New in #GLAMWorkbench! After you’ve used the @TroveAustralia Newspaper Harvester to download lots & lots of articles, try exploring the results in Datasette. This notebook sets everything up, you can even add full text search & images! #dhhacks

New in #GLAMWorkbench! After you’ve used the @TroveAustralia Newspaper Harvester to download lots & lots of articles, try exploring the results in Datasette. This notebook sets everything up, you can even add full text search & images! #dhhacks
Download newspaper articles in bulk! The Trove Newspaper Harvester has been updated to work with the new @TroveAustralia interface. I’ve also added the ability to save articles as .jpg images! The easiest way to get started is via the #GLAMWorkbench. #dhhacks



My app for searching in @TroveAustralia’s digitised journals has been updated to work with the new Trove interface. You’ll need to have switched over to the new interface before you try searching (just click the link on the Trove home page). #dhhacks
Another db migrated and app updated!
Have you ever wondered what interjections in historic hansard would look like as tweets? Well I did… Now with longer interjections & more emojis!
hansard-interjections.herokuapp.com/tweets/ #dhhacks
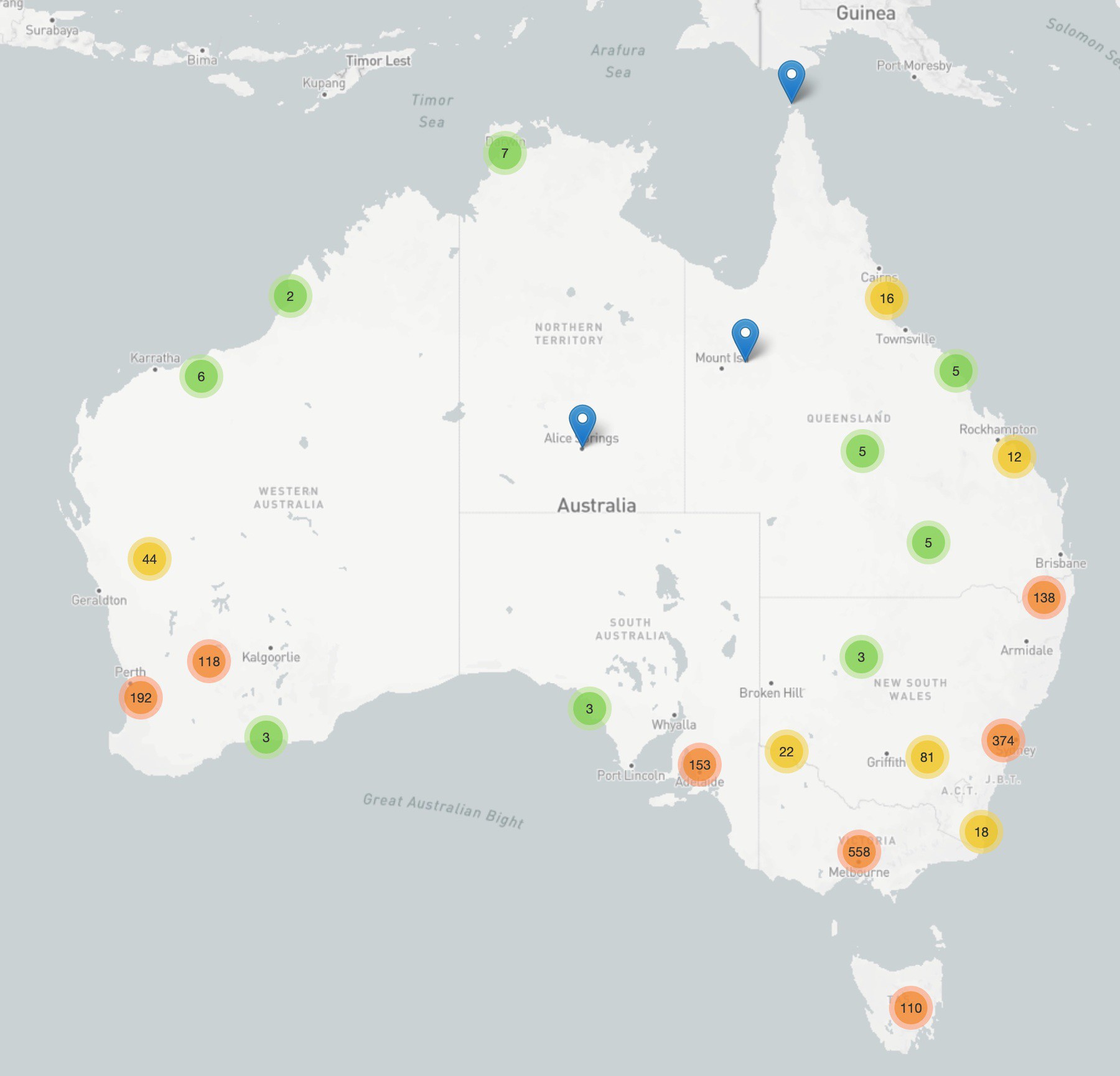
Here’s a map of places where @TroveAustralia digitised newspapers were published/circulated. Click on the map to find the closest newspapers to a place. Updated with new titles from the last year! troveplaces.herokuapp.com/map/ #dhhacks
We tend to think of a web archive as a site we go to when links are broken – a useful fallback, rather than a source of new research data. But web archives don’t just store old web pages, they capture multiple versions of web resources over time. Using web archives we can observe change – we can ask historical questions. But web archives store huge amounts of data, and access is often limited for legal reasons.
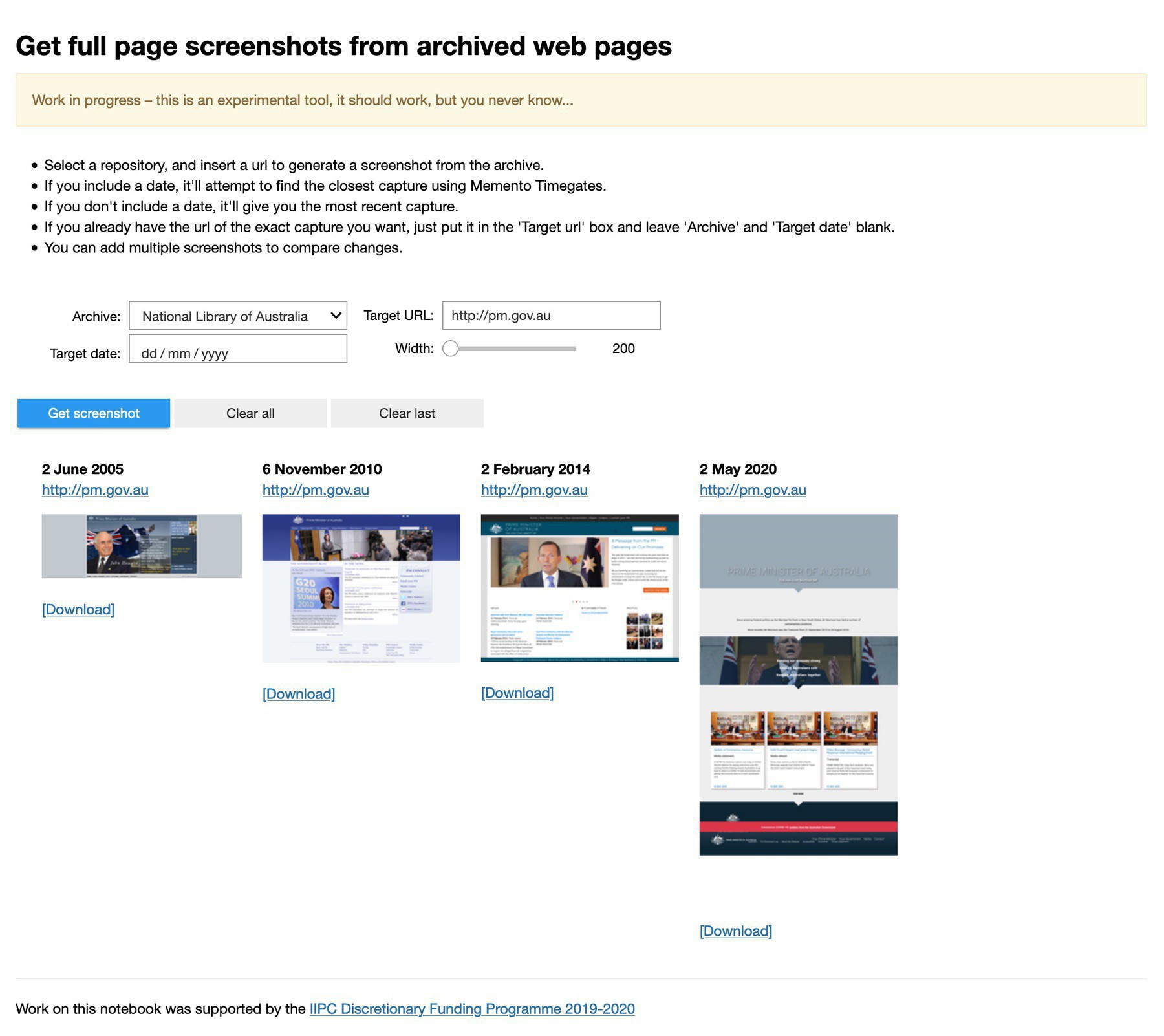
Thanks to @NetPreserve, I’ve been spending time lately working on a set of web archive exploration notebooks for the #GLAMWorkbench. Here’s an example to create/compare screenshots of captures. #dhhacks
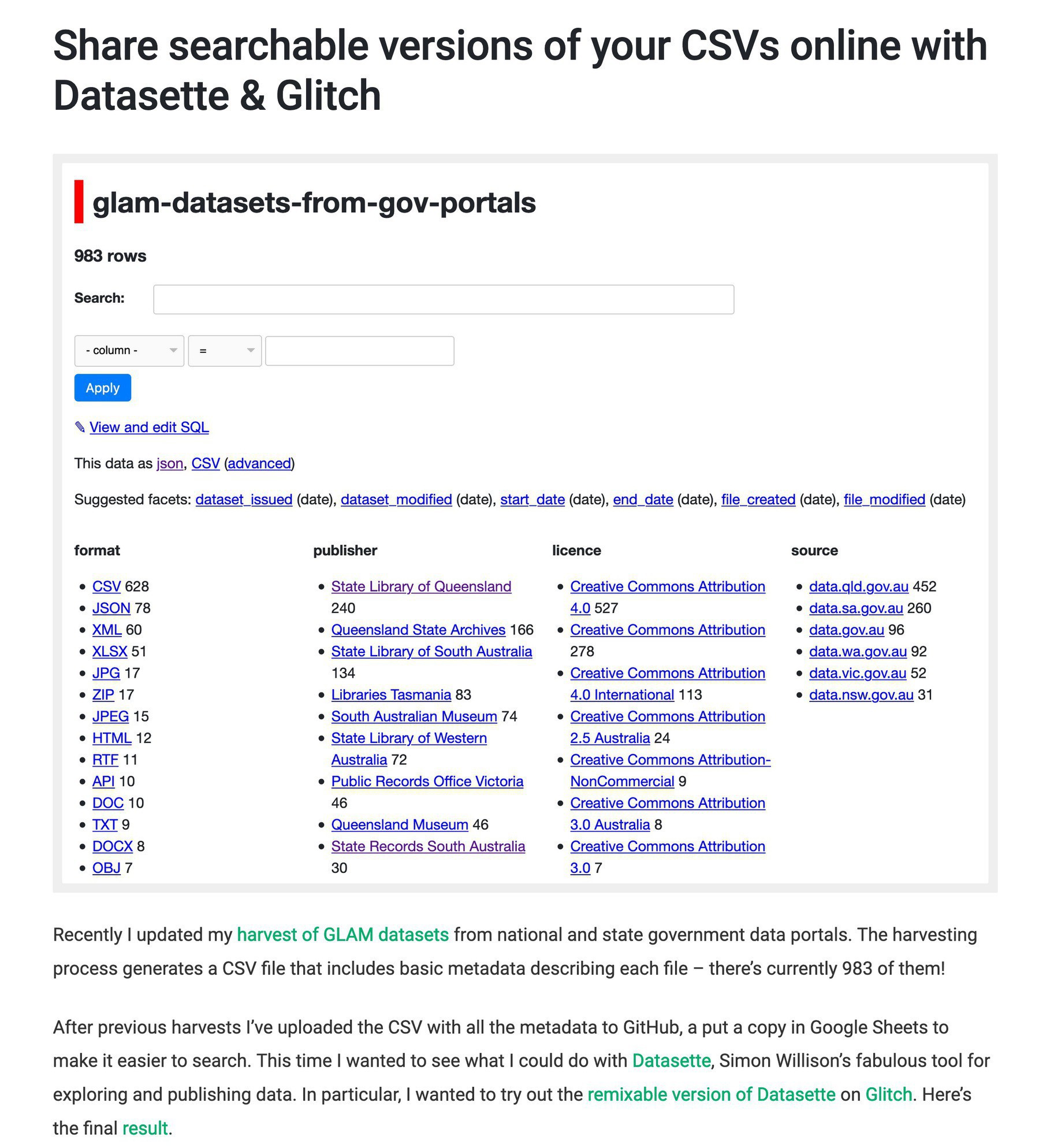
Do you have a CSV file you’d like to make searchable, maybe even share online? New on #dhhacks, I show you how with @simonw’s awesome Datasette tool & @Glitch. Give it a try! 101dhhacks.net/share-sea…
New on #dhhacks – make your own @TroveAustralia newspaper game! Thanks to @glitch, just edit a couple of files to create your own customised edition of Headline Roulette – make it about cats, or Queensland, or Communist Party newspapers, or whatever!
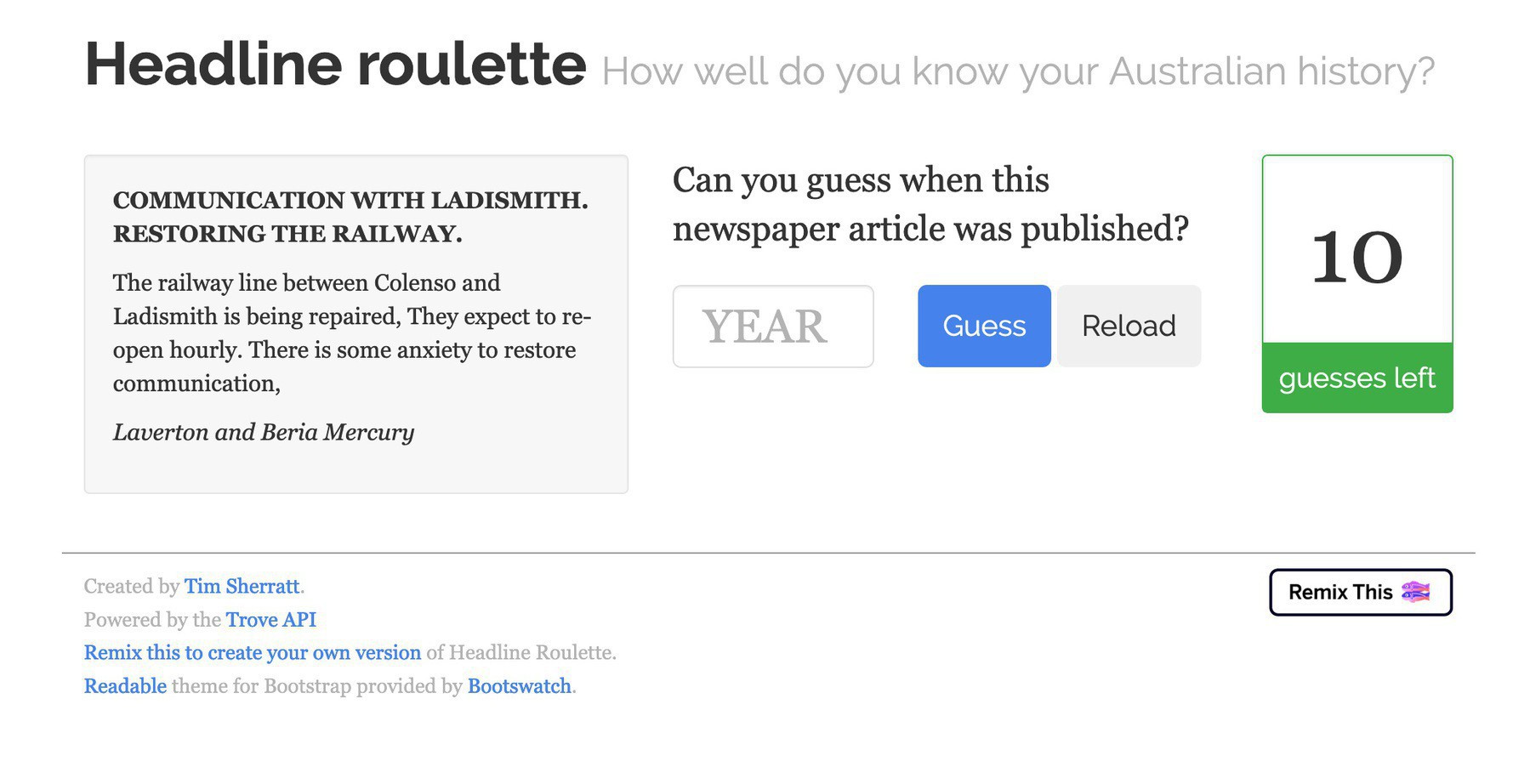
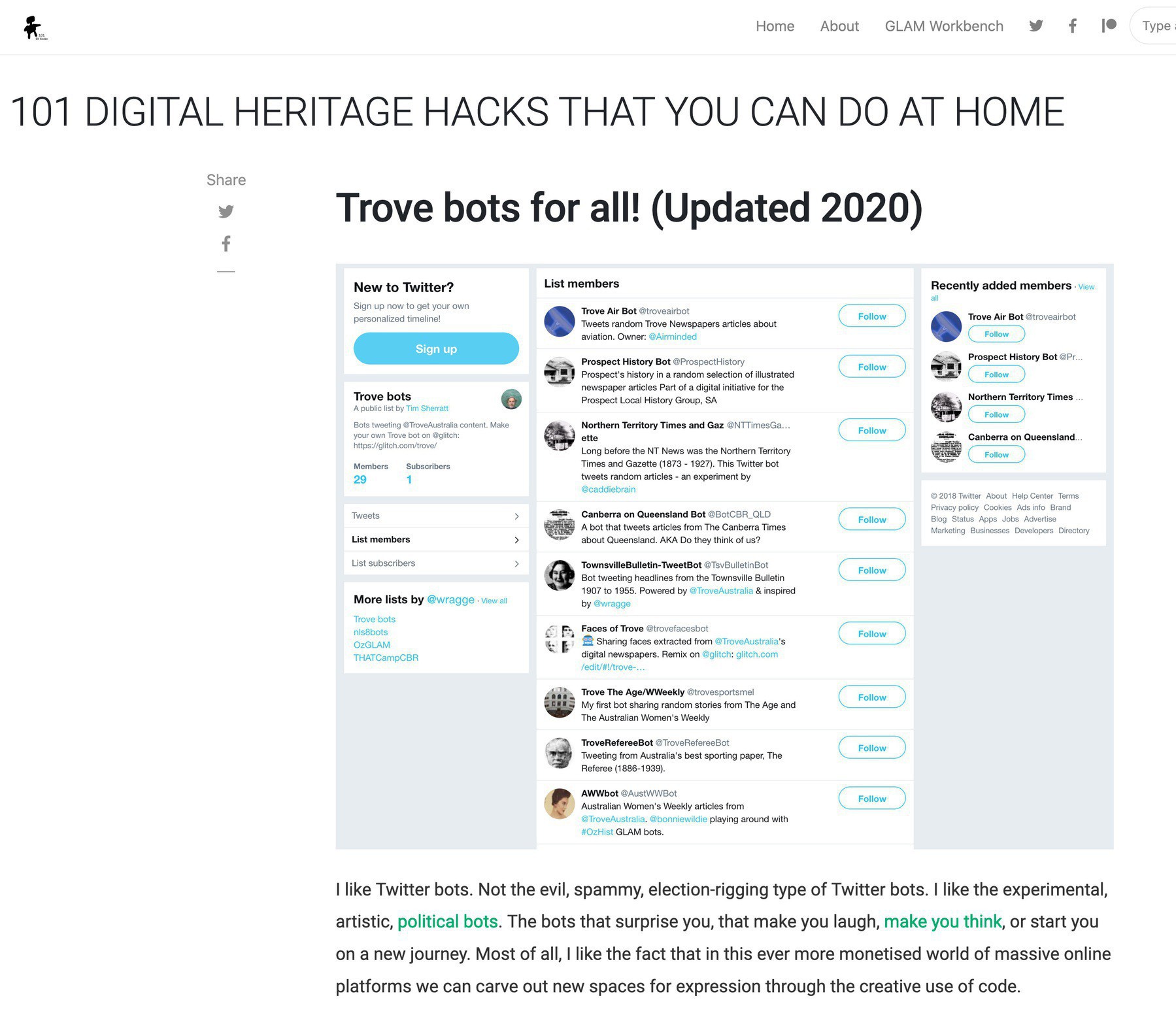
I’ve given my #dhhacks site a refresh, and updated my @TroveAustralia Twitter bot tutorial to link to the latest versions of the bots on @glitch. The new code is actually easier to customise, so plenty of opportunities to play around! More DHHacks coming soon…
If you’d ever wished you could get a random(ish) newspaper article from @TroveAustralia’s API, here’s a hack for you! I’ve added an option to return a random article to my Trove proxy app. You can filter by normal API facets. Go to: trove-proxy.herokuapp.com #dhhacks

The GLAM CSV Explorer has had a few updates — you can now filter by organisation, and upload your own CSV files! #GLAMWorkbench Try it live on Binder.
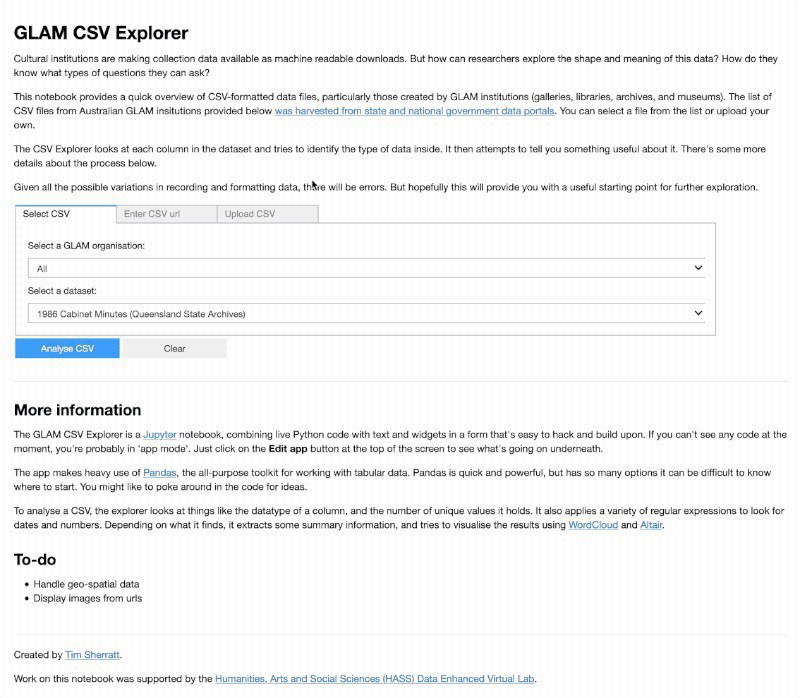
For a couple of years I’ve been harvesting datasets created or published by Australian GLAM organisations through government data portals. I’ve just completed the latest harvest, and there’s now 369 datasets, containing 983 files, from 23 GLAM organisations. 628 of these files are in CSV (spreadsheet) format. There’s a number of ways that you can explore the harvested data. You can browse a big list of datasets, or download a CSV containing all the harvested data or just those formatted as CSVs.
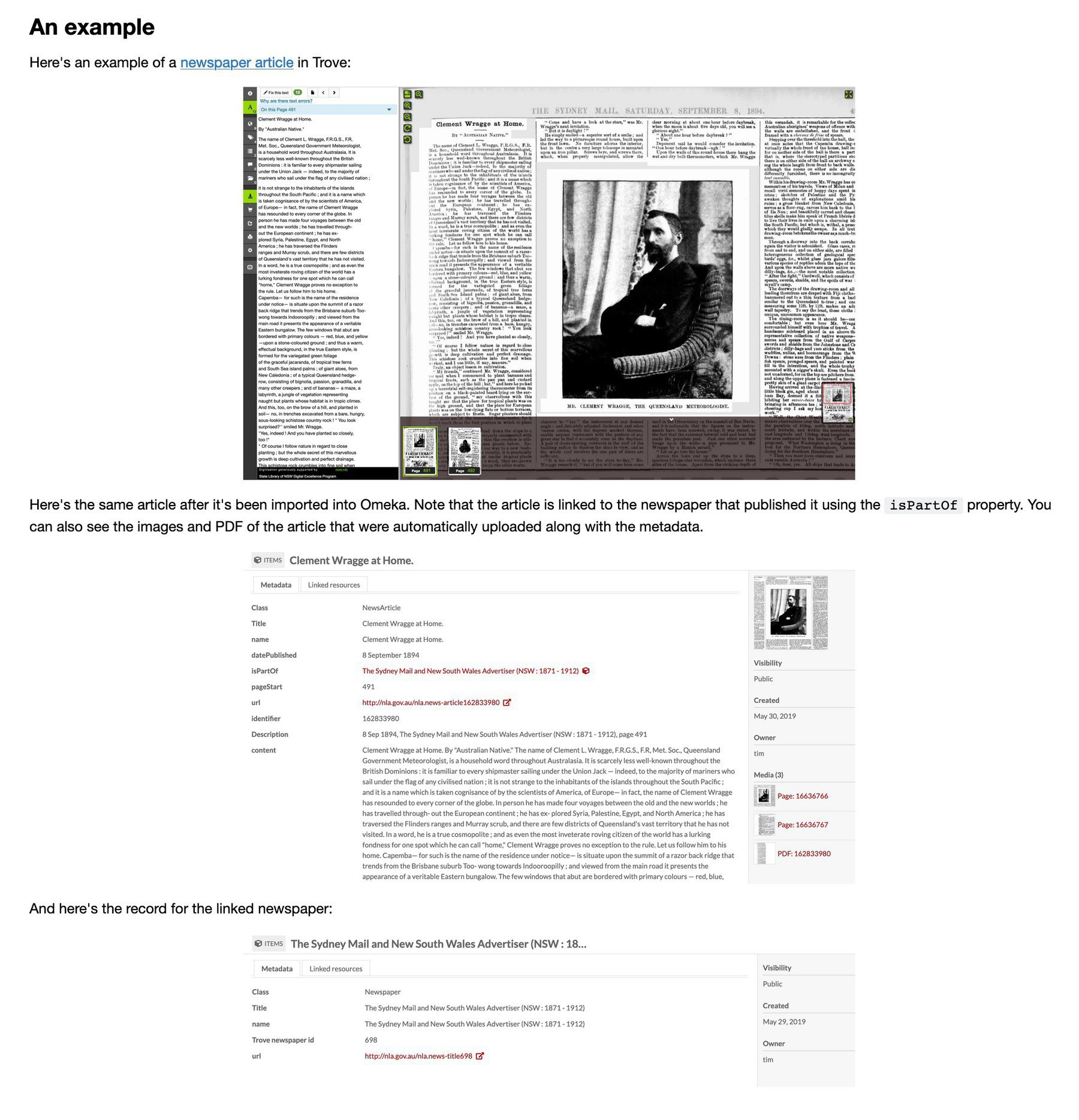
Updated! My notebook to upload digitised newspapers from @TroveAustralia to an @Omeka-S site has been improved — no longer trips over non-newspaper articles in Zotero collections, and does a check to avoid uploading existing articles. #dhhacks

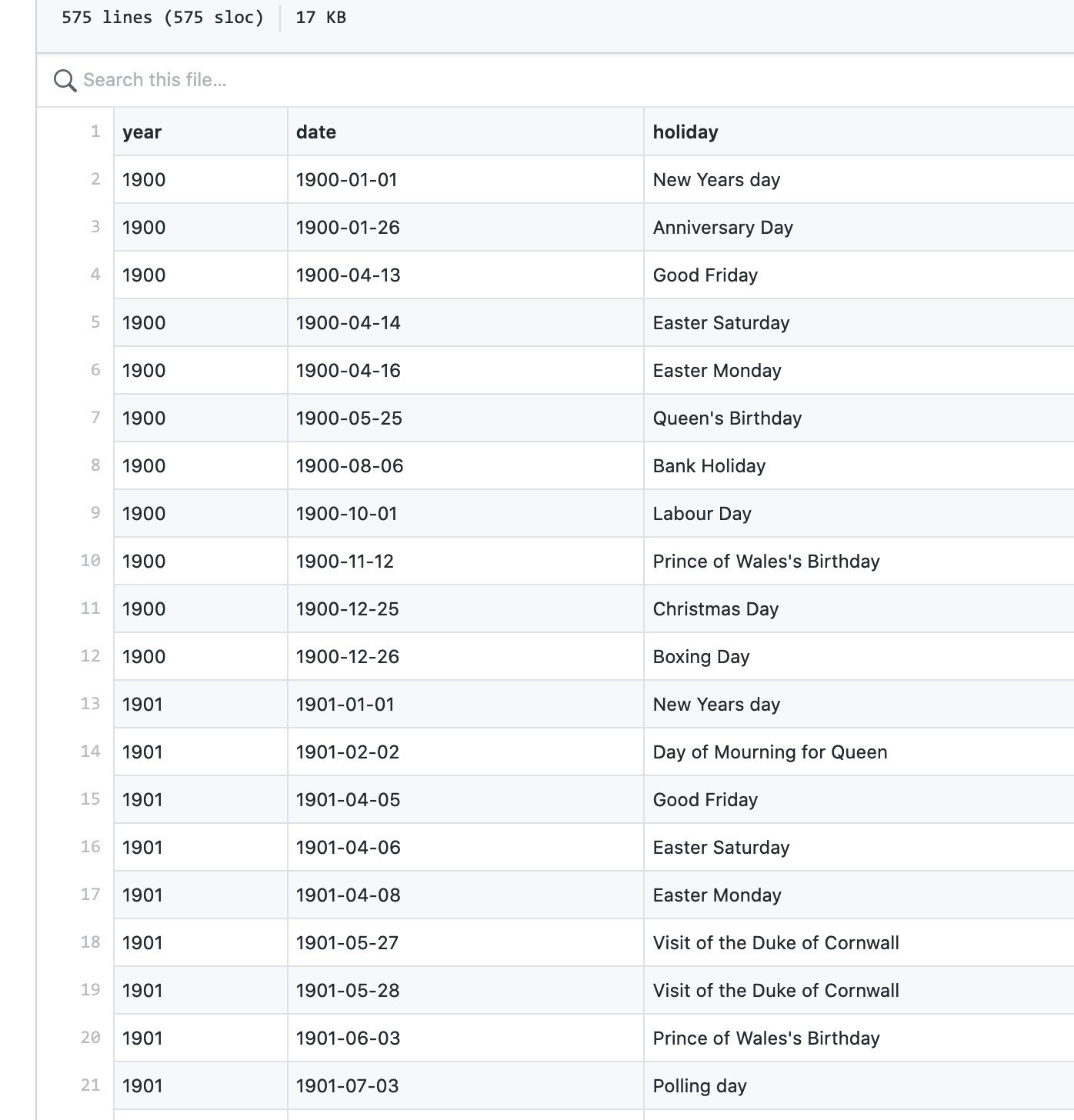
My data file of public holidays in NSW from 1900-1950 has been updated – now including variations in the King’s Birthday holiday and extra days like VE Day. #dhhacks
My harvest of OCRd text from @TroveAustralia digitised books, ephemera, and parliamentary papers has been updated! There’s now 19,795 text files (about 3gb) to explore! Harvesting details and links to browse/download files from Cloudstor are in the #GLAMWorkbench. #dhhacks



The simple Trove proxy that you can use to get to download links for PDFs of newspaper articles from @TroveAustralia has been updated to Python 3, and Trove API version 2. It’s used in @Zotero and elsewhere… #dhhacks
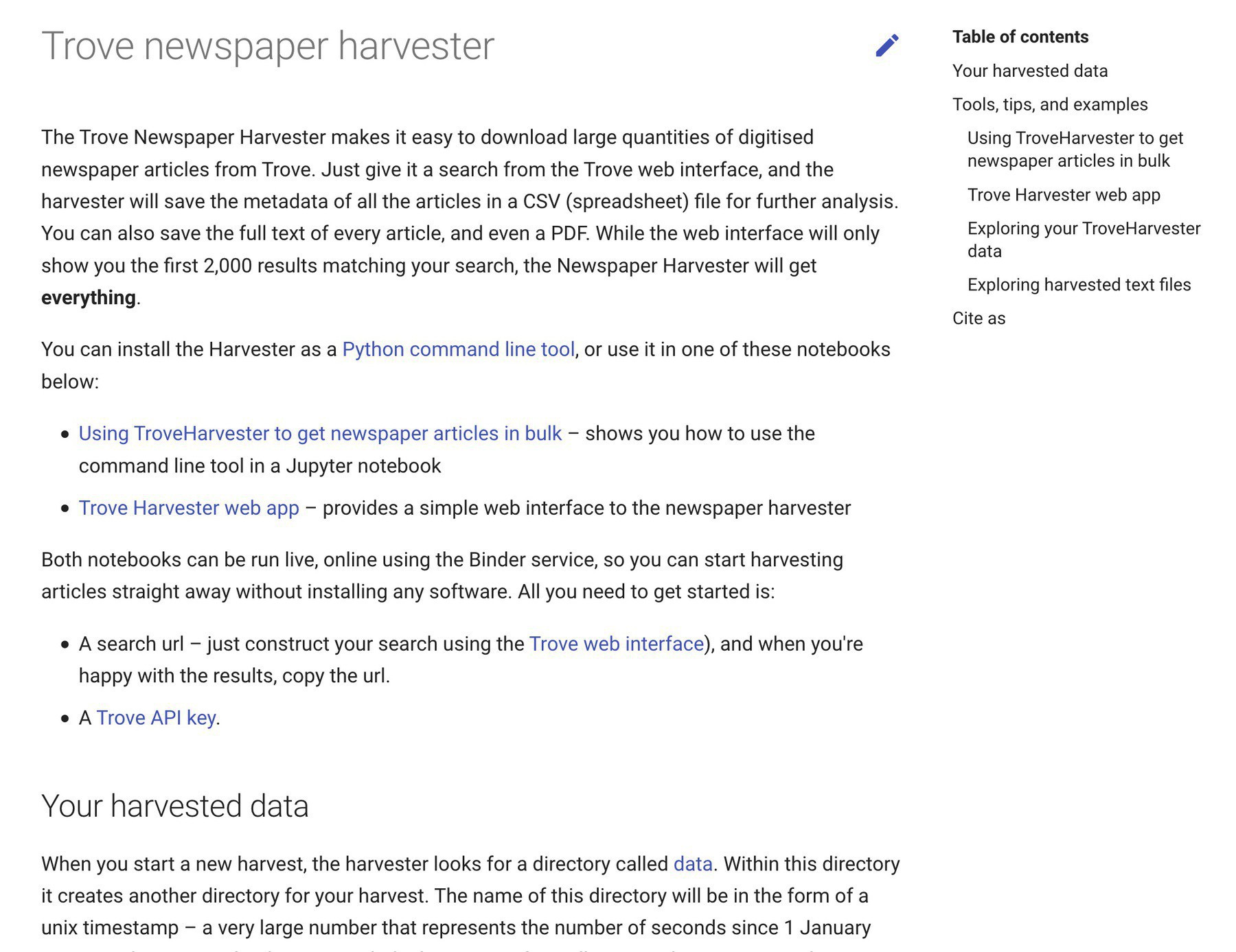
I’ve added some more documentation to the Trove Newspaper Harvester page in the #GLAMWorkbench. Get your @TroveAustralia newspaper articles in bulk! #dhhacks #collectionsasdata
New section added to the #GLAMWorkbench with examples from @Library_Vic! #slvdata #dhhacks #collectionsasdata

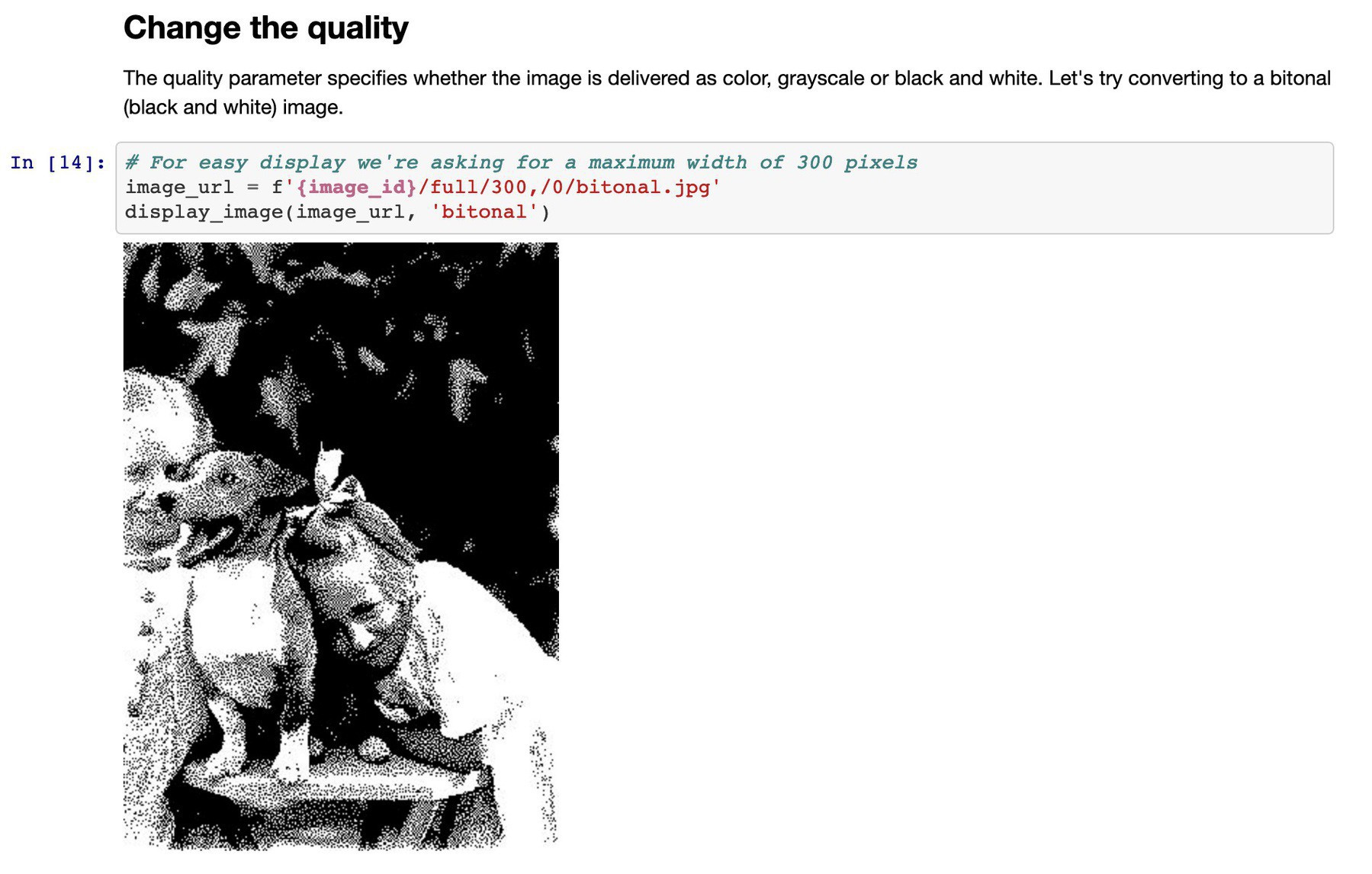
More fun with @iiif_io and images from @library_vic – resize, rotate, crop and more! Try it out with this new notebook in the #GLAMWorkbench. #slvdata #dhhacks