Any regular user of RecordSearch, the National Archives of Australia’s online database, will understand its frustrations. But here’s a handy little hack to fix a couple of annoying problems and add some useful functionality!
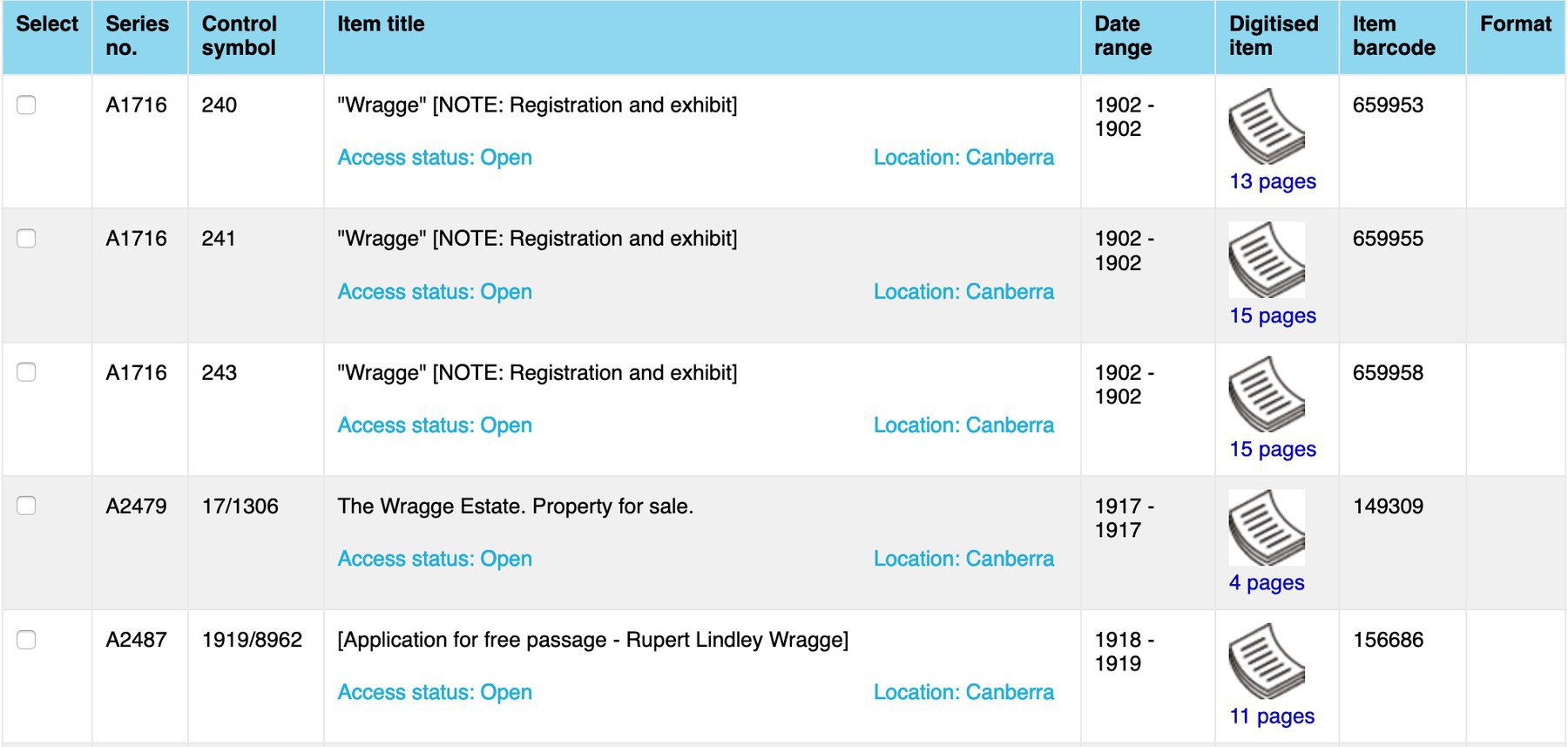
The RecordSearch Show Pages userscript updates links to digitised files in search results and item details pages, inserting the number of pages in a file. This means that you can easily scan a list of search results to see where the big fat files are, without having to click through to each one individually.
But wait there’s more! The script also rewrites the link to the digitised file viewer so that it opens in the current tab, as you would expect, and not in an annoying pop up window!
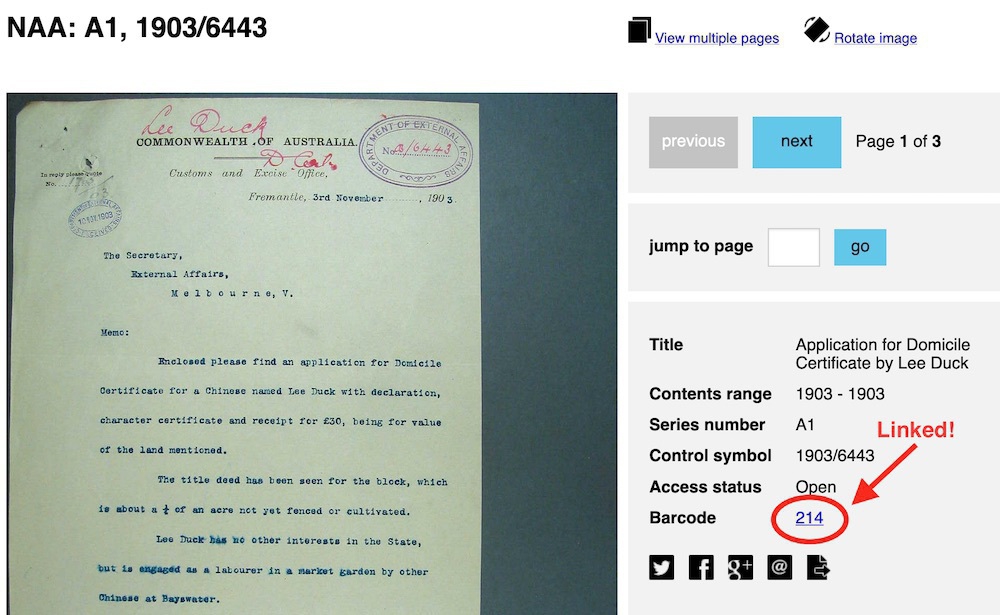
And as an extra bonus if you install now, the script also inserts a link on the barcode of an item in the digitised file viewer that takes you back to the item details page. Links to the digitised file viewer are shareable (unlike most RecordSearch links), but they don’t give you a way to find more information about the item. That problem is also fixed by this handy little script.
I’ve added more years to my repository of Commonwealth Hansard! The repository now includes XML-formatted text files for both houses from 1901 to 1980, and 1998 to 2005. I’ve done some more checking and confirmed that the XML files for 1981 to 1997 aren’t currently available through ParlInfo, however, the Parliamentary Library are looking into it. I’ve also created a CSV-formatted list of sitting days from 1901 to 2005 (based on ParlInfo search results). Details of the harvesting process are available in the GLAM Workbench. #dhhacks
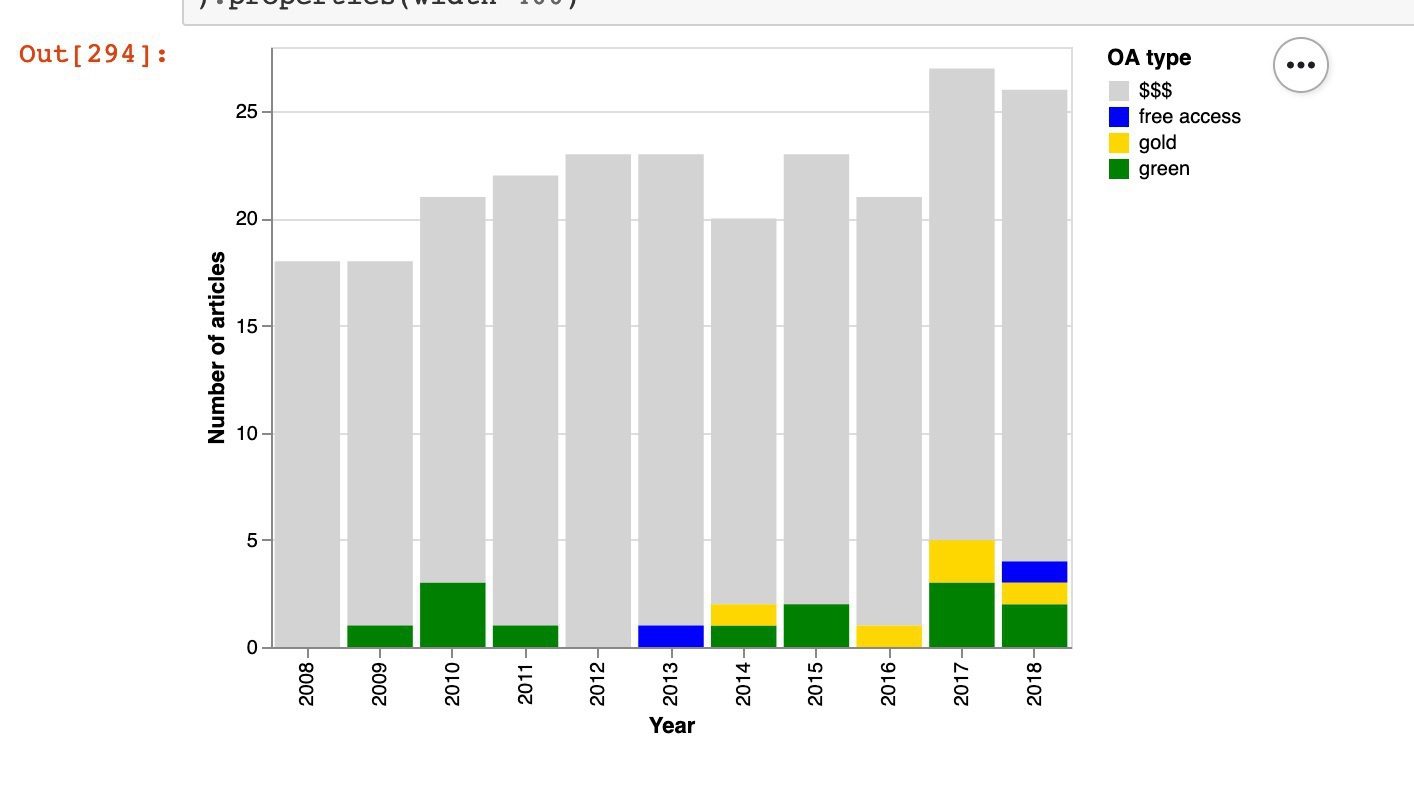
It was Open Access Week last week, so I tried a little experiment. How many research articles published in Australian Historical Studies between 2008 and 2018 are available via Open Access? Just 9.5% (23 out of 242). This is despite the fact that all articles published in 2018 or earlier are outside of the journal’s embargo period and Green OA versions could be shared through repositories.
Calling users of Australian galleries, libraries, archives, & museums – OzGLAM Help is now live! Ask a question or simply share your latest discoveries. There’s handy tips, news about recent developments, & links to useful tools. Please use & share! #dhhacks
The Zotero translator for RecordSearch (the National Archives of Australia’s online database) has been updated. There’s many fixes and enhancements — see the full details. #dhhacks
If you try to share or bookmark the url of an item in RecordSearch (the National Archives of Australia’s online database), you’ll often get a ‘Session time out’ error when you access it. That’s because the urls only work within the current active RecordSearch session. So how can you create a shareable link that works across sessions? I’ve created a simple app that helps you create shareable links: recordsearch-links.glitch.me #dhhacks
The Zotero translator for Trove was failing on newspaper articles with tags. I’ve submitted a fix for approval: github.com/zotero/tr…
I’m not sure yet whether the capture of works and search results can be fixed following the Trove redesign. React is not very scraper friendly…
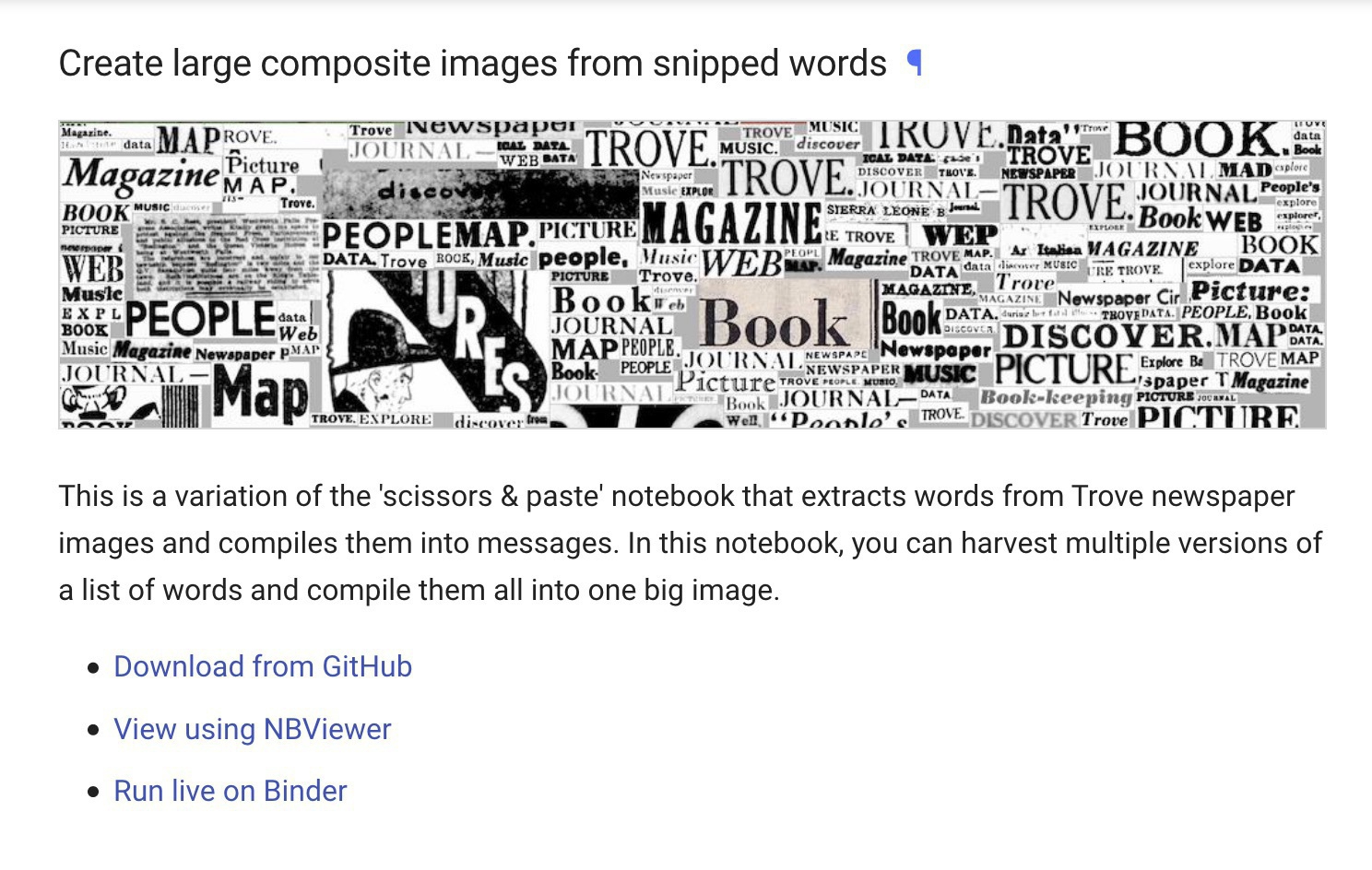
Another #GLAMWorkbench update! Snip words out of @TroveAustralia newspaper pages and create big composite images. OCR art! glam-workbench.github.io/trove-new… #dhhacks
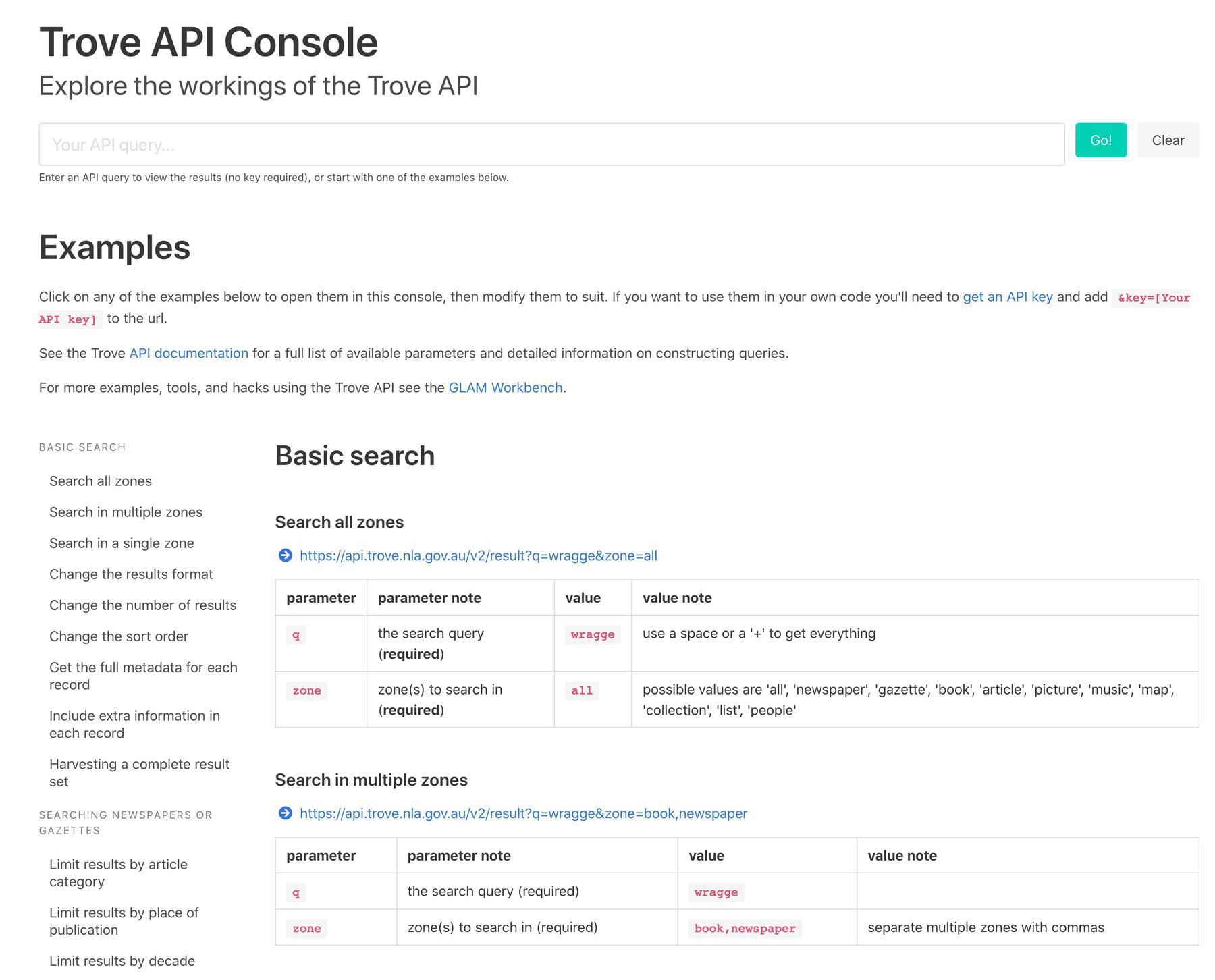
Just in time for #GovHack, I’ve given the Trove API Console a major overhaul. It’s been updated for the latest API versions and has MANY MANY more examples. Explore all the data you can get from @TroveAustralia! troveconsole.herokuapp.com #dhhacks
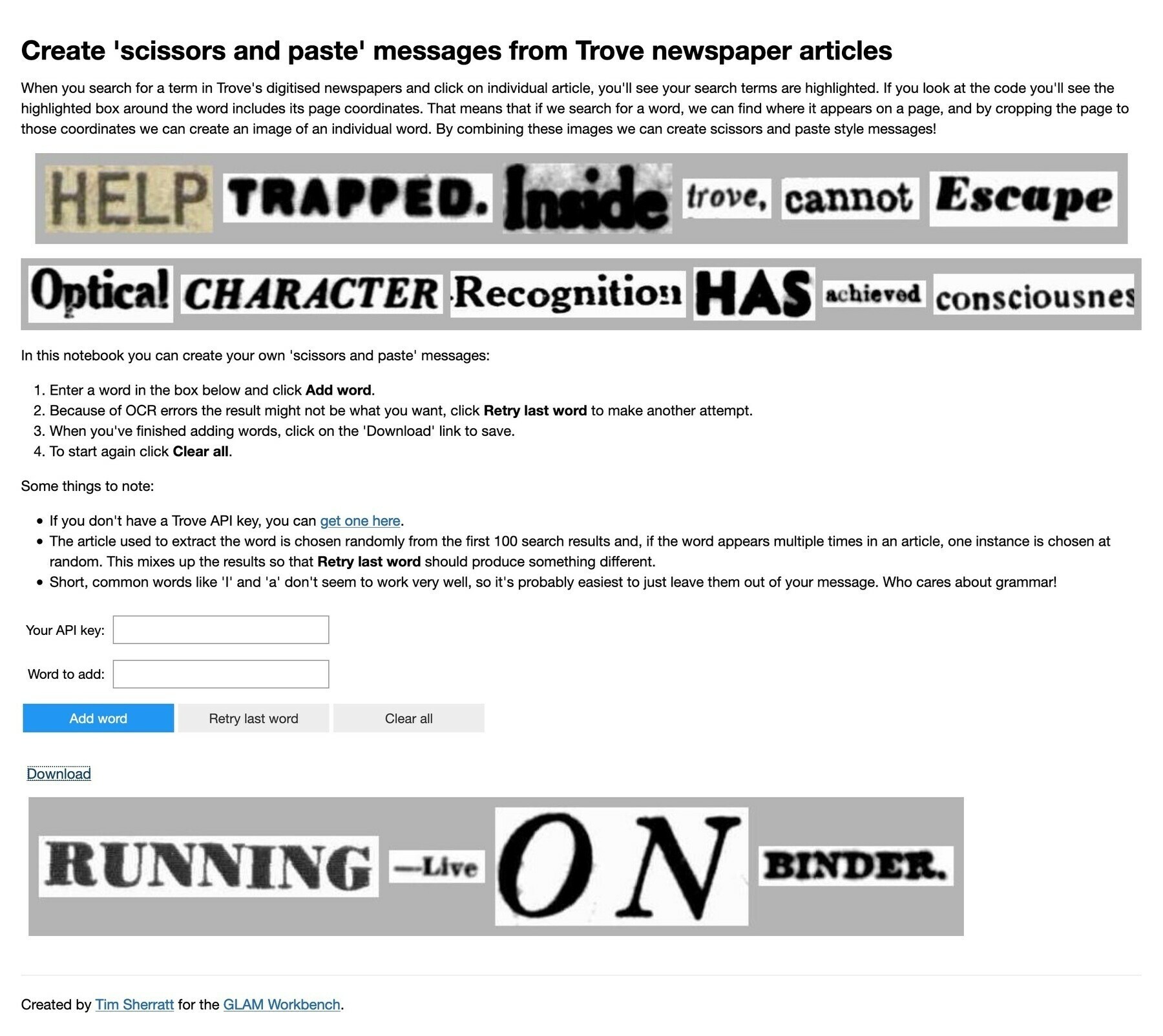
Ok, so do you want to make your own ‘scissors & paste’ messages using words from @TroveAustralia newspaper articles? Go to the notebook in #GLAMWorkbench & click on ‘Run live on Binder in Appmode’. #dhhacks
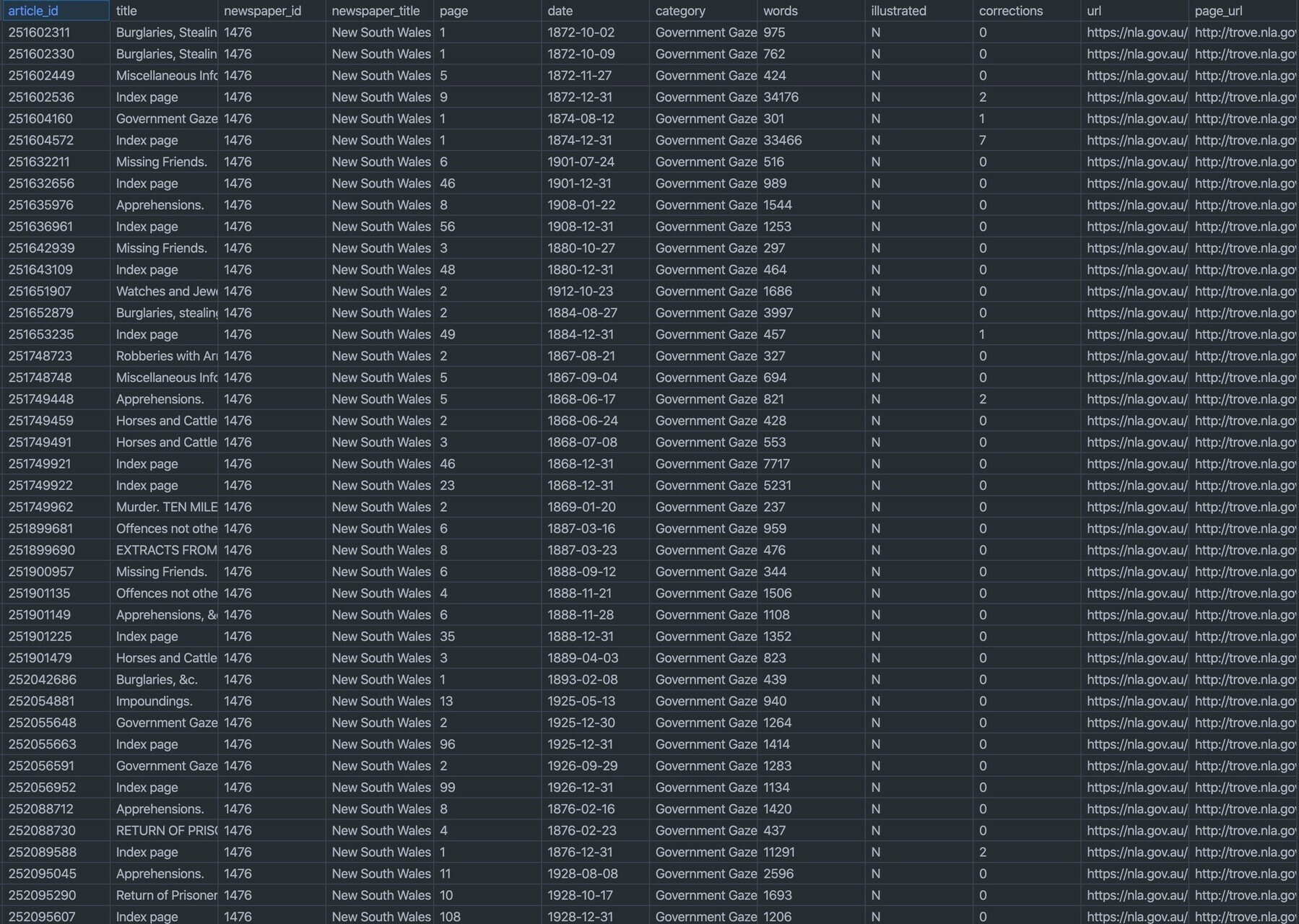
Another #GLAMWorkbench update! The Trove Harvester will now download both newspaper and gazette articles in bulk. You can optionally include full text, and save copies of the articles as images and PDFs. #dhhacks glam-workbench.github.io/trove-har…
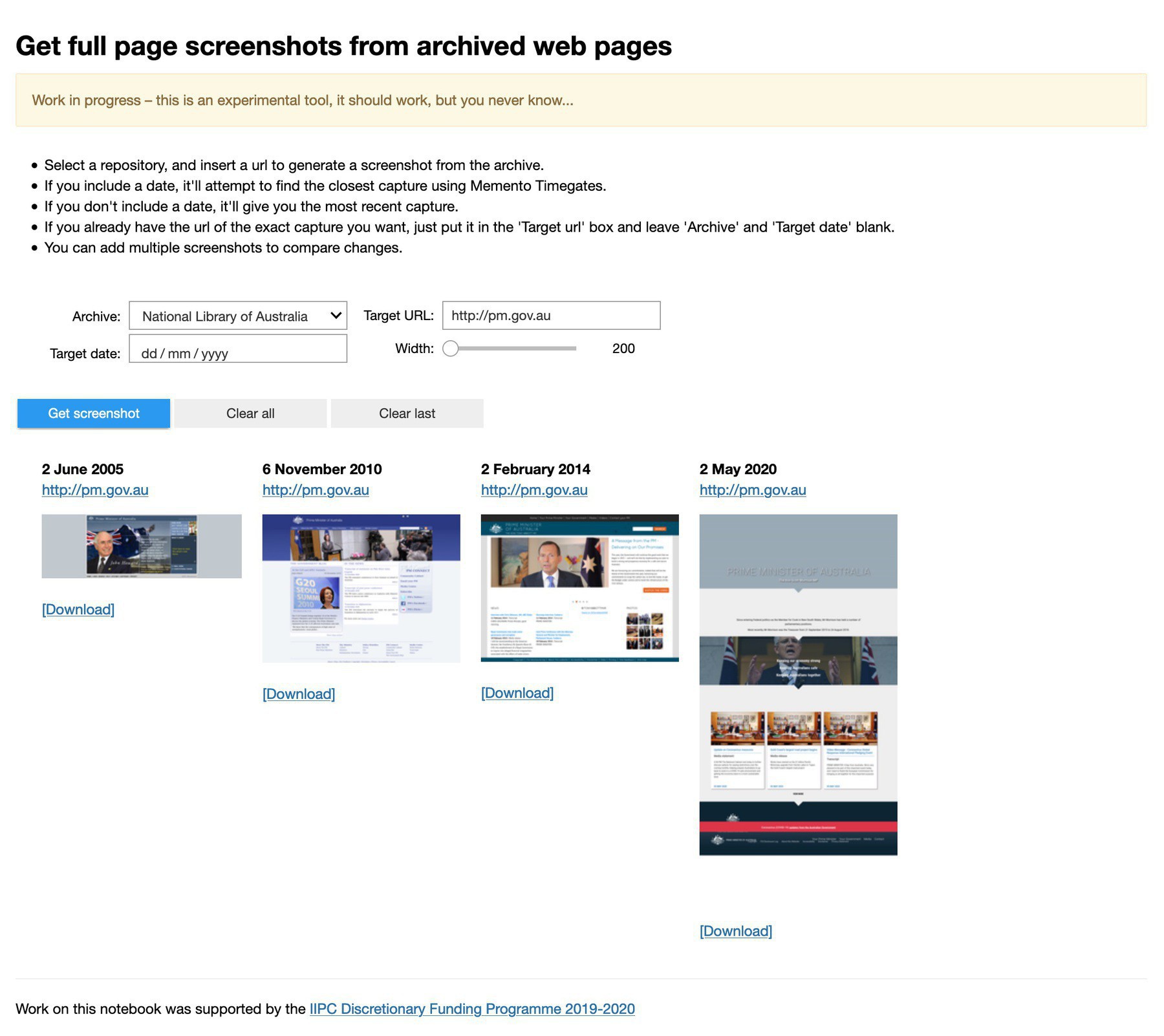
Interested in using web archives in your research? Join us on 5/6 August for a free @netpreserve webinar introducing the tools and examples available in the new #webarchives section of the #GLAMWorkbench. There are two timeslots to cover multiple timezones: www.eventbrite.com/e/iipc-rs… and www.eventbrite.com/e/iipc-rs…
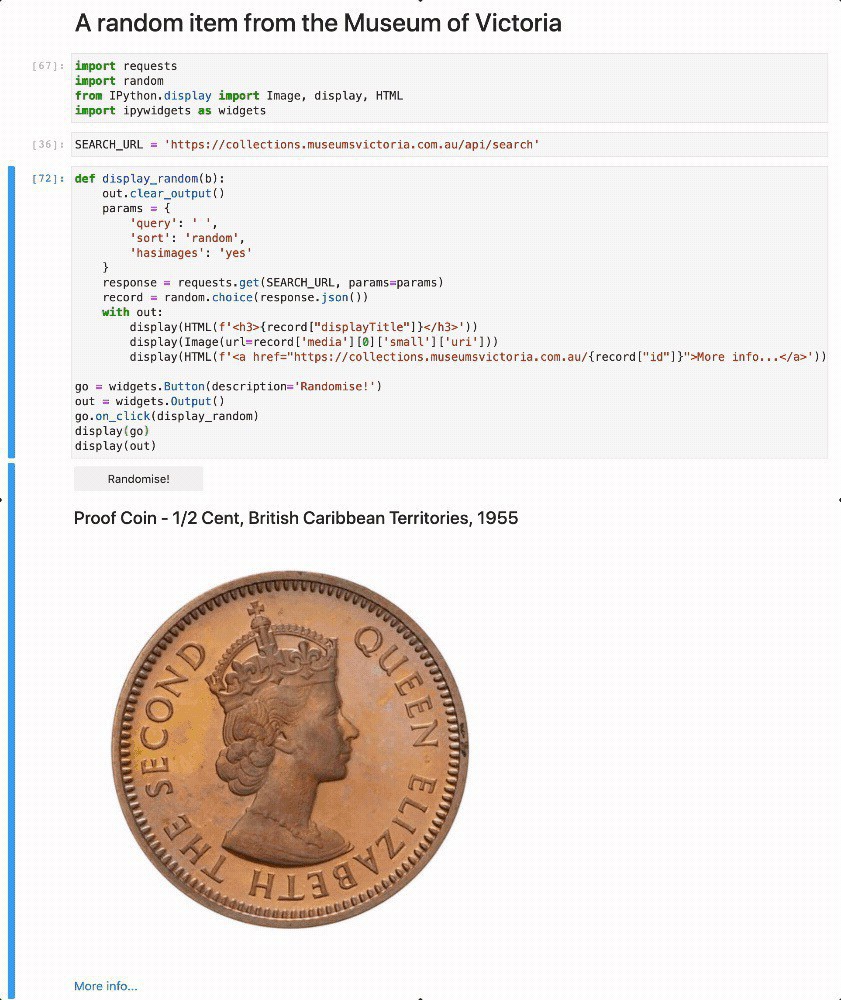
Introducing a brand new section of the #GLAMWorkbench, exploring the @MuseumsVictoria collection API. Harvest species records, display random images, and download ALL THE ANTECHINUSES! glam-workbench.github.io/museumsvi… #dhhacks
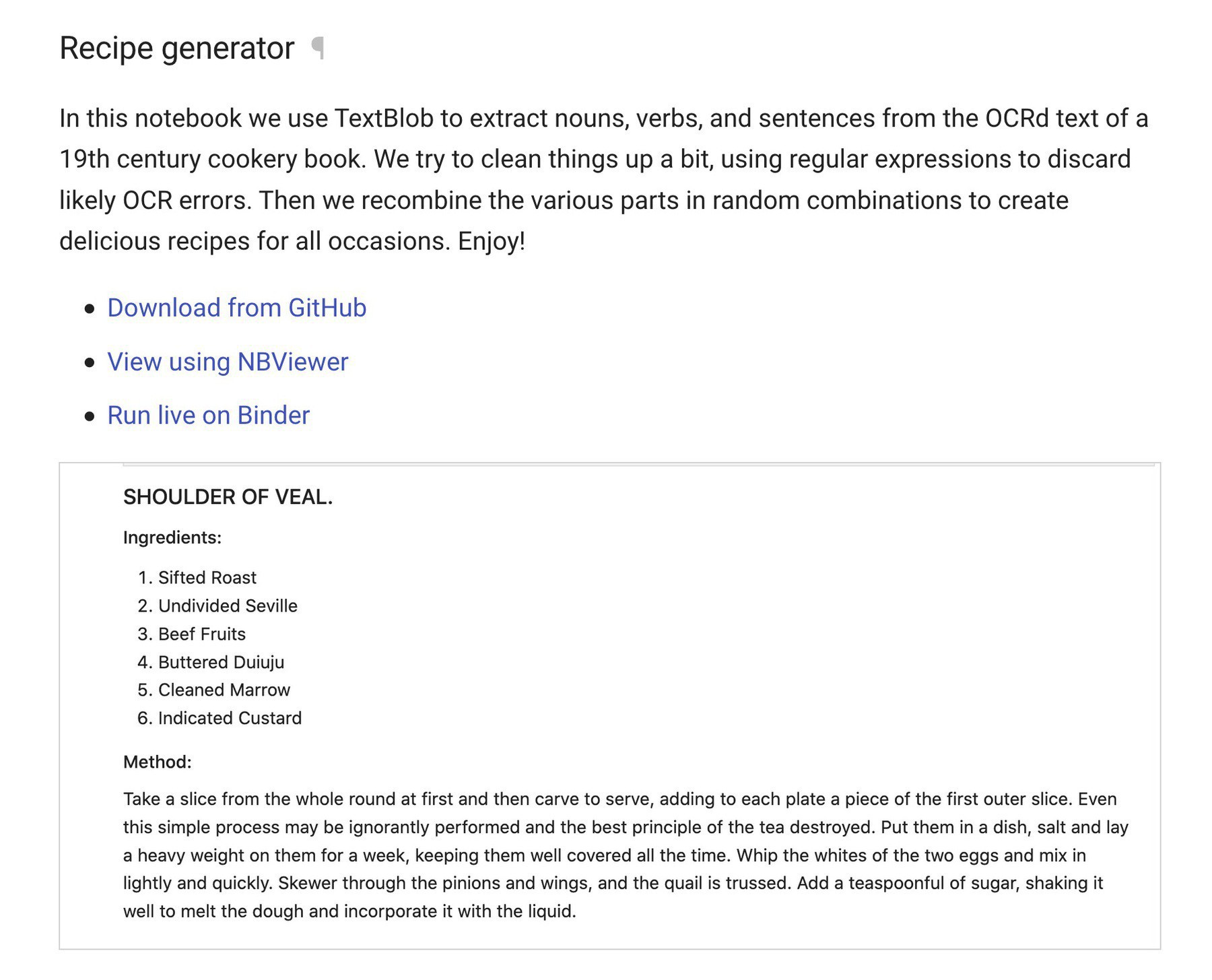
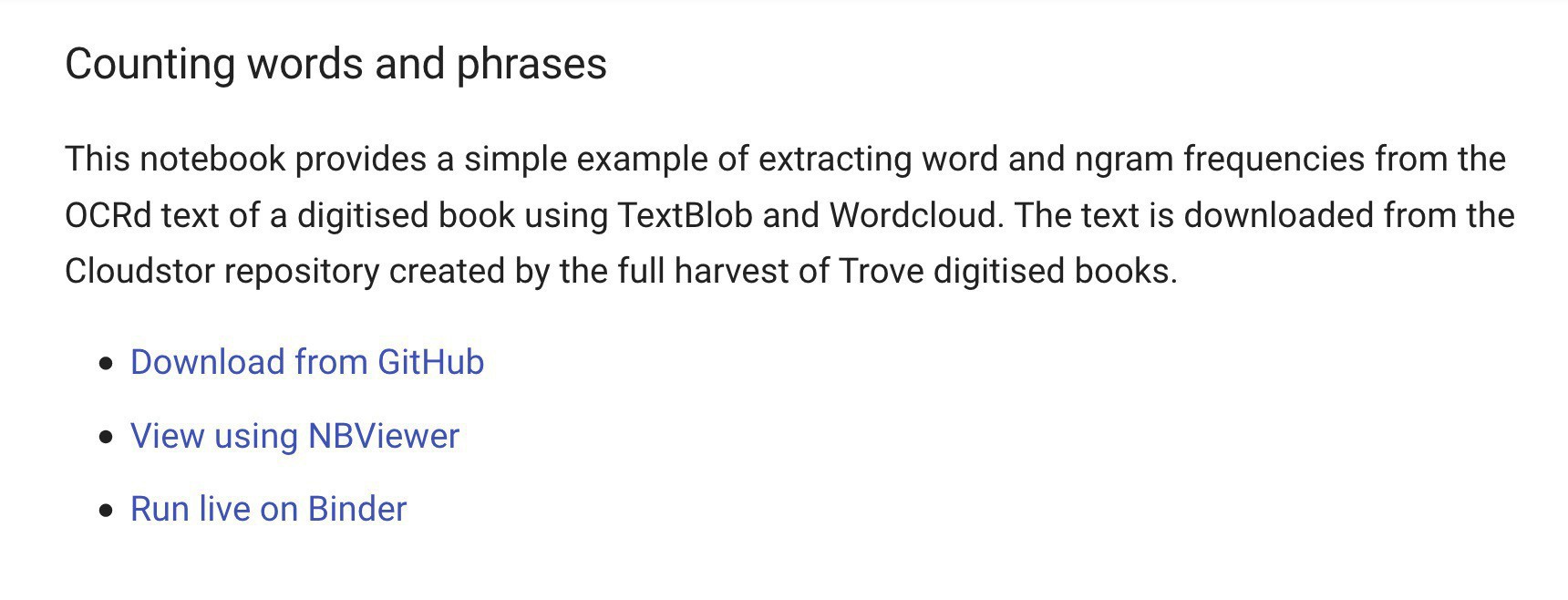
New additions to the @TroveAustralia books section of the #GLAMWorkbench – word frequency examples with OCRd text from digitised books, and a random recipe generator powered by a 19th C cook book! glam-workbench.github.io/trove-boo… #dhhacks
With the recent changes to @TroveAustralia, the Australian Women’s Weekly cover browser was retired. As a low-tech alternative, I’ve harvested all the cover images from the Women’s Weekly and saved them into PDFs for easy browsing, one for each decade. There are 2,566 images from 1933 to 1982.
Just click on the link below each image to explore the complete issue on Trove. You can also download the full collection of images from Cloudstor. There’s a CSV file containing all the issue metadata.
The notebook used to harvest the images is in the Trove newspapers section of the GLAM Workbench. You could easily adapt the notebook to harvest the front pages of any newspaper. #dhhacks
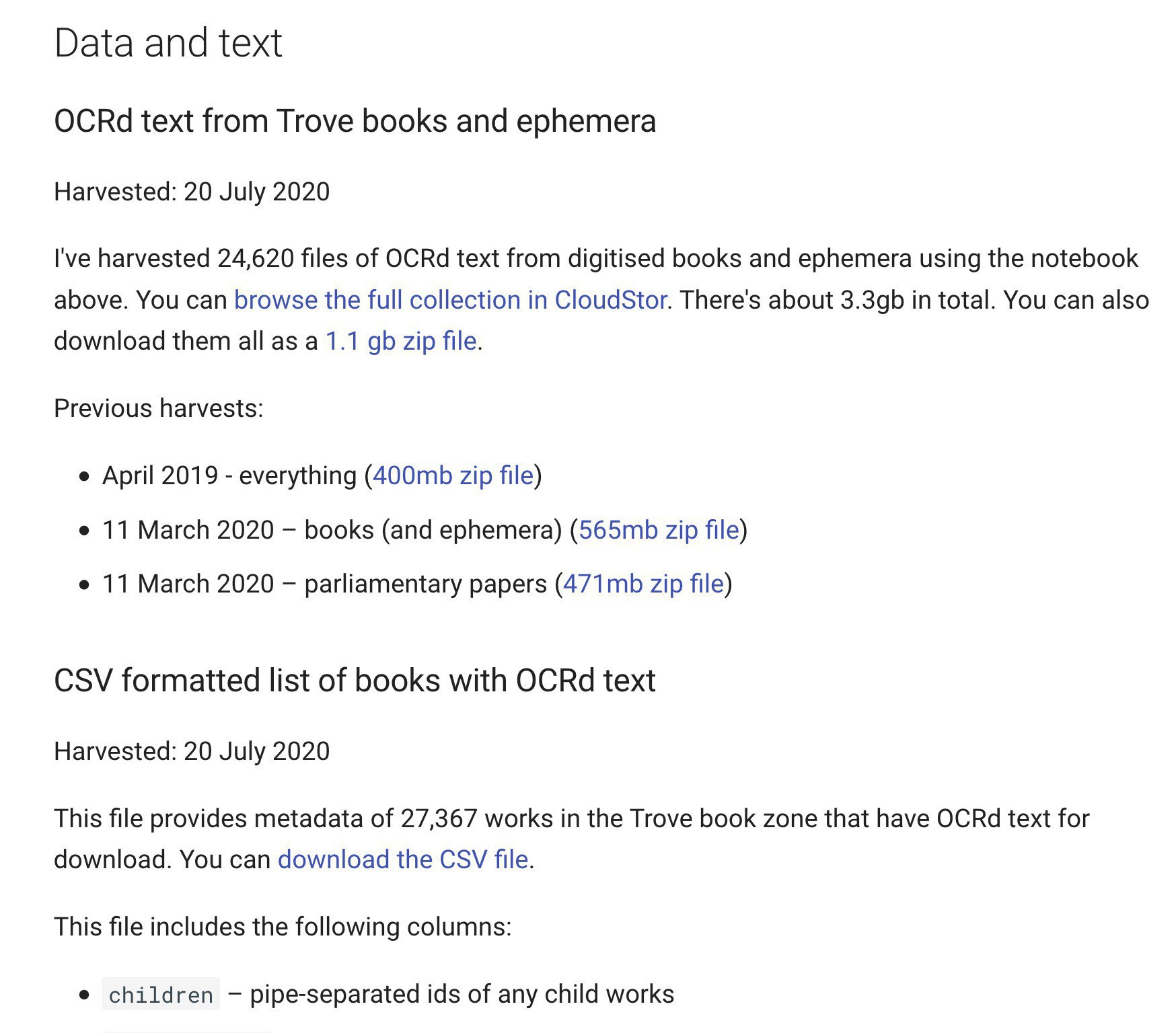
The Trove books section of the #GLAMWorkbench has been updated. There’s a fresh harvest of OCRd text & the notebooks have been changed to work with the new @TroveAustralia interface. Download & explore 24,620 files (3gb) of OCRd text! #dhhacks
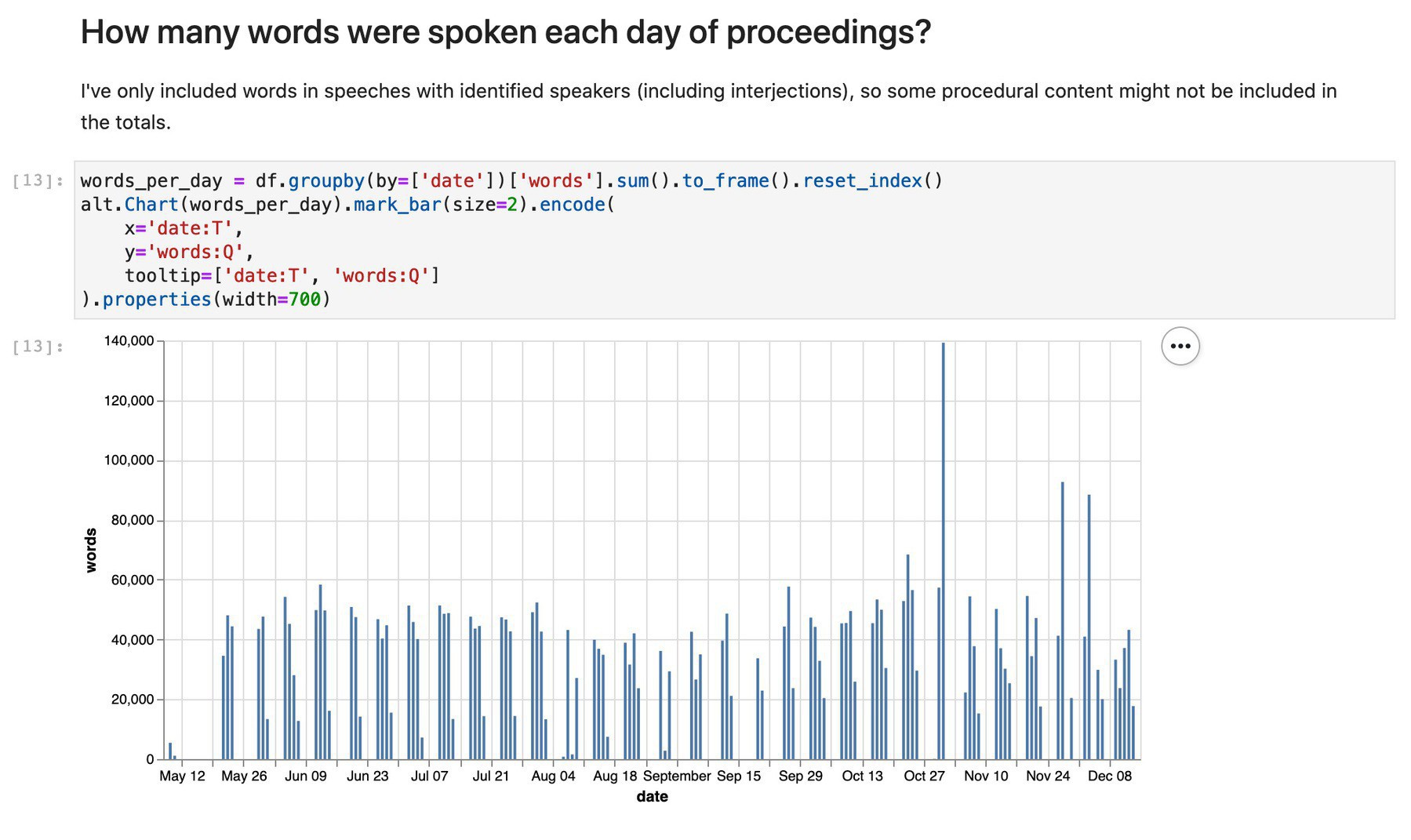
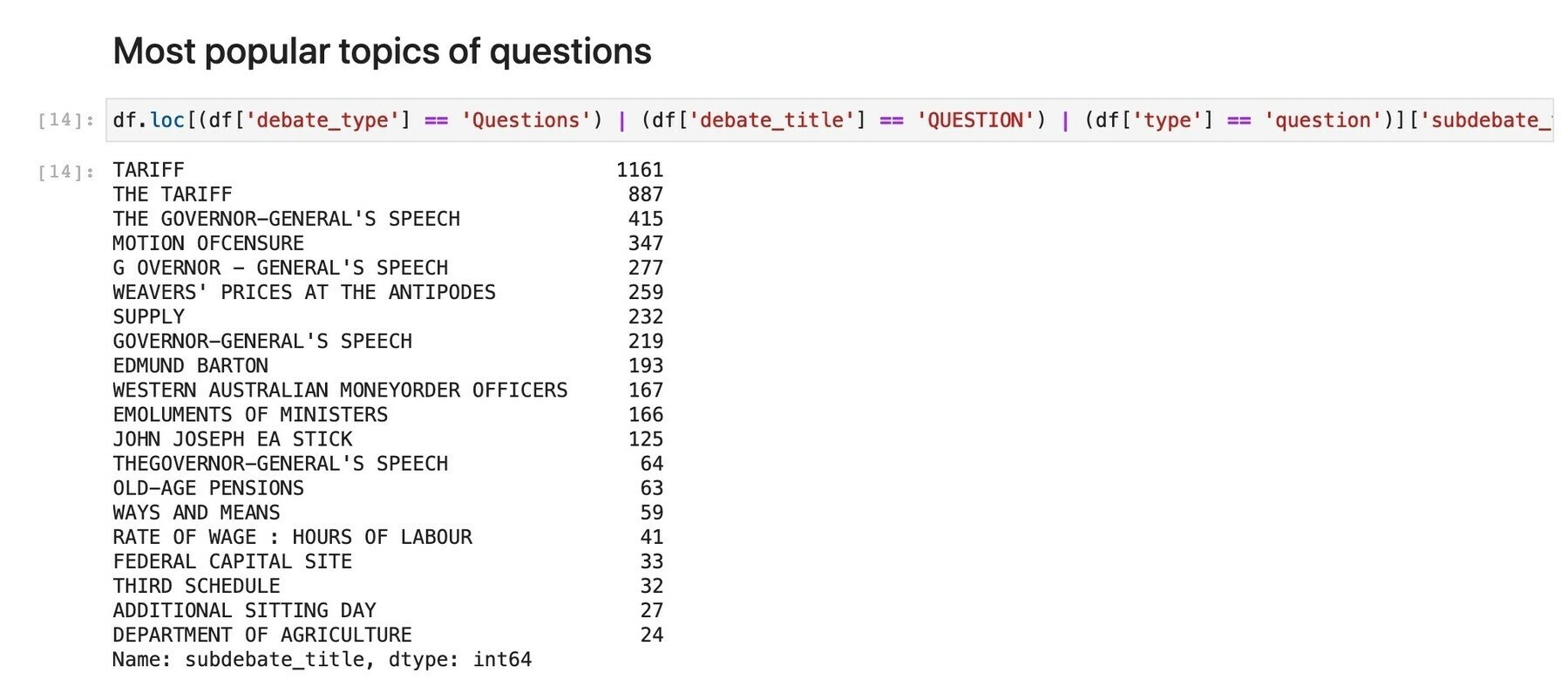
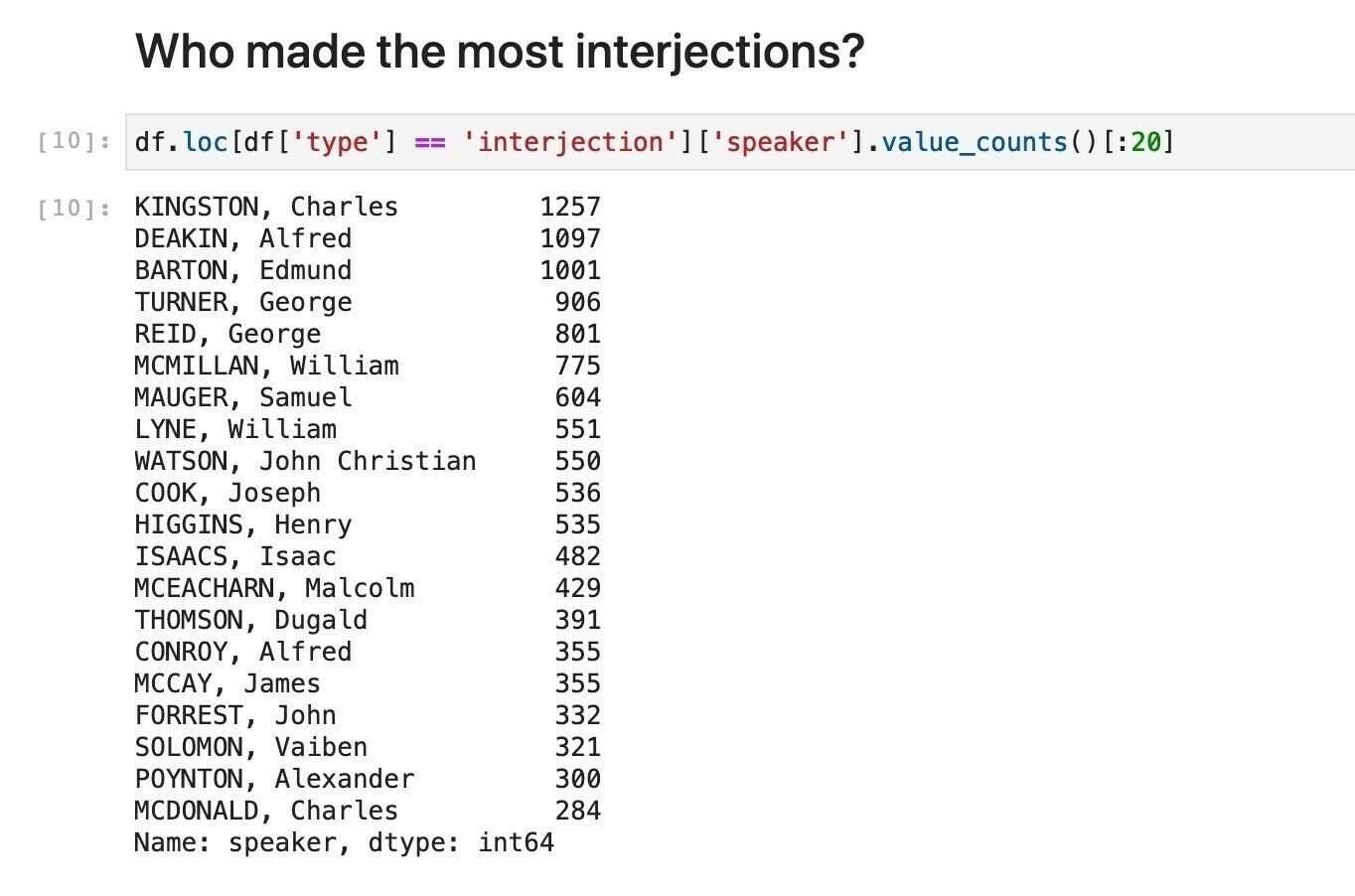
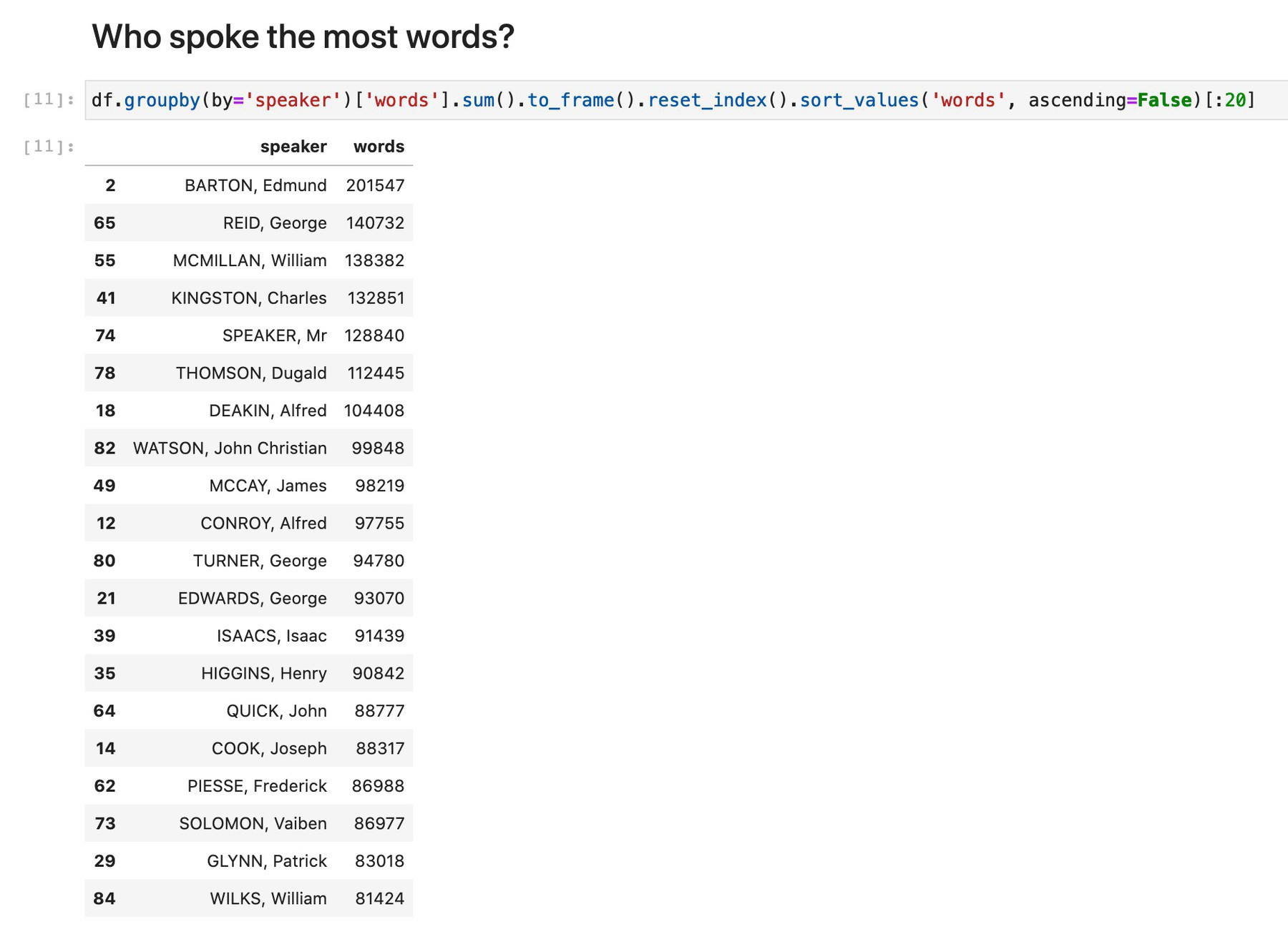
Revisiting my Historic Hansard XML repository & realising how easy it is to load files as needed via the GitHub API & explore with Pandas & Jupyter. This #GLAMWorkbench notebook helps you explore a particular year/house. #dhhacks
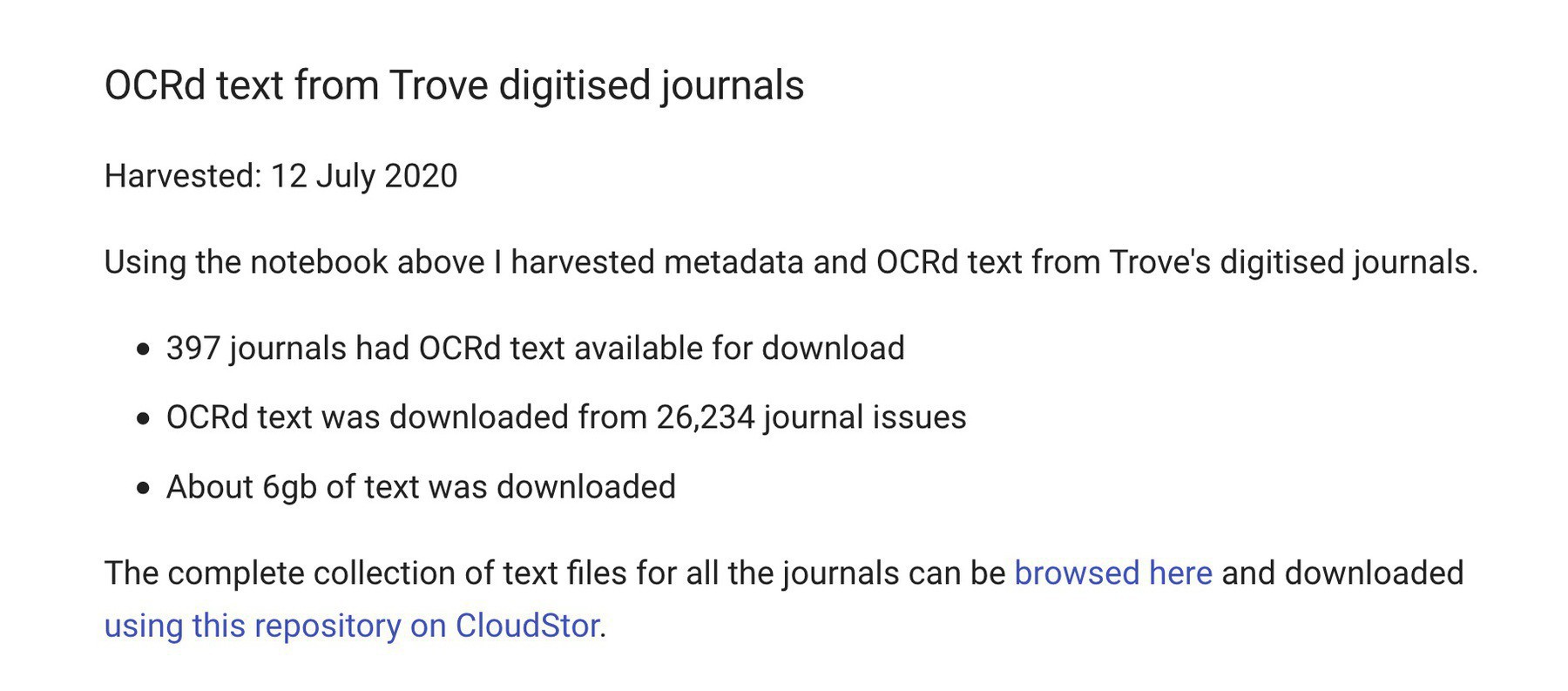
The Trove Journals section of the #GLAMWorkbench has been updated to work with the new @TroveAustralia interface! I’ve also re-harvested ALL the OCRd text from digitised journals — 6gb of text from 397 journals now downloadable in bulk from CloudStor. #dhhacks
New in #GLAMWorkbench! After you’ve used the @TroveAustralia Newspaper Harvester to download lots & lots of articles, try exploring the results in Datasette. This notebook sets everything up, you can even add full text search & images! #dhhacks