And for a taste of the recent additions to @TroveAustralia’s digitised journals, check out this thread.




And for a taste of the recent additions to @TroveAustralia’s digitised journals, check out this thread.
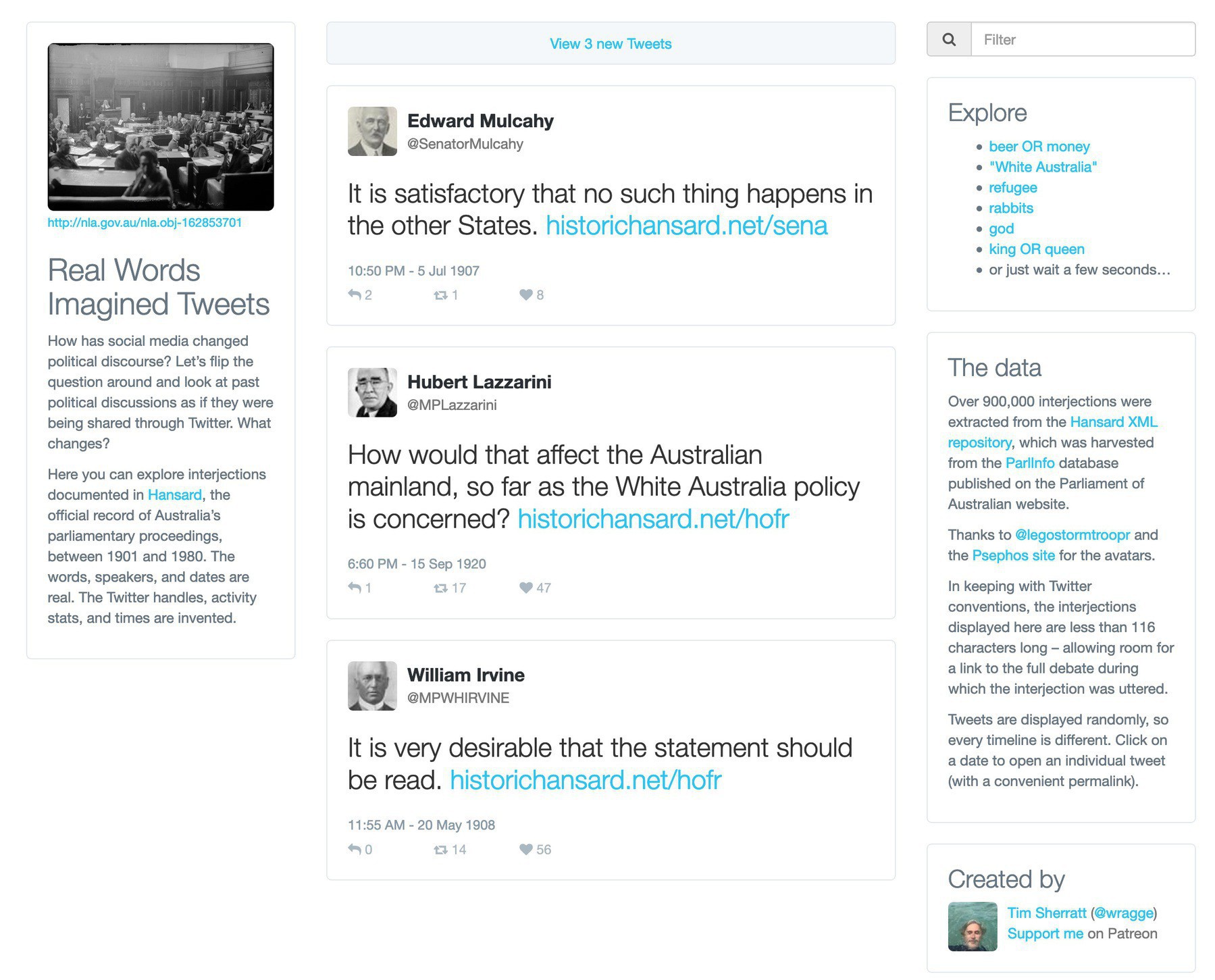
Explore @TroveAustralia’s digitised journals with this simple app. Now updated with the latest additions to Trove, and a new page for government publications. #dhhacks
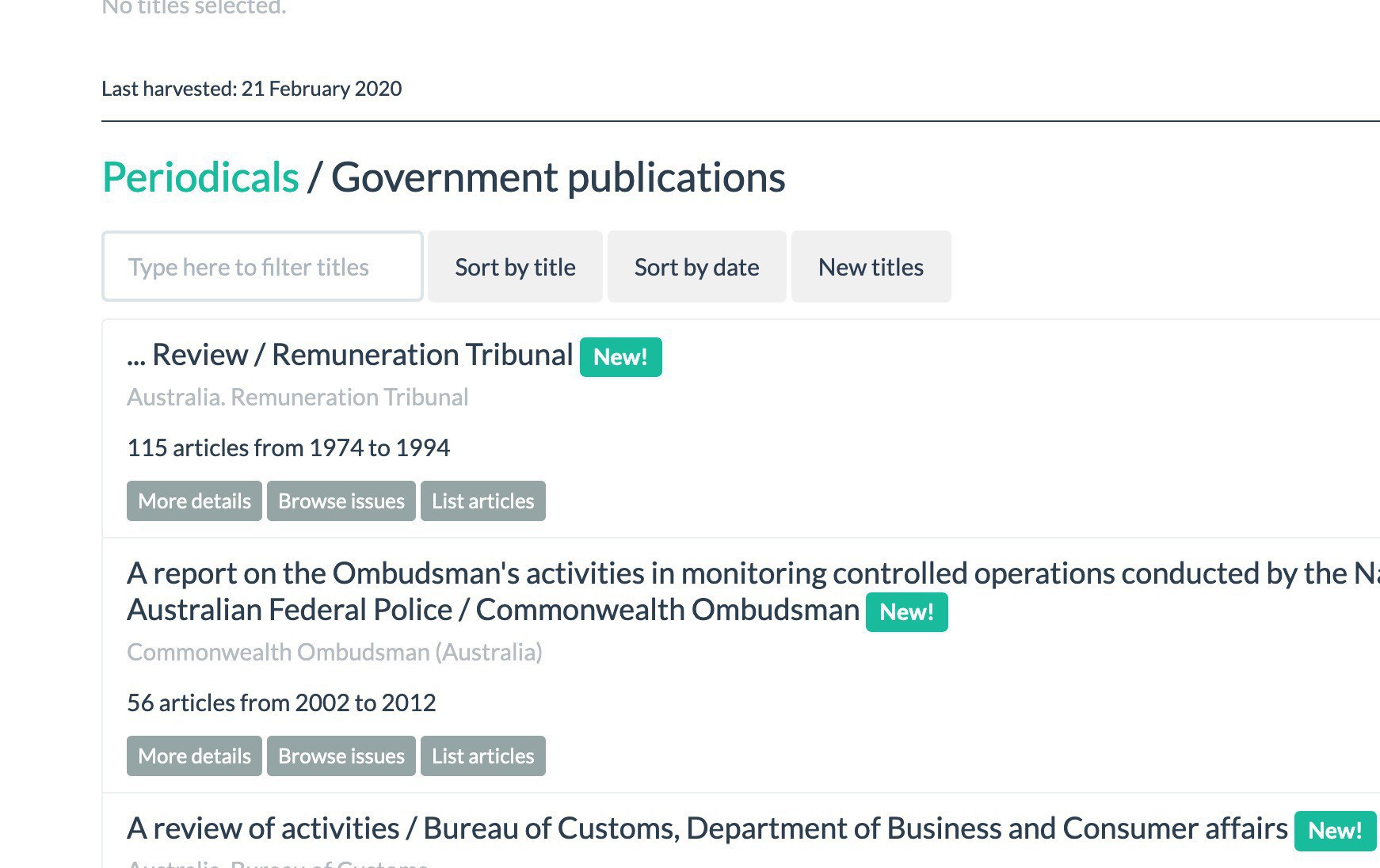
Want to save @TroveAustralia newspaper articles as images (that aren’t sliced up in annoying ways)? There’s an app for that in the #GLAMWorkbench. #dhhacks
I’ve updated the repository of data transcribed from White Australia policy records in @naagovau. Remember to follow @invisibleaus for daily snapshots.


I’ve added a few updates to my ‘Digital tools and such like…’ list for Australian historians. Hope you find it useful! #ozhist

New ‘Trove images' section added to the #GLAMWorkbench! Here you’ll find my latest Jupyter notebook harvesting data about the use of standard licences & rights statements in Trove’s picture zone. #dhhacks
Ok, the LODBook Jekyll plugin is cleaned & commented enough for me to put it aside for a while and work on the theme and data structure. I also took the opportunity to improve the way context strings are created…
Voting in the 2019 @dhawards is now open! Go and check out all the cool #DigitalHumanities projects from around the world. And while you’re there, you might like to vote for my #GLAMWorkbench in the ‘Tools’ category!

Gathering together videos of past presentations. Here they are on YT: https://www.youtube.com/playlist?list=PLAclcciEeCD3INz0o1t_E9-bkW_BWTmSv and Vimeo: vimeo.com/showcase/…
Archived via Zenodo – ‘Inigo Jones: the weather prophet’ – exploring our desire for certainty amidst a highly variable climate. doi.org/10.5281/z…
Archived via Zenodo – ‘Civilization versus the giant, winged lizards’ – a thing I wrote about the climate emergency in 2006. doi.org/10.5281/z…
One of my favourite things this year was finally publishing ‘The People Inside' with @baibi — describing the start of our @invisibleaus experiments eight years ago with records relating to the White Australia policy held by @naagovau. doi.org/10.5281/z…


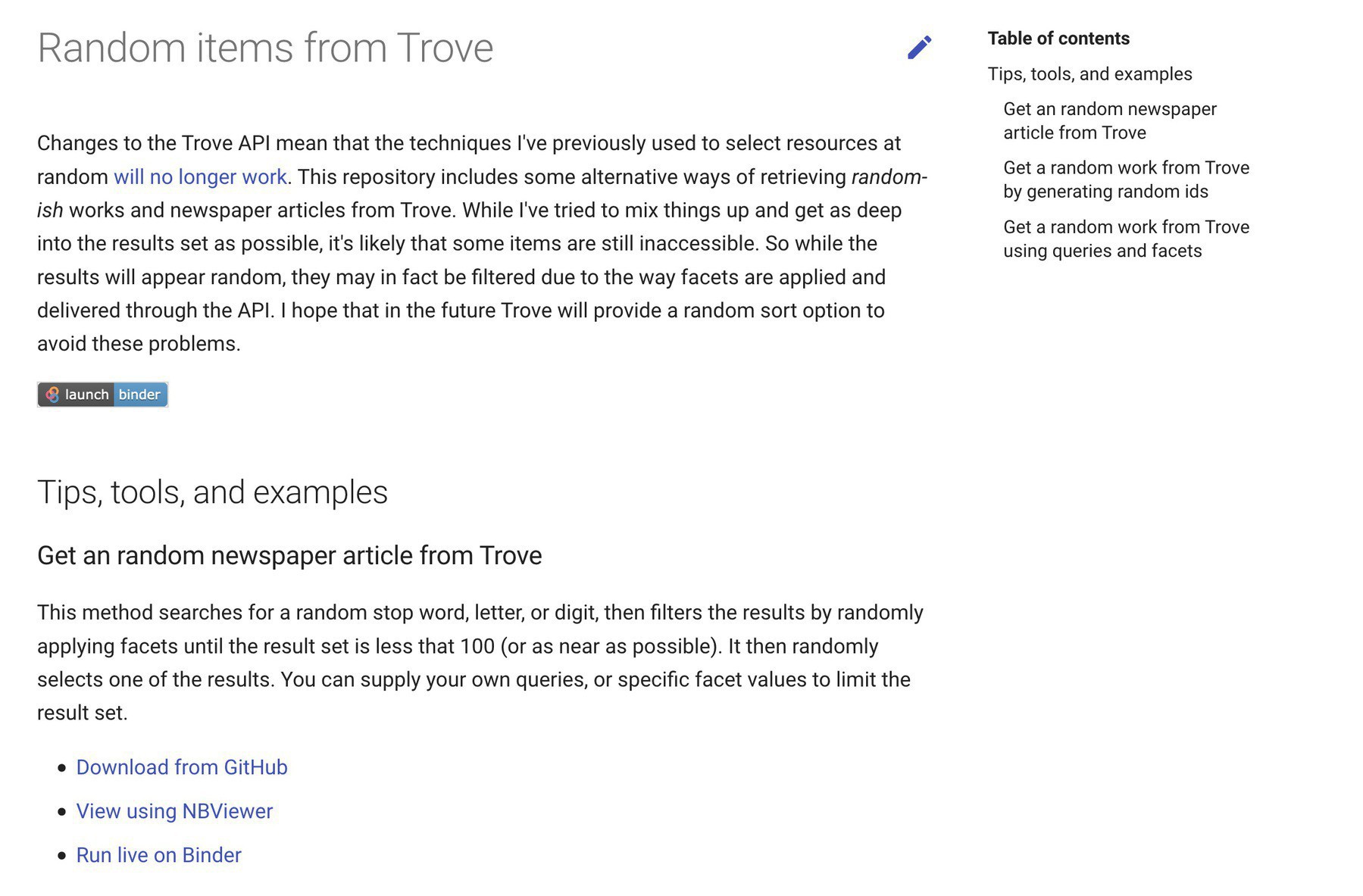
New #GLAMWorkbench section with examples of how to get random-ish works and newspaper articles from @TroveAustralia. #dhhacks
Did you make a DIY Exhibition from a @TroveAustralia list using my GitHub starter kit? If so, it’s probably broken. Never fear, here’s how you can upgrade your exhibition to use version 2 of the Trove API. #DHHacks
Today version 1 of the Trove API was decommissioned. As I explained elsewhere, this meant that a number of Trove Twitter bots also died. The problem is that version 2 of the API provides no easy way to randomly select records. Bots, and other apps that share random content, require major reworking. After a lot of experimentation, I’ve settled on a few methods for selecting random-ish results. They’re far from perfect, but they seem to work reliably.
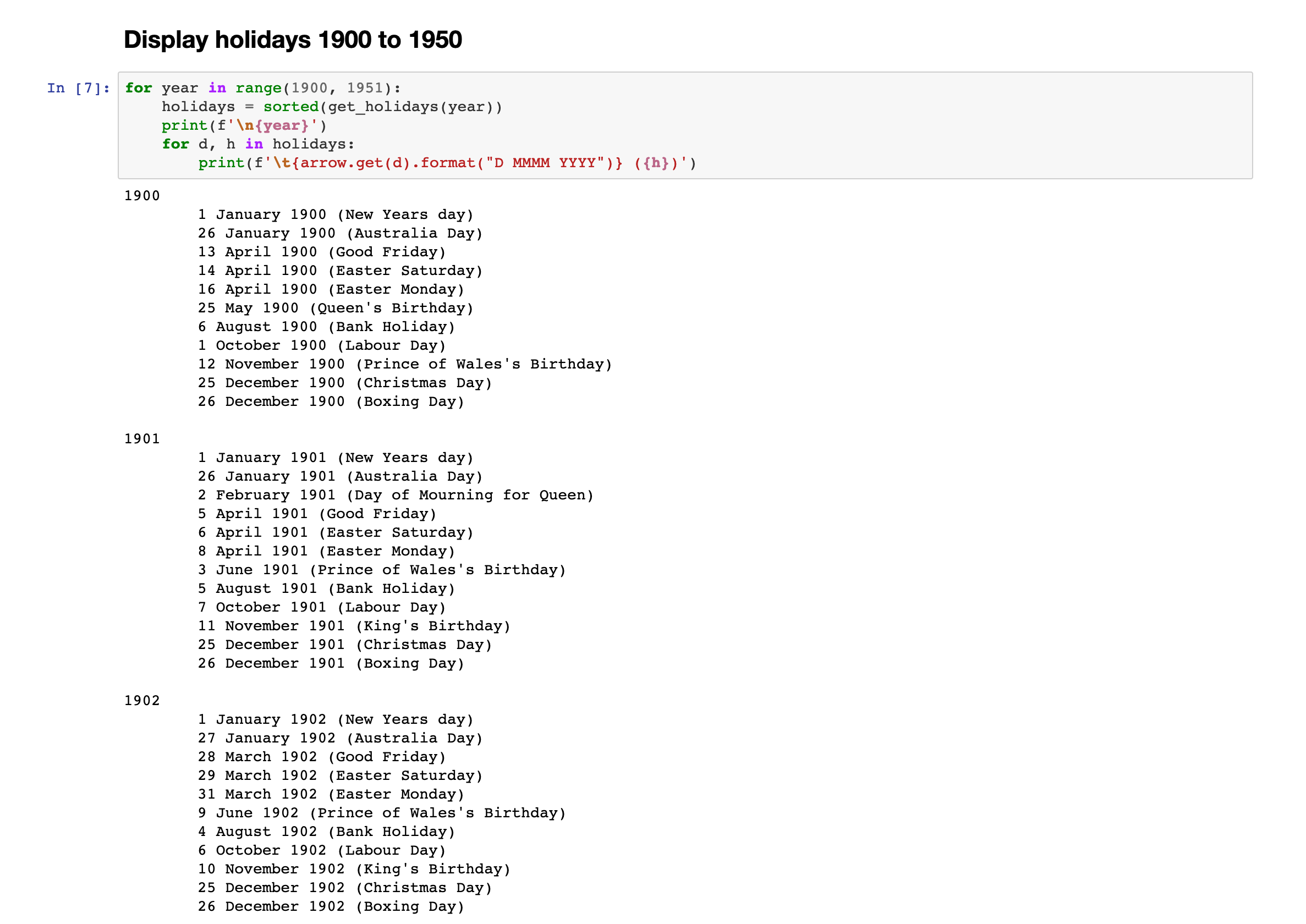
Updated my NSW public holidays data to include a few extras proclaimed by the government: nbviewer.jupyter.org/github/wr…

tl;dr Version 1 of the Trove API will be discontinued soon so Trove Twitter bots need to be upgraded. Unfortunately, Version 2 of the Trove API doesn’t support the random selection of resources, so the current behaviour of many bots will change. The problem In January 2018, I created a series of templates on Glitch that made it easy for people to build their own Trove Twitter bots. And they did!
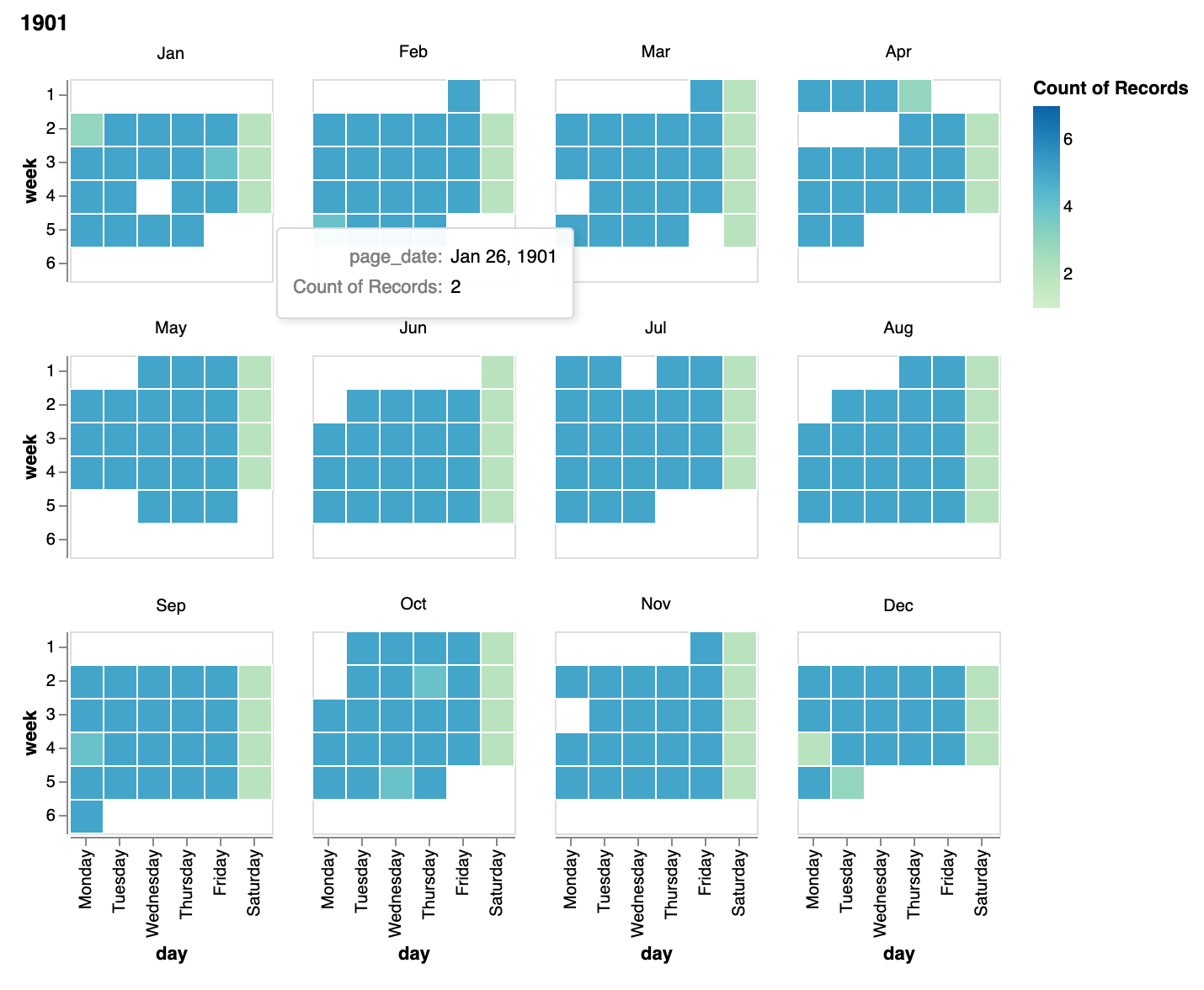
Over the last few weeks I’ve been exploring ways of recording dates for 70,000 digitised pages from Sydney Stock Exchnage records in the @TheANUArchives. Here’s the progress so far…
Here’s my attempt to calculate NSW holidays from 1900 to 1950. It’s probably incomplete, but it’s a start… nbviewer.jupyter.org/github/wr…
A couple of years ago I gave a talk in which I tried to justify what I do as research. I was going to turn it into an article, but never did. So here’s ‘The multiplication of contexts’ as a blog post.