I’m looking for books in @TroveAustralia, but there’s lots of ephemera (pamphlets, posters etc) in the book zone. So I tried grabbing the images of ‘books’ with one page & found some nice stuff including this collection of playbills. #dhhacks
![mp-photo-alt[]=mp-photo-alt[]=mp-photo-alt[]=](https://cdn.uploads.micro.blog/8371/2019/b7867cd7ce.jpg)



I’m looking for books in @TroveAustralia, but there’s lots of ephemera (pamphlets, posters etc) in the book zone. So I tried grabbing the images of ‘books’ with one page & found some nice stuff including this collection of playbills. #dhhacks
Text of over 3 thousand digitised books and pamphlets downloaded so far from @TroveAustralia…
![mp-photo-alt[]=](https://cdn.uploads.micro.blog/8371/2019/f3a5866b90.jpg)
After talking to @PrimahadiWijaya today about work at @MonashLing, I started harvesting metadata & full text from digitised books in @TroveAustralia. OCRd text from about 2,000 books downloaded so far. More soon… #dhhacks
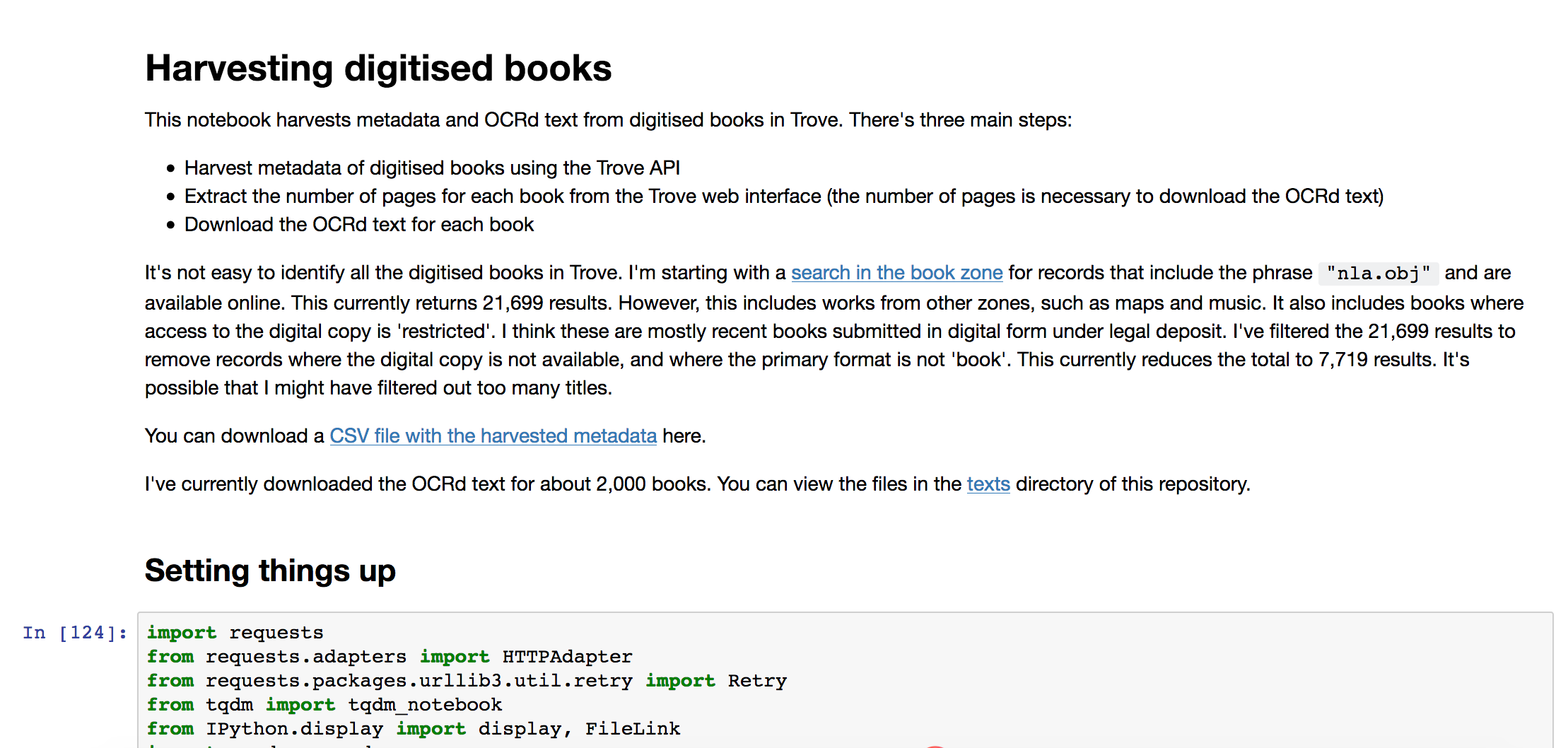
What I did at #valatechcamp! Here’s a CSV with basic details of 7,719 digitised books available through @TroveAustralia. I’m not sure if they all have OCRd text available, but if they do I’ll attempt to download it once I’m back home.
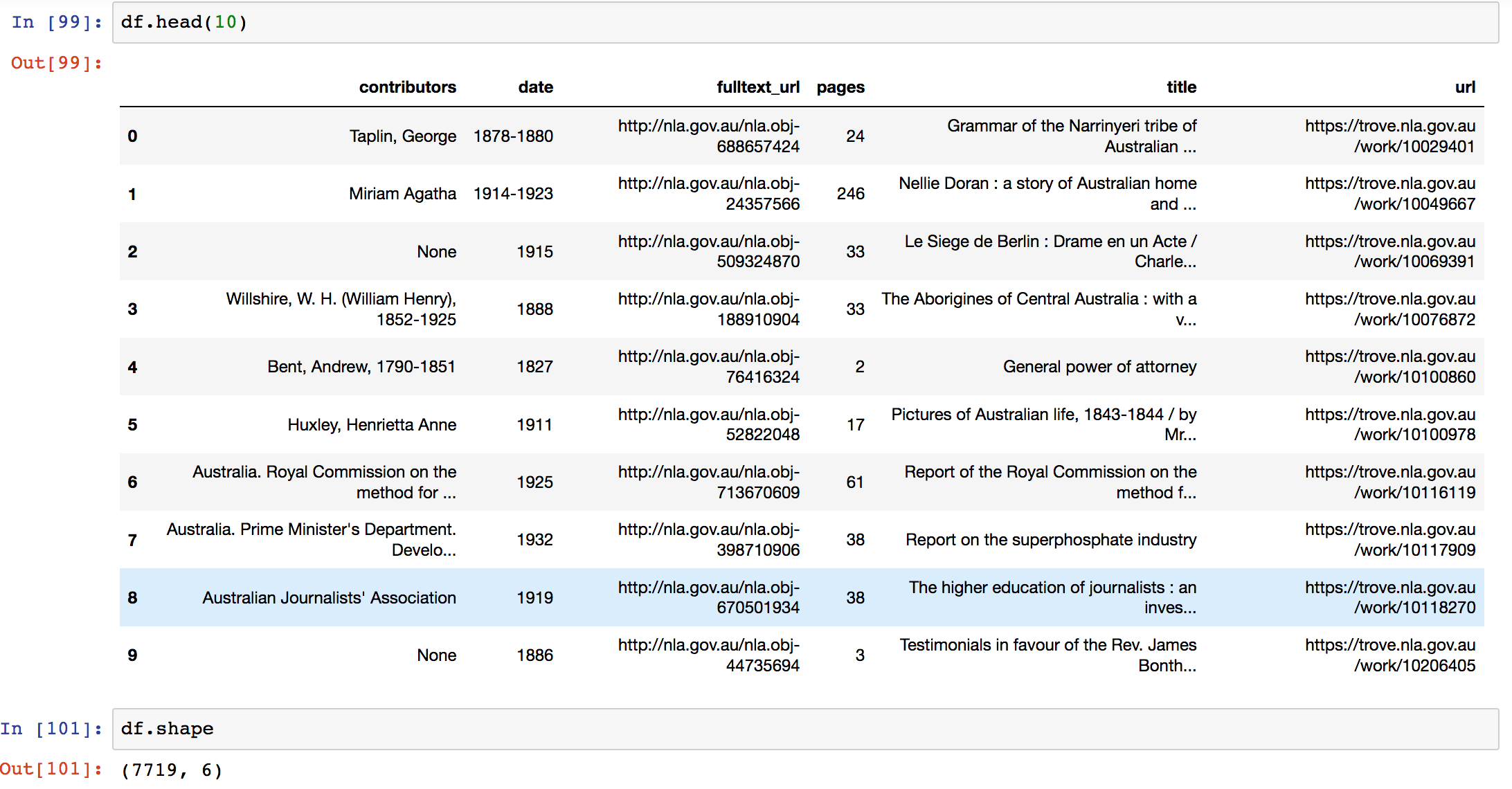
TIL that the web pages for digitised works (like books and journal issues) on @TroveAustralia embed a lot of useful metadata that you can’t get through the API. Here’s how to extract it.
Just posting the link to my ‘Introducing APIs’ slides for #VALATechCamp again, so that they show up in my MicroBlog feed…
Hmm, it occurs to me that the method I used to generate newspaper article thumbnails from Trove, could also be used to extract illustrations (cartoons, drawings, photos etc)…
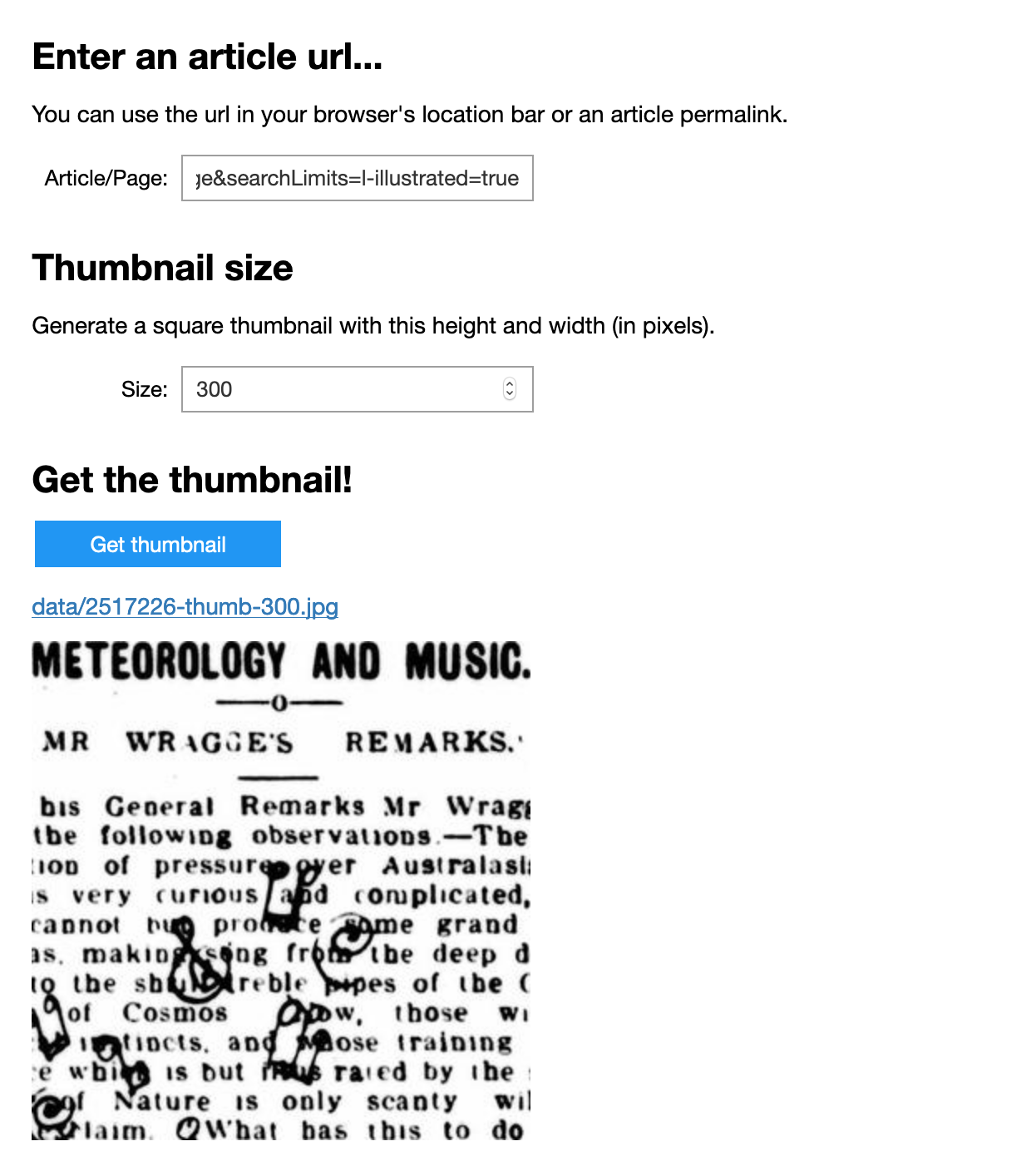
So, I’ve finally figured out a way to automatically generate nice-looking thumbnails from @TroveAustralia newspaper articles. Demo notebook here. #dhhacks
So I put the recent report into Australia’s national cultural institutions into the @TDHASSN instance of @VoyantTools. Here’s the contexts of the word ‘story’…

Train from Canberra to Melbourne booked for #VALATechCamp. I’ll be hanging around both days, so let me know if you’d like to chat about the GLAM Workbench, Jupyter, Trove data, or any of the other things I fiddle with…
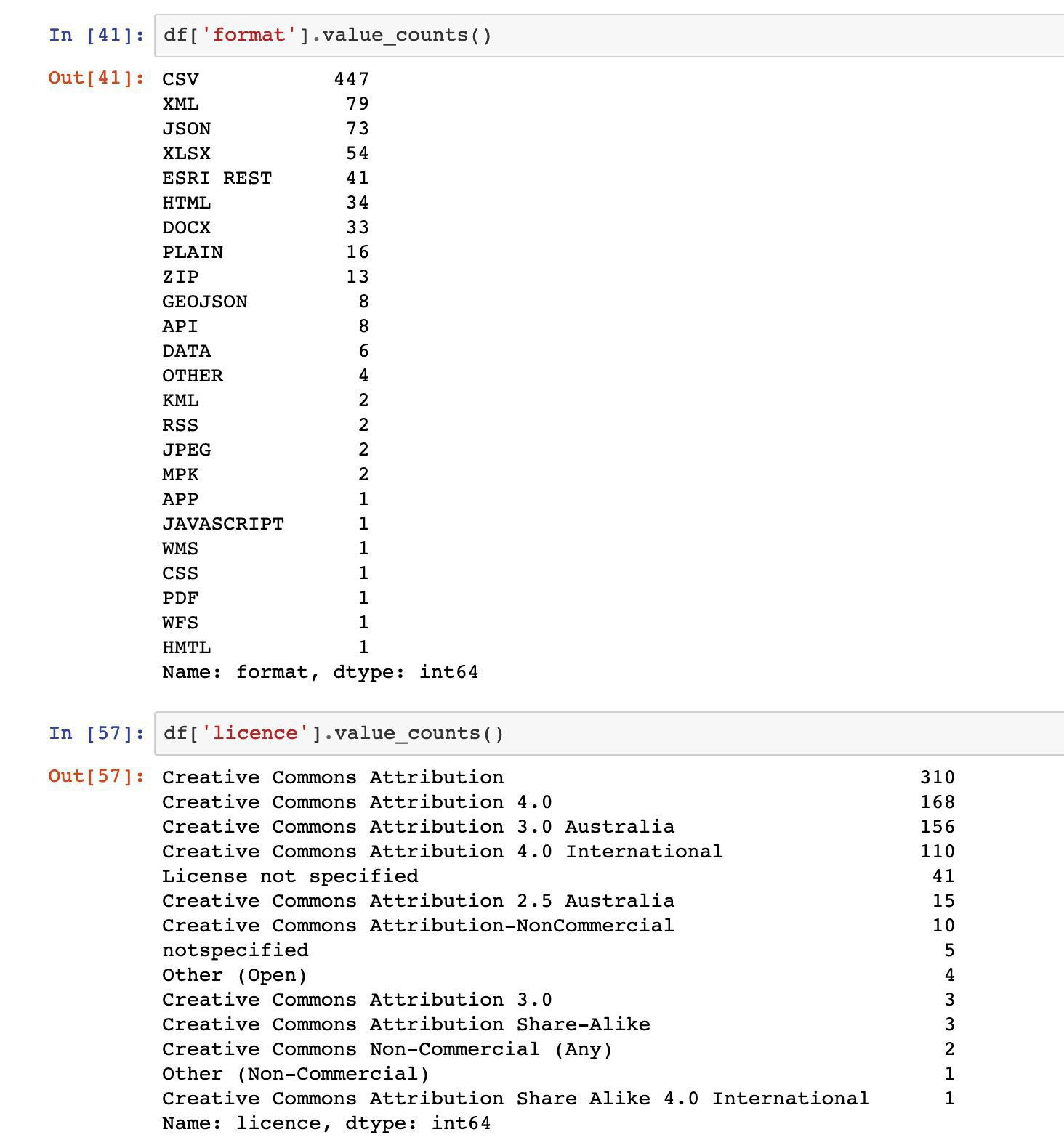
Sneak preview of my GLAM CSV Explorer now live on @MyBinderTeam! Select one of 447 GLAM-related CSVs from @datagovau for analysis, or load your own. Coming soon to @TDHASSN. #dhhacks
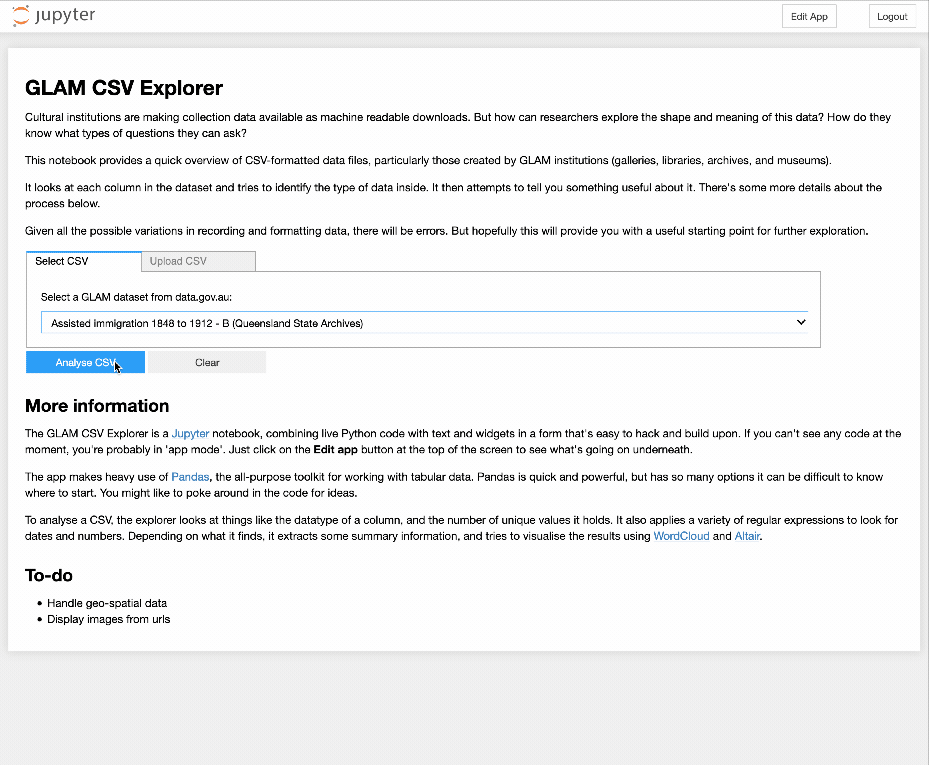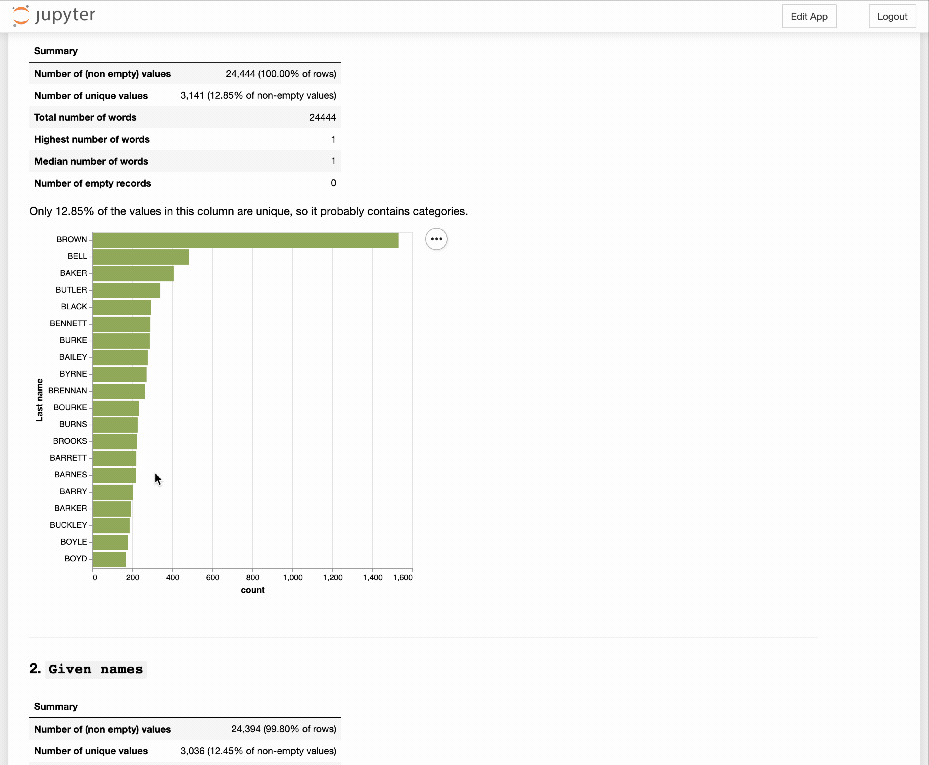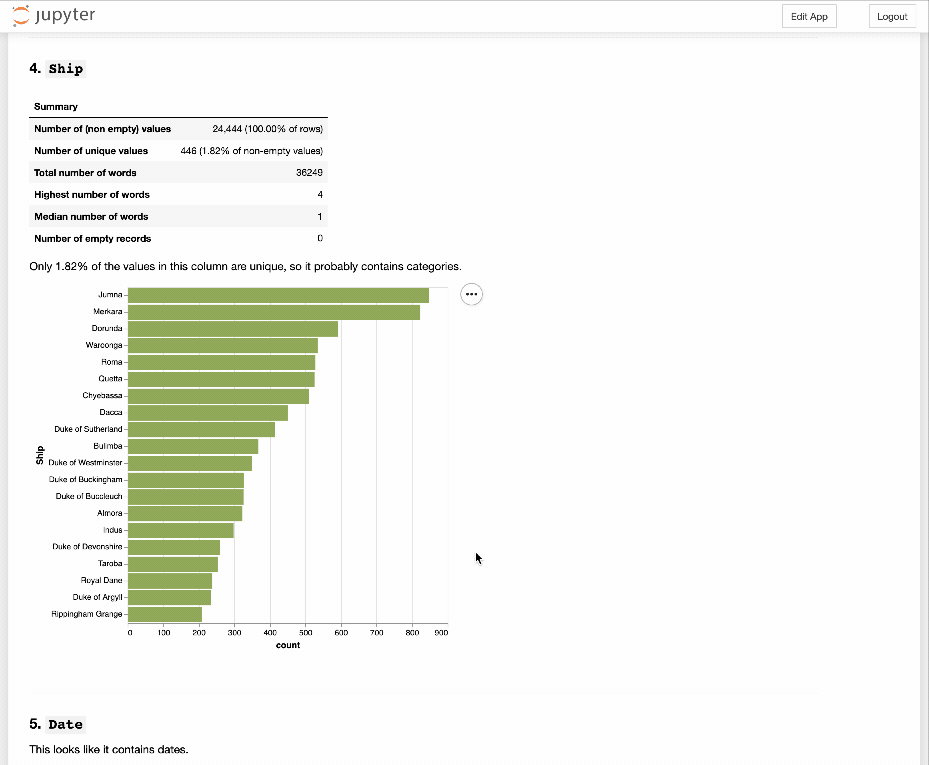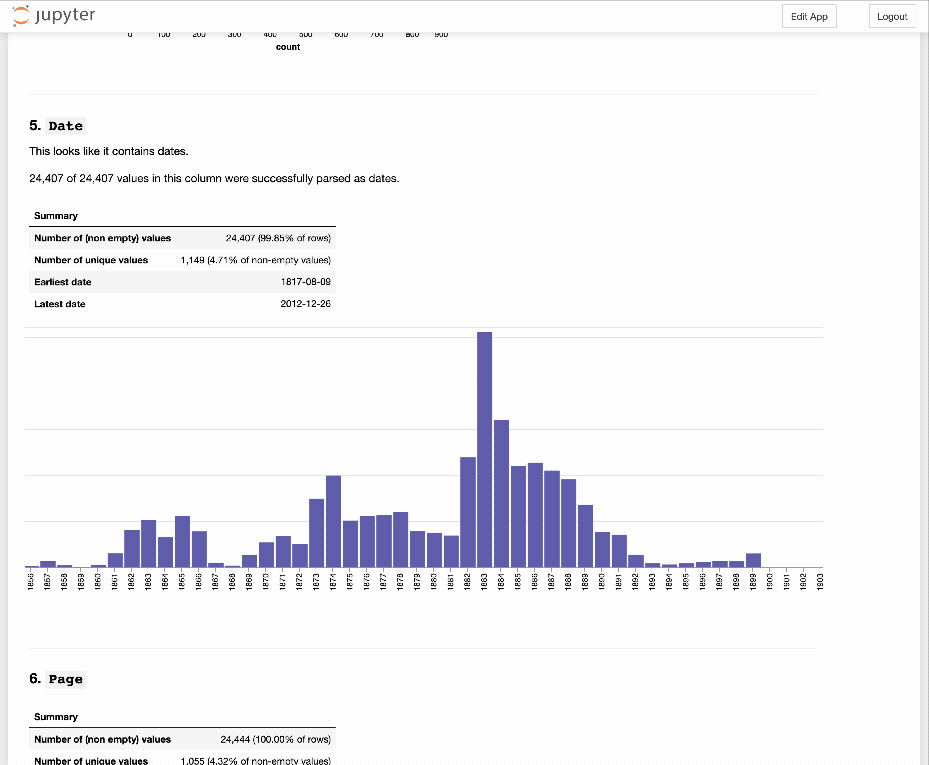
Having ripped out a lot of code and simplified a mess of conditionals, I think this CSV Explorer thingy is getting there…
Now to load that new CSV of GLAM CSVs into my CSV Explorer…
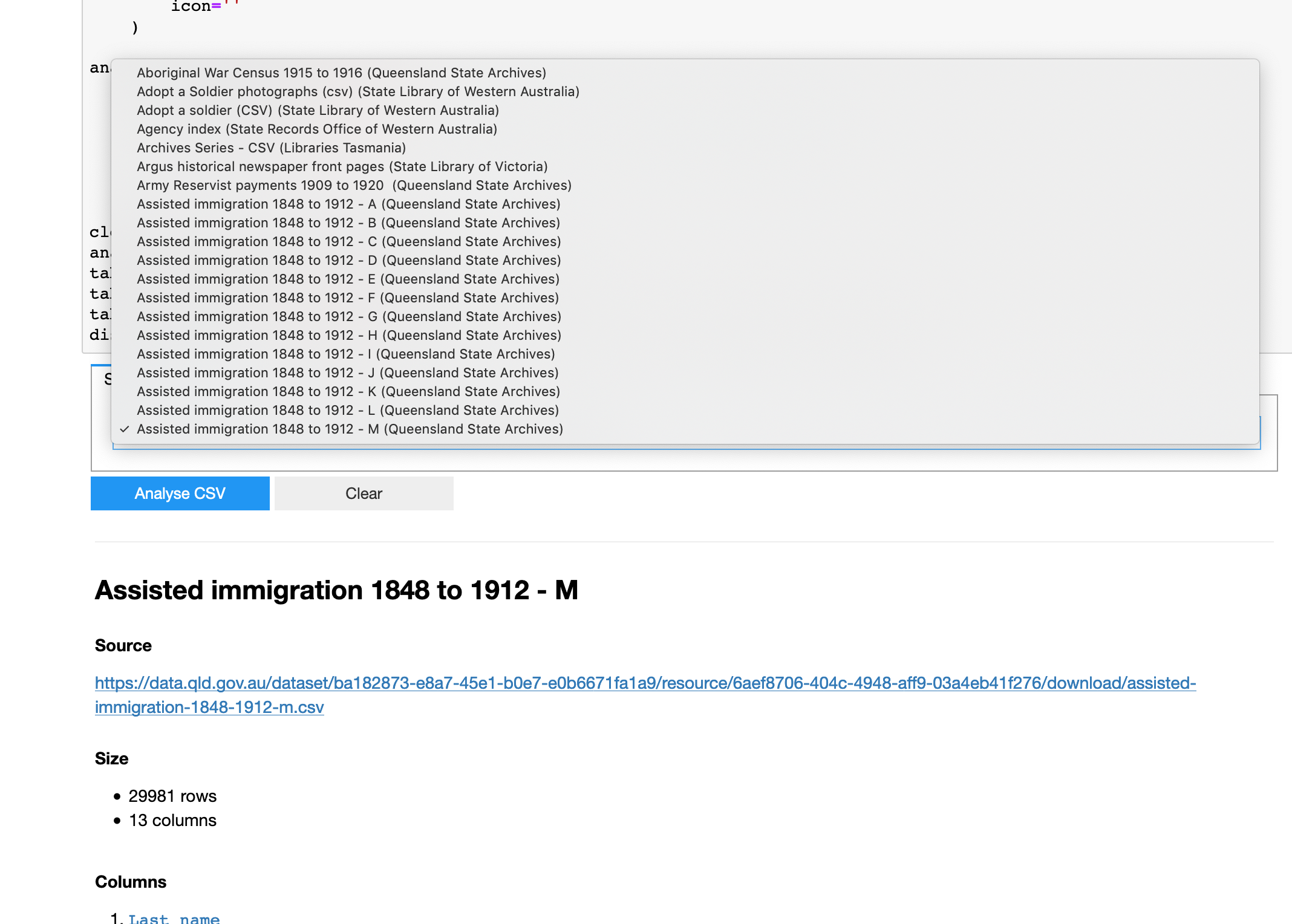
Quick notebook to harvest GLAM datasets via the new(ish) @datagovau API. Includes 447 CSVs from 19 institutions.
![mp-photo-alt[]=mp-photo-alt[]=](https://cdn.uploads.micro.blog/8371/2019/3db584bd1f.jpg)
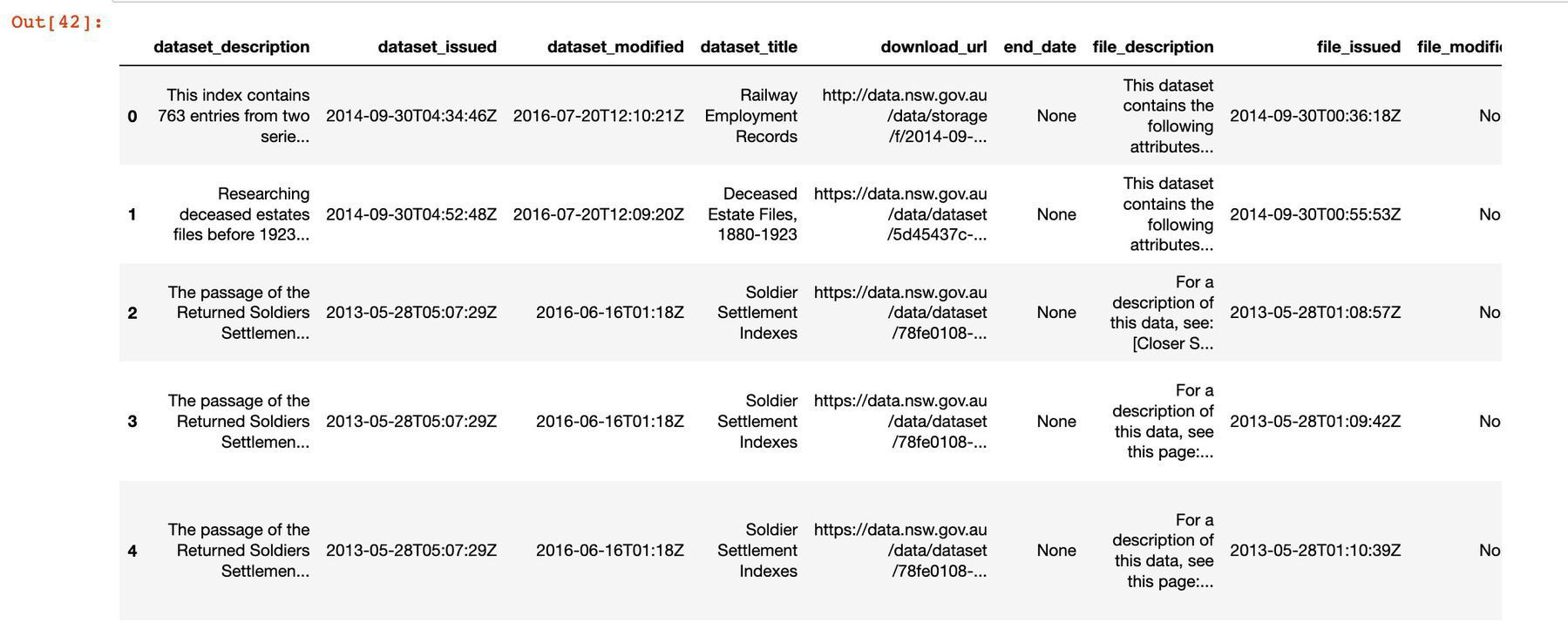
This is why we can’t have nice things…
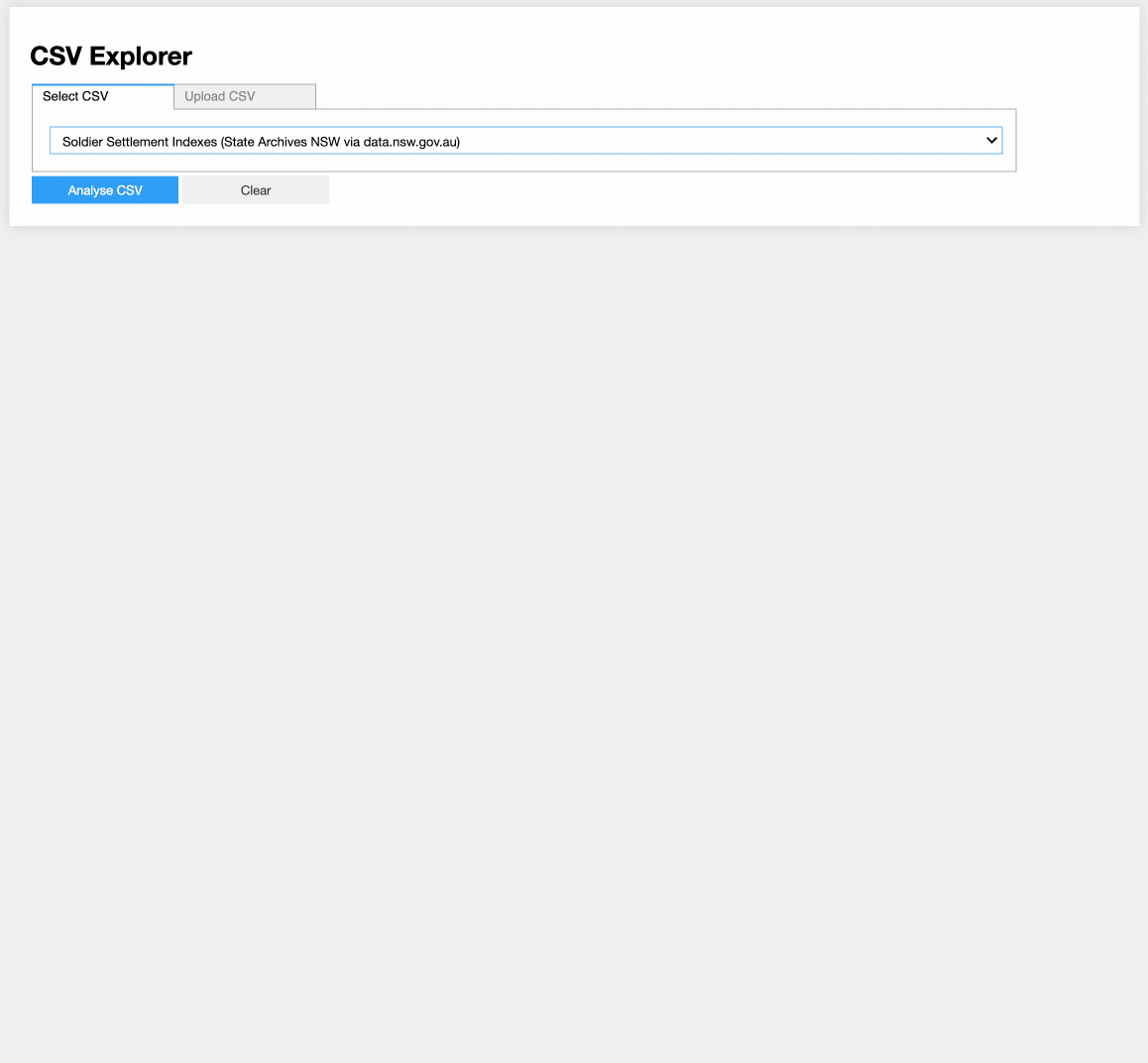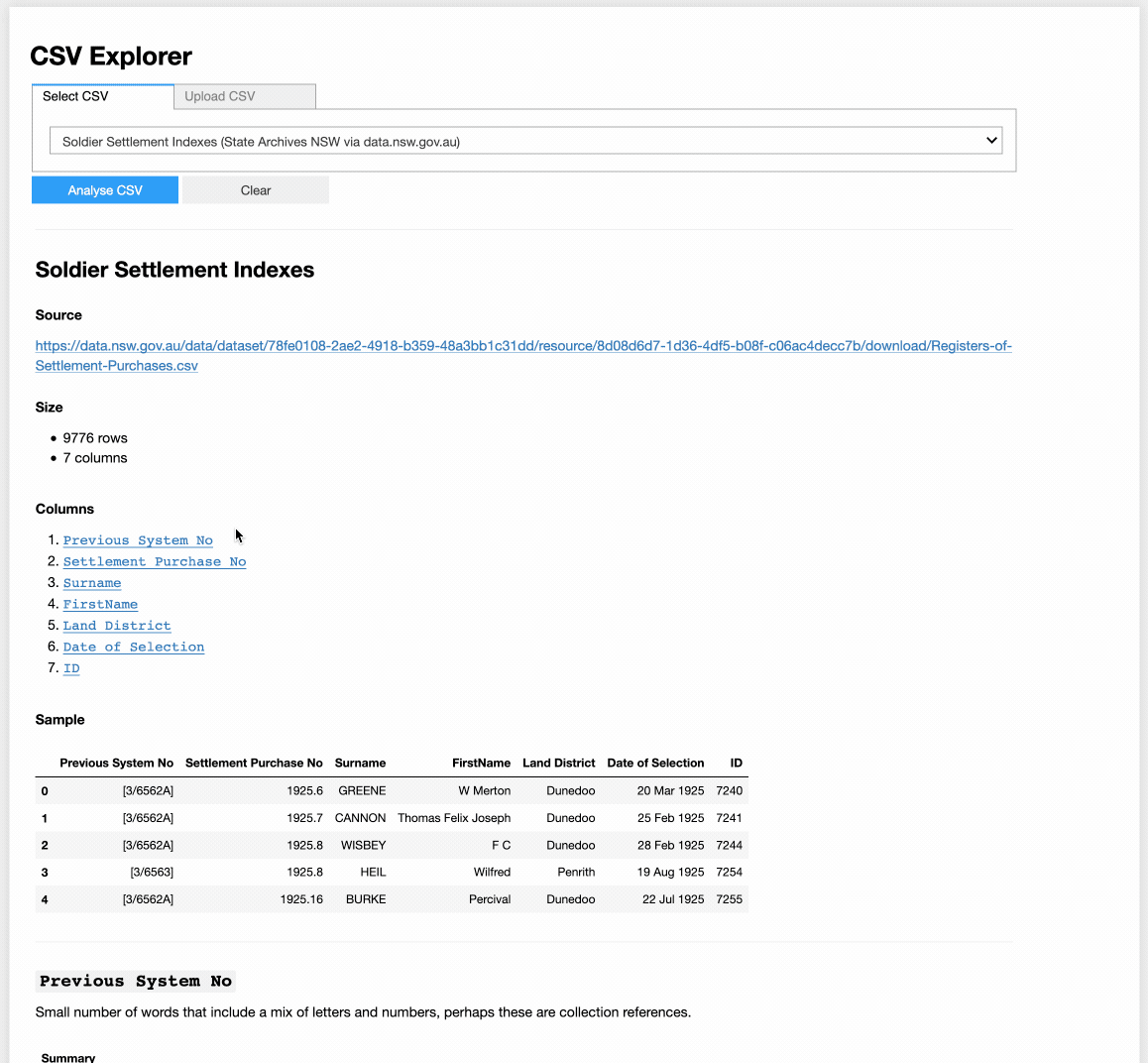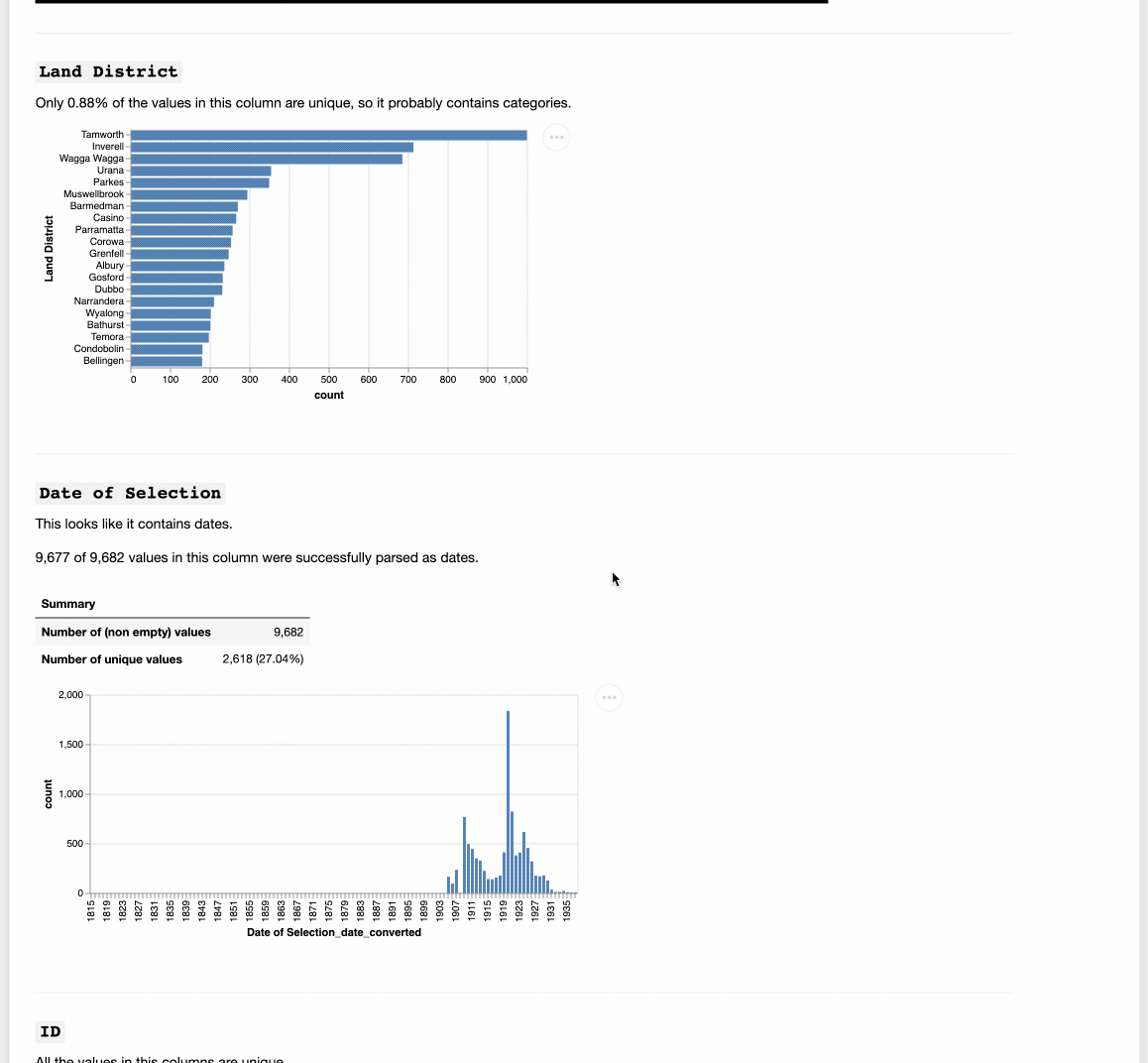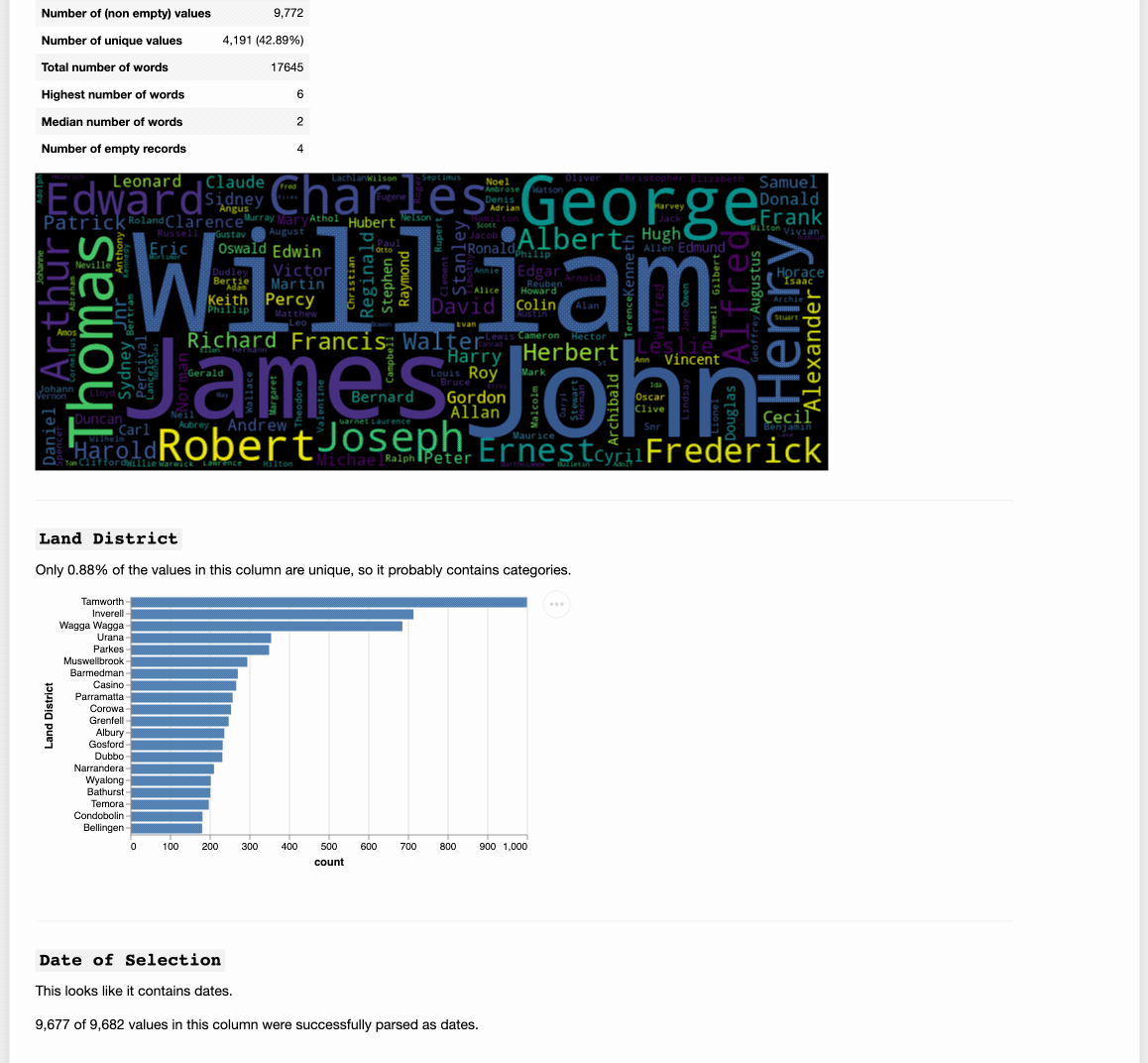
Still plenty to do, but my CSV Explorer is taking shape… (coming soon to @TDHASSN & elsewhere!)
I’ll be giving a demo at the @HumanitiesAU data summit on Friday.
Now with animated gif…
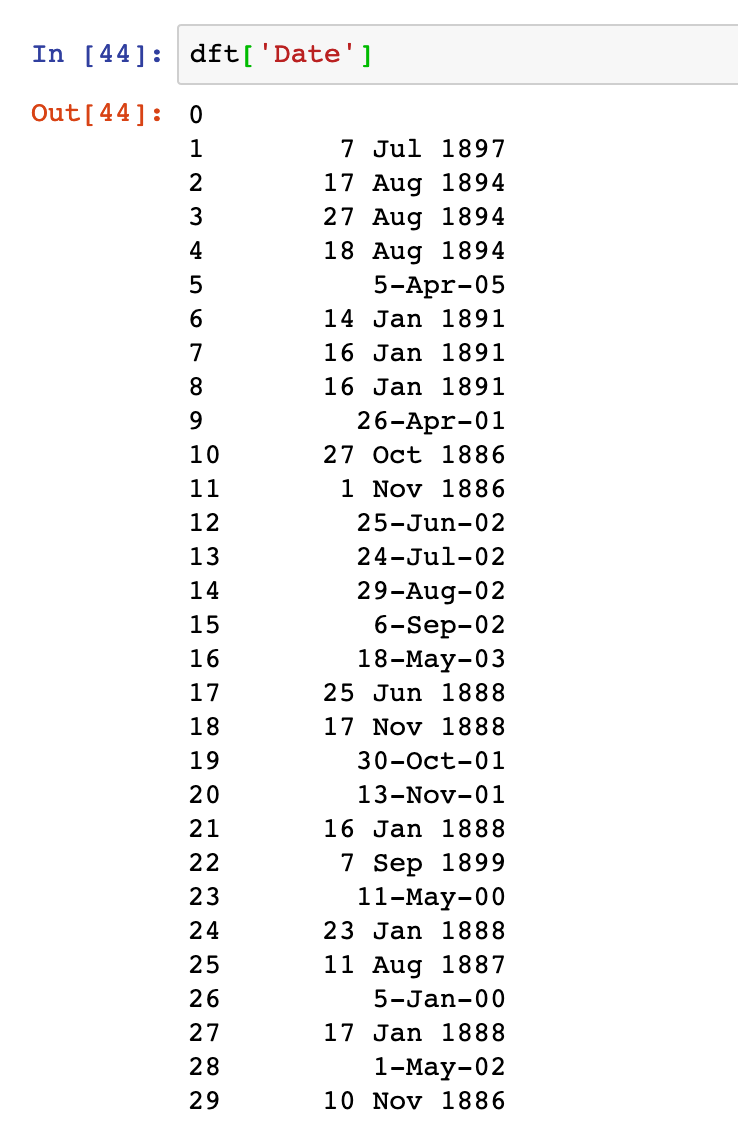
Doesn’t take much to show when there’s a problem with dates in metadata… (Yep, post 1900 dates have all jumped 100 years into the future.)
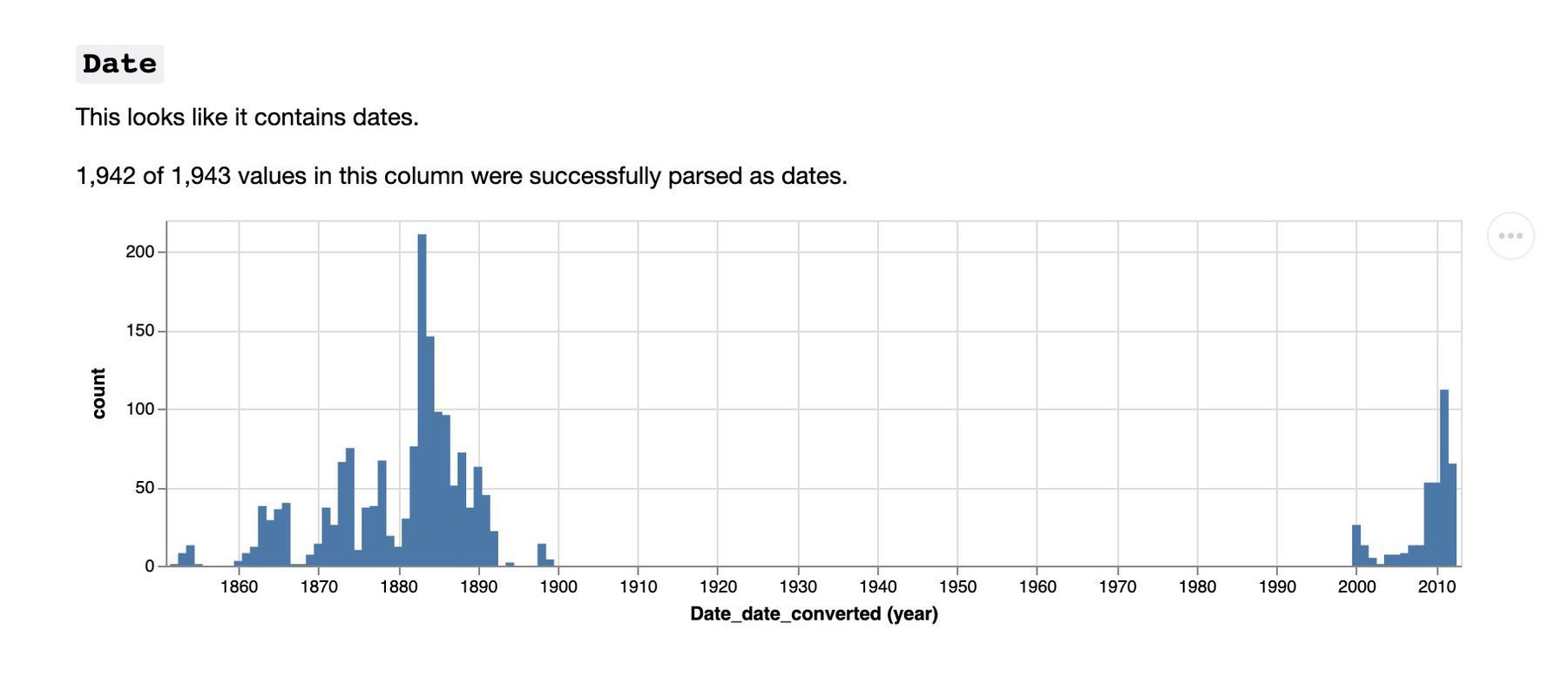
Fun day talking to the @dhpanu team at ANU about digital history possibilities. Slides/links are all online.
Currently working on a CSV explorer to give researchers an overview of the contents of GLAM datasets. Sort of like WTFCSV, but in a Jupyter notebook…
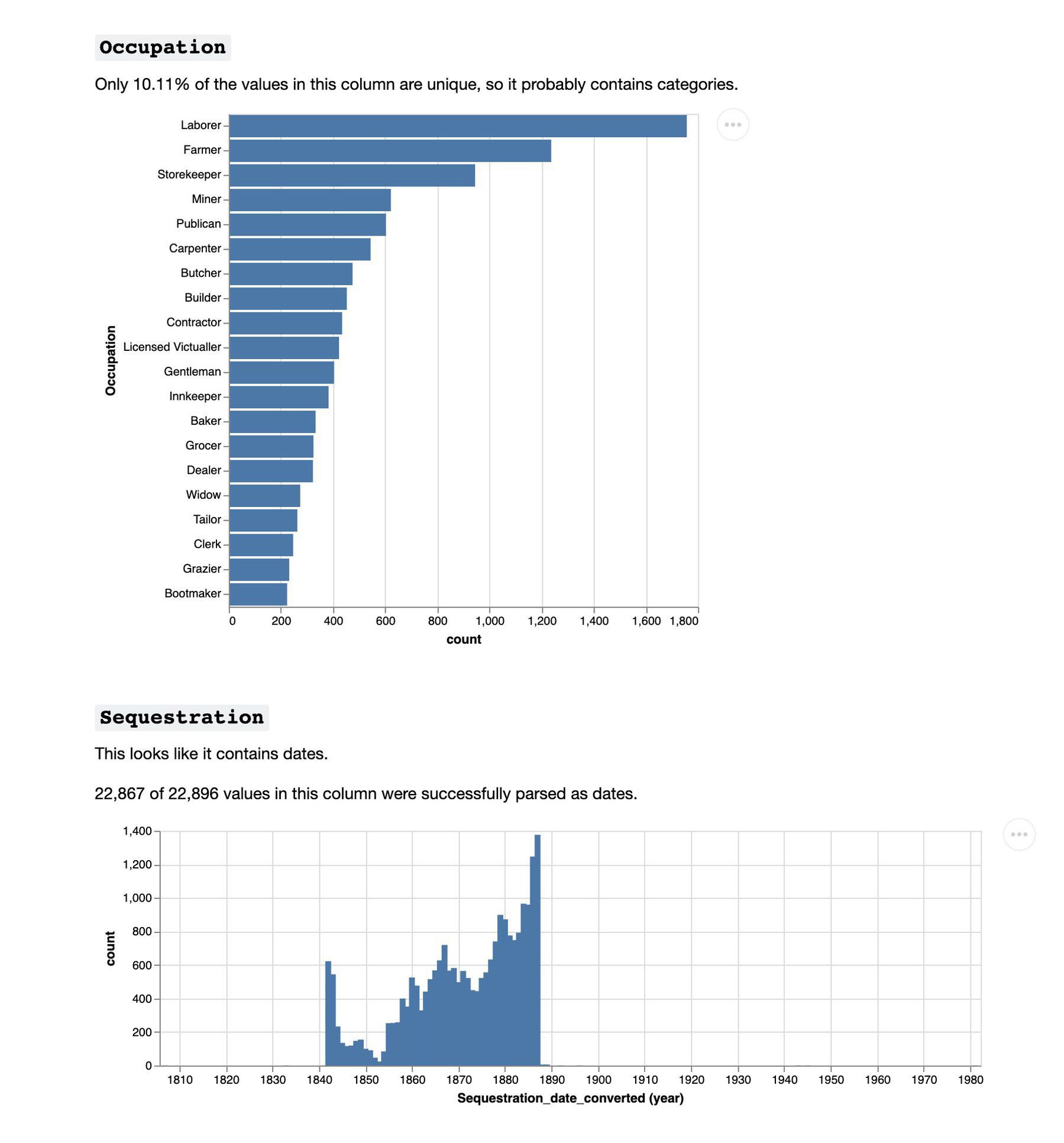
A bit more progress. Having found columns with OpenCV, I can use Tesseract to help me find the rows…
![mp-photo-alt[]=](https://cdn.uploads.micro.blog/8371/2019/0c242221bb.jpg)
