on the barcode of an item in the digitised file viewer that takes you back to the item details page. Links to the digitised file viewer are shareable (unlike most RecordSearch links), but they don’t give you a way to find more information about the item. That problem is also fixed by this handy little script.