The NAA recently changed field labels in RecordSearch, so that ‘Barcode' is now ‘Item ID’. This required an update to my recordsearch_tools screen scraper. I also had to make a few changes in the RecordSearch section of the GLAM Workbench. #dhhacks
glamworkbench
New! DigitalNZ API Query Builder added to GLAM Workbench
Wednesday, February 3, 2021
I’ve added an API Query Builder to the DigitalNZ section of the GLAM Workbench. You can use it to learn about the different parameters available from the search API, and experiment with different queries. Just get your API key from DigitalNZ, then try entering keywords and selecting options. Once you understand how the API works, you can start thinking about how you can make use of it in your own projects.
OpenGLAM fireworks! Finding open collections in DigitalNZ
Thursday, January 28, 2021
Lately I’ve been updating and expanding the notebooks in the DigitalNZ section of the GLAM Workbench. In particular, I’ve been looking at the usage facet to understand how much of the aggregated content is ‘open’. What do I mean by ‘open’? The Open Knowledge Foundation definition states that ‘open data and content can be freely used, modified, and shared by anyone for any purpose’. Obviously things that are in the public domain, such as out-of-copyright resources, are open.
New dataset and notebooks – twenty years of ABC Radio National
Monday, January 18, 2021
There’s a new GLAM Workbench section for working with data from Trove’s Music & Sound zone! Inside you’ll find out how to harvest all the metadata from ABC Radio National program records – that’s 400,000+ records, from 160 Radio National programs, over more than 20 years. It’s metadata only, so not full transcripts or audio, though there are links back to the ABC site where you might find transcripts. Most records should at least have a title, a date, the name of the program it was broadcast on, a list of contributors, and perhaps a brief abstract/summary.
GLAM Workbench wins British Library Labs Research Award!
Wednesday, December 16, 2020
Asking questions with web archives – introductory notebooks for historians has won the British Library Labs Research Award for 2020. The awards recognise ‘exceptional projects that have used the Library’s digital collections and data’. This project gave me a chance to work with web archives collections and staff from the British Library, the National Library of Australia, and the National Library of New Zealand, and was supported by the International Internet Preservation Consortium’s Discretionary Funding Program.
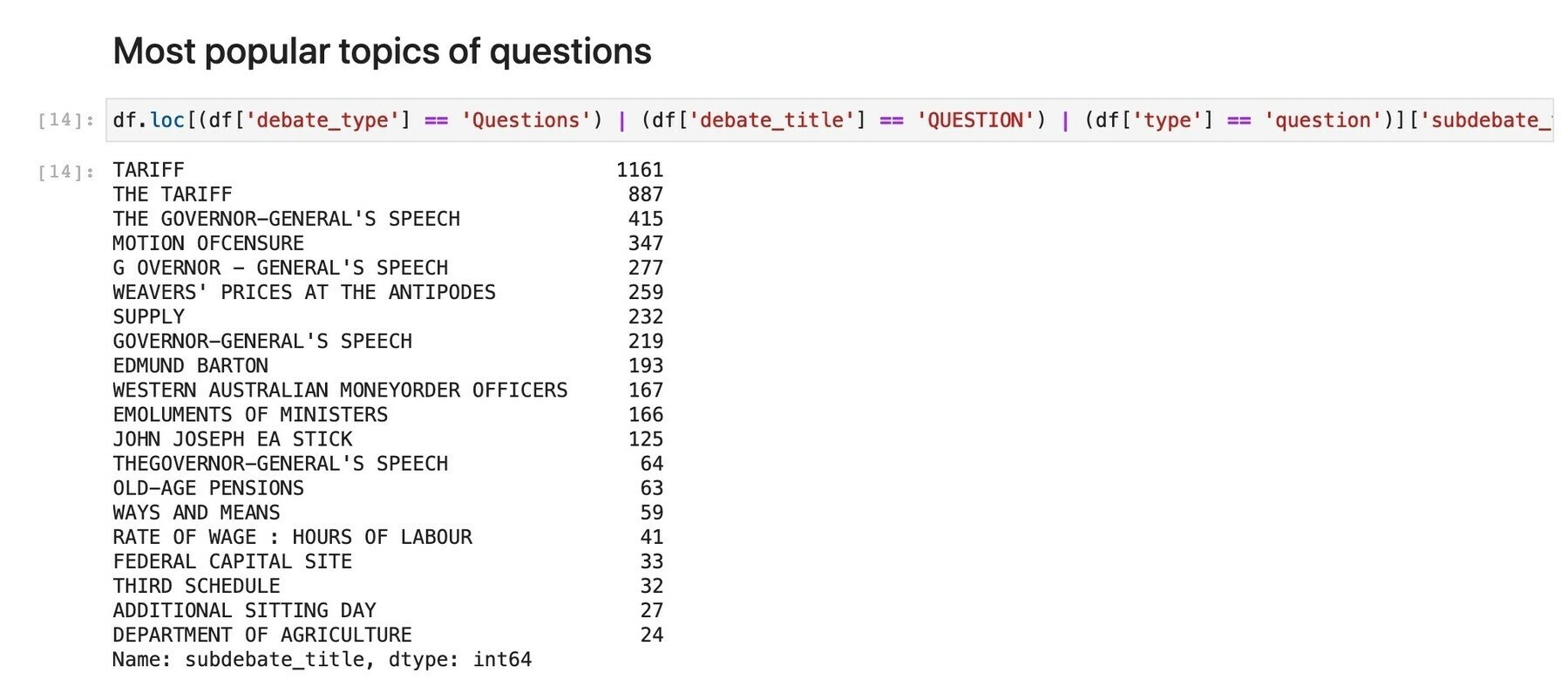
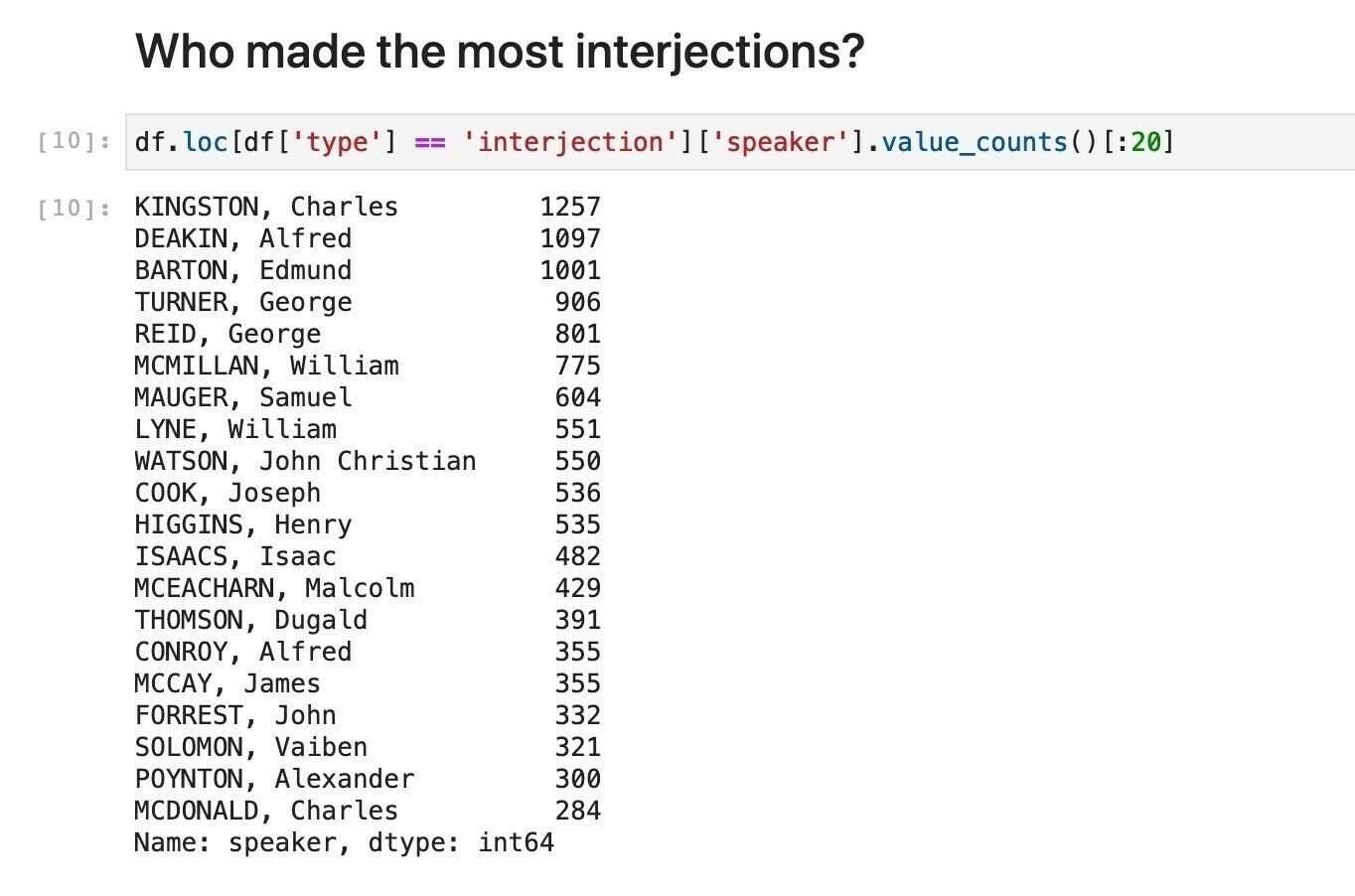
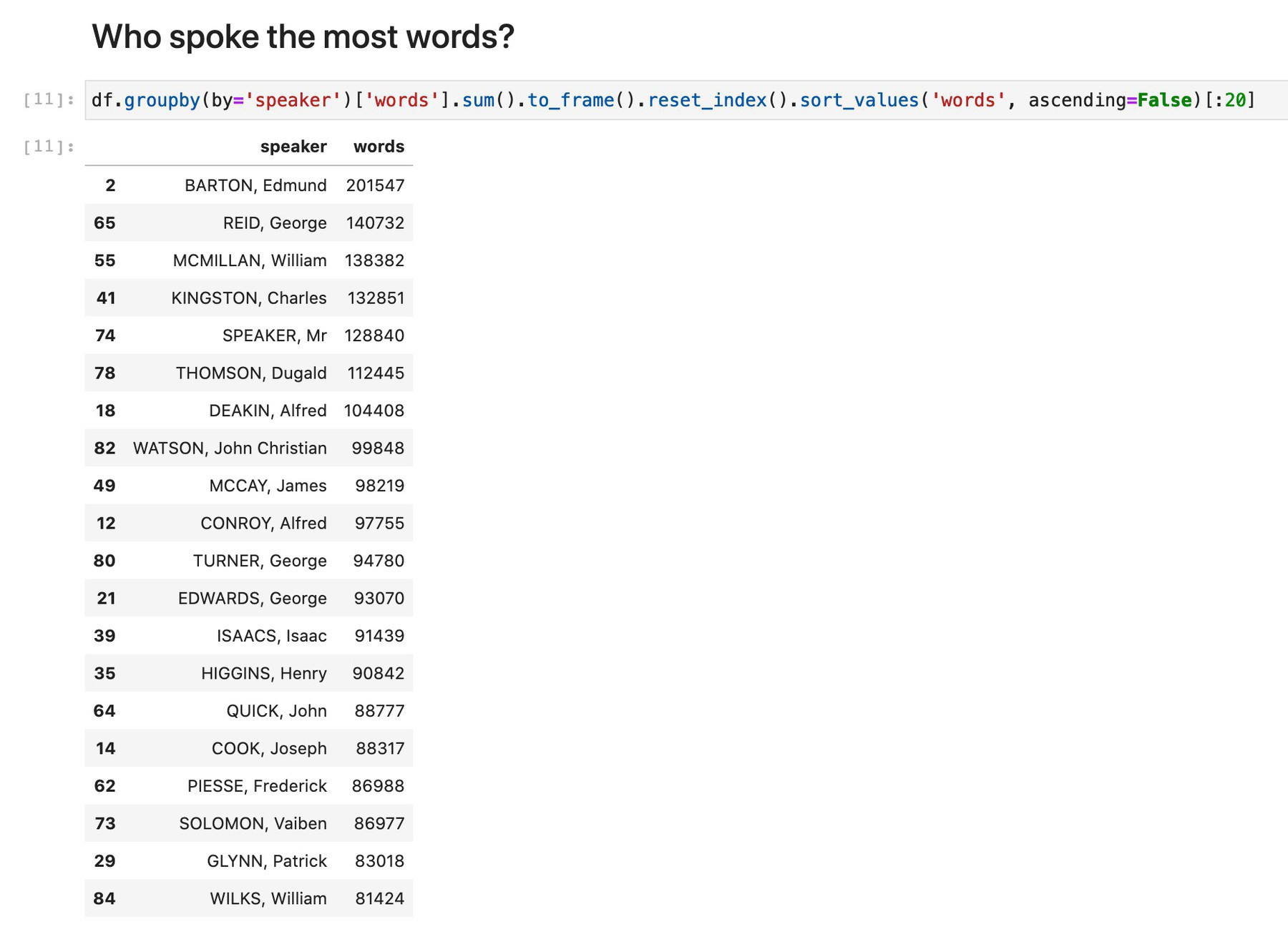
The GLAM Workbench as research infrastructure (some basic stats)
Tuesday, December 15, 2020
Repositories in the GLAM Workbench have been launched on Binder 3,529 times since the start of this year (according to data from the Binder Events log). That’s repository launches, not notebooks. Having launched a repository, users might use multiple notebooks. And of course these stats don’t include people using the notebooks in contexts other than Binder – on their own machines, servers, or services like AARNet’s SWAN. Or just viewing the notebooks in GitHub and copying code into their own projects.
Earlier this year I gave a seminar for the International Internet Preservation Consortium (IIPC) introducing the web archives section of the GLAM Workbench. The seminar is now available online: youtu.be/rVidh_wex…

Here are the slides if you want to follow along. #dhhacks
Harvest text from the Australian Women's Weekly!
Wednesday, November 25, 2020
The Trove Newspaper & Gazette Harvester has been updated to version 0.4.0. The major change is that if the OCRd text for an article isn’t available through the API, it will be automatically downloaded via the web interface. What does this mean in practice? Well previously you couldn’t harvest OCRd text from the Australian Women’s Weekly because it’s not included in API results, but now you can! You don’t need to do anything differently.
Beyond the copyright cliff of death
Friday, November 13, 2020
If you’ve done any searching in Trove’s digitised newspapers, you’ve probably noticed that there aren’t many results after 1954. This is basically because of copyright restrictions (though given the complexities of Australia’s copyright system, you can’t be sure that everything published before 1955 is out of copyright). We can visualise the impact of this by looking at the number of newspaper articles in Trove by year. You can see why I started referring to it as the copyright cliff of death.
I’ve added a new section to the GLAM Workbench for the ANU Archives. The first set of notebooks relates to the Sydney Stock exchange stock and share lists. As the content note describes:
These are large format bound volumes of the official lists that were posted up for the public to see - 3 times a day - forenoon, noon and afternoon - at the close of the trading session in the call room at the Sydney Stock Exchange. The closing prices of stocks and shares were entered in by hand on pre-printed sheets.
The volumes have been digitised, resulting in a collection of 70,000+ high resolution images. You can browse the details of each volume using this notebook.
I’ve been exploring ways of getting useful, machine-readable data out of the images. There’s more information about the processes involved in this repository. I’ve also been working on improving the metadata and have managed to assign a date and session (Morning, Noon, or Afternoon) to each page. We these, we can start to explore the content!
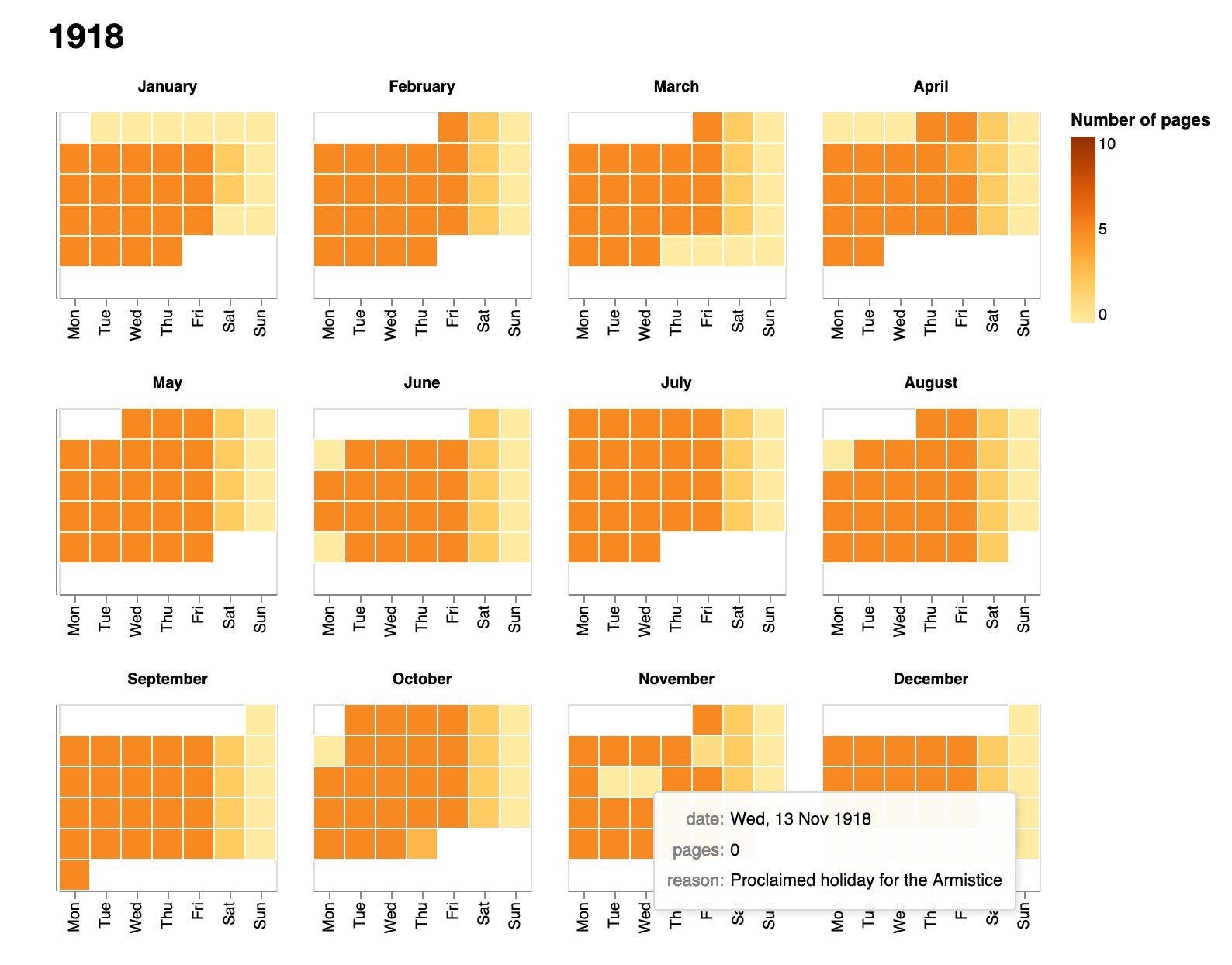
One of the notebooks creates a calendar-like view of the whole collection, showing the number of pages surviving from each trading day. This makes it easy to find the gaps and changes in process. #dhhacks
I’ve added more years to my repository of Commonwealth Hansard! The repository now includes XML-formatted text files for both houses from 1901 to 1980, and 1998 to 2005. I’ve done some more checking and confirmed that the XML files for 1981 to 1997 aren’t currently available through ParlInfo, however, the Parliamentary Library are looking into it. I’ve also created a CSV-formatted list of sitting days from 1901 to 2005 (based on ParlInfo search results). Details of the harvesting process are available in the GLAM Workbench. #dhhacks
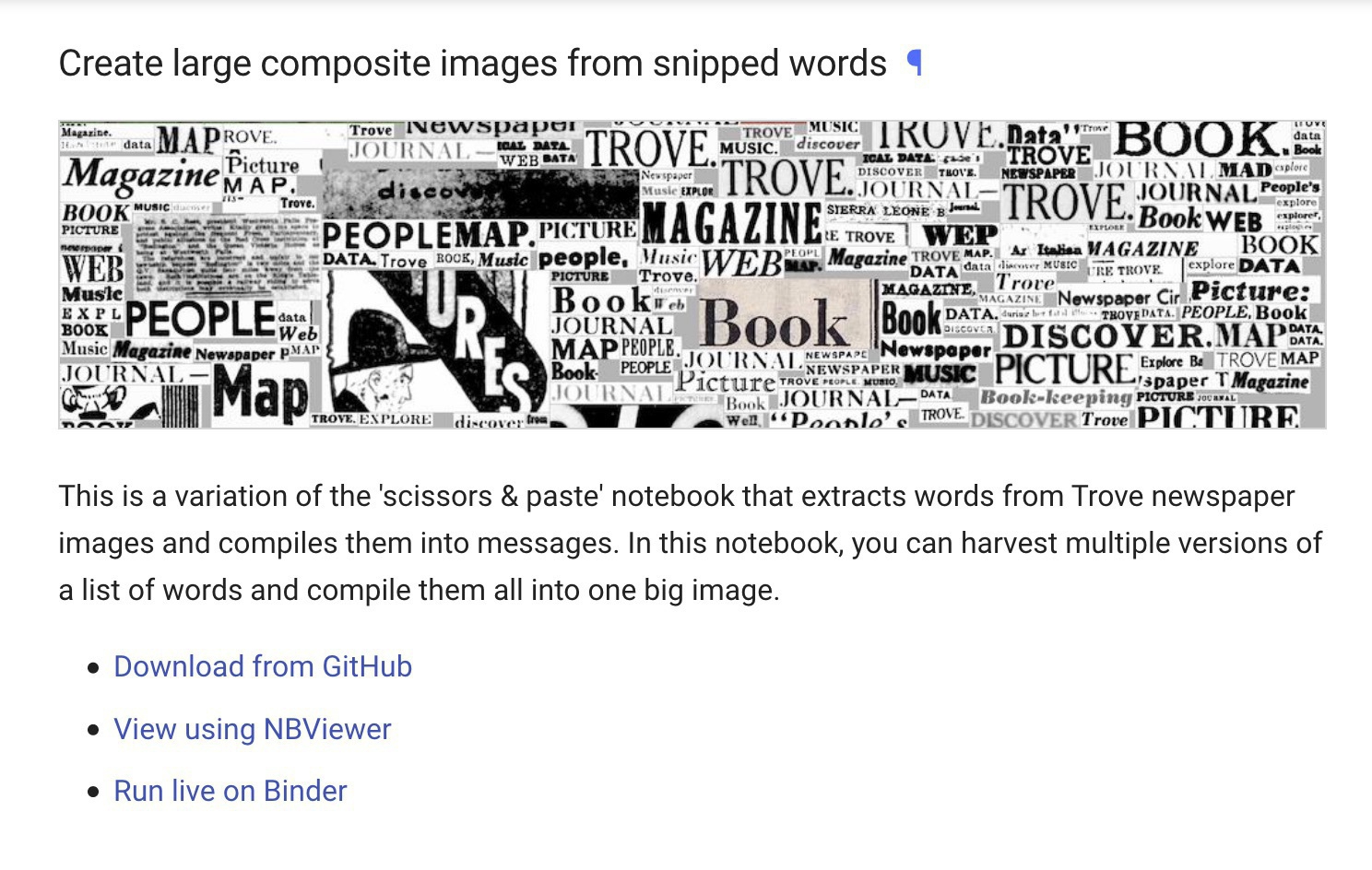
Another #GLAMWorkbench update! Snip words out of @TroveAustralia newspaper pages and create big composite images. OCR art! glam-workbench.github.io/trove-new… #dhhacks
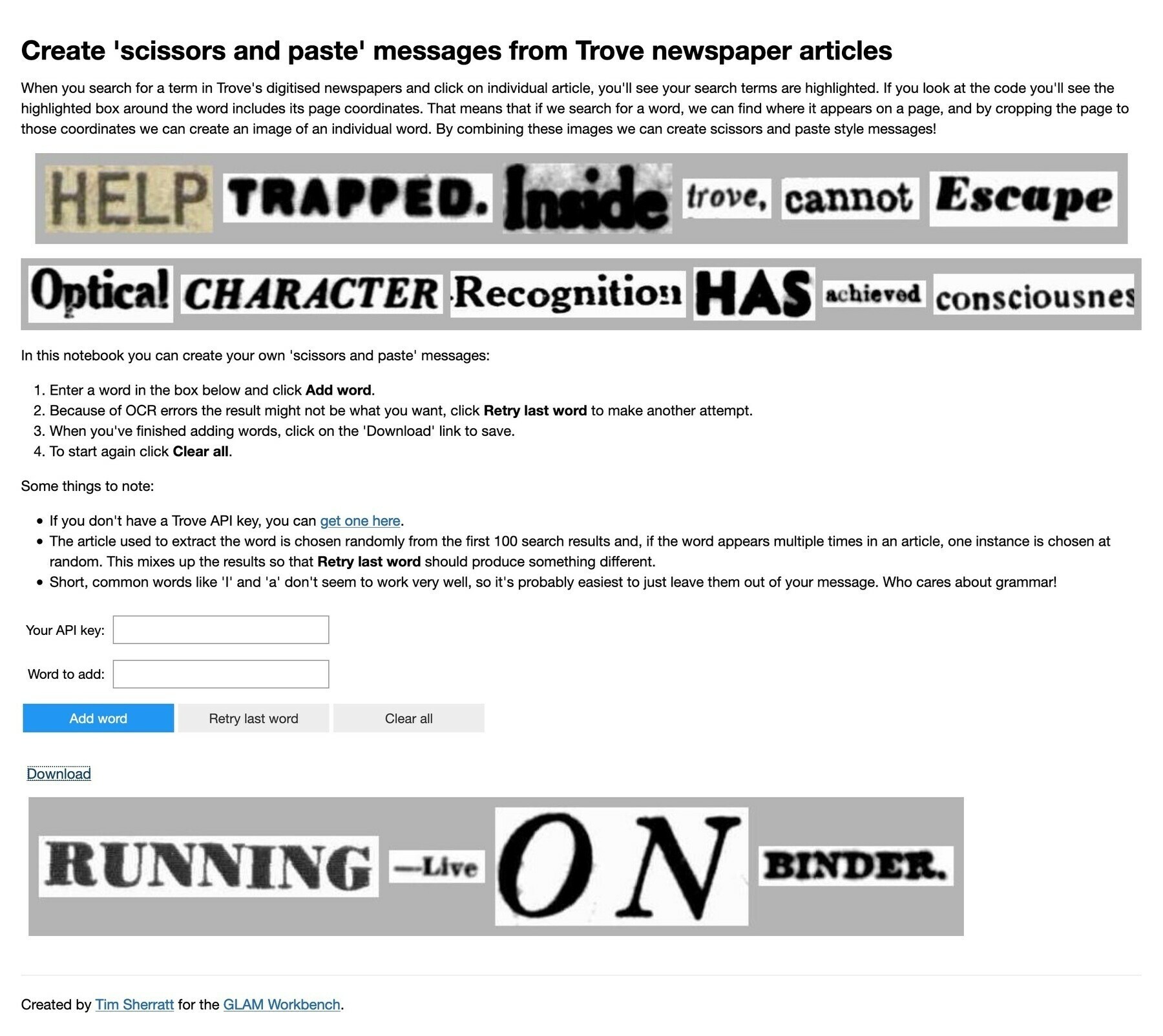
Ok, so do you want to make your own ‘scissors & paste’ messages using words from @TroveAustralia newspaper articles? Go to the notebook in #GLAMWorkbench & click on ‘Run live on Binder in Appmode’. #dhhacks
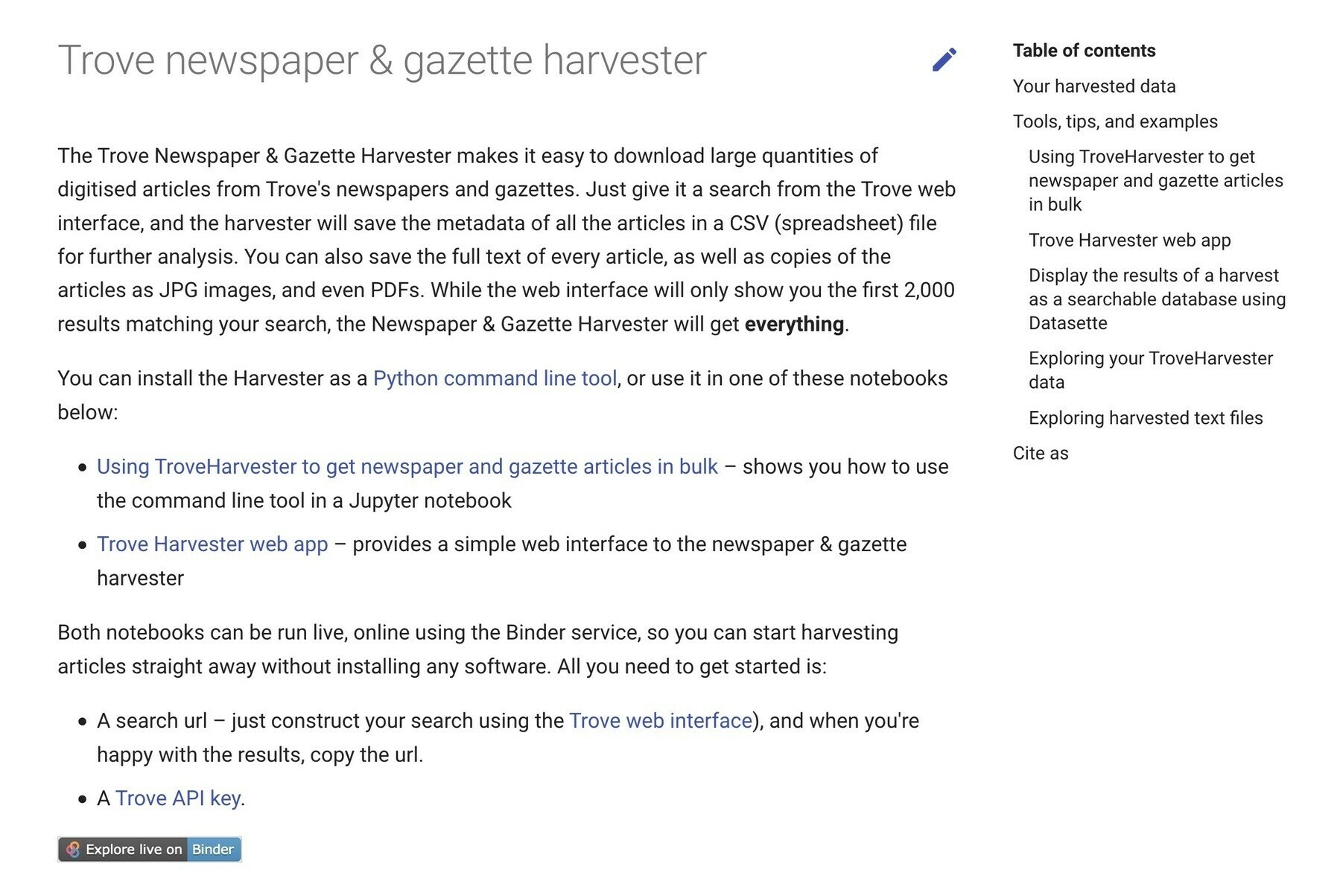
Another #GLAMWorkbench update! The Trove Harvester will now download both newspaper and gazette articles in bulk. You can optionally include full text, and save copies of the articles as images and PDFs. #dhhacks glam-workbench.github.io/trove-har…

Interested in using web archives in your research? Join us on 5/6 August for a free @netpreserve webinar introducing the tools and examples available in the new #webarchives section of the #GLAMWorkbench. There are two timeslots to cover multiple timezones: www.eventbrite.com/e/iipc-rs… and www.eventbrite.com/e/iipc-rs…

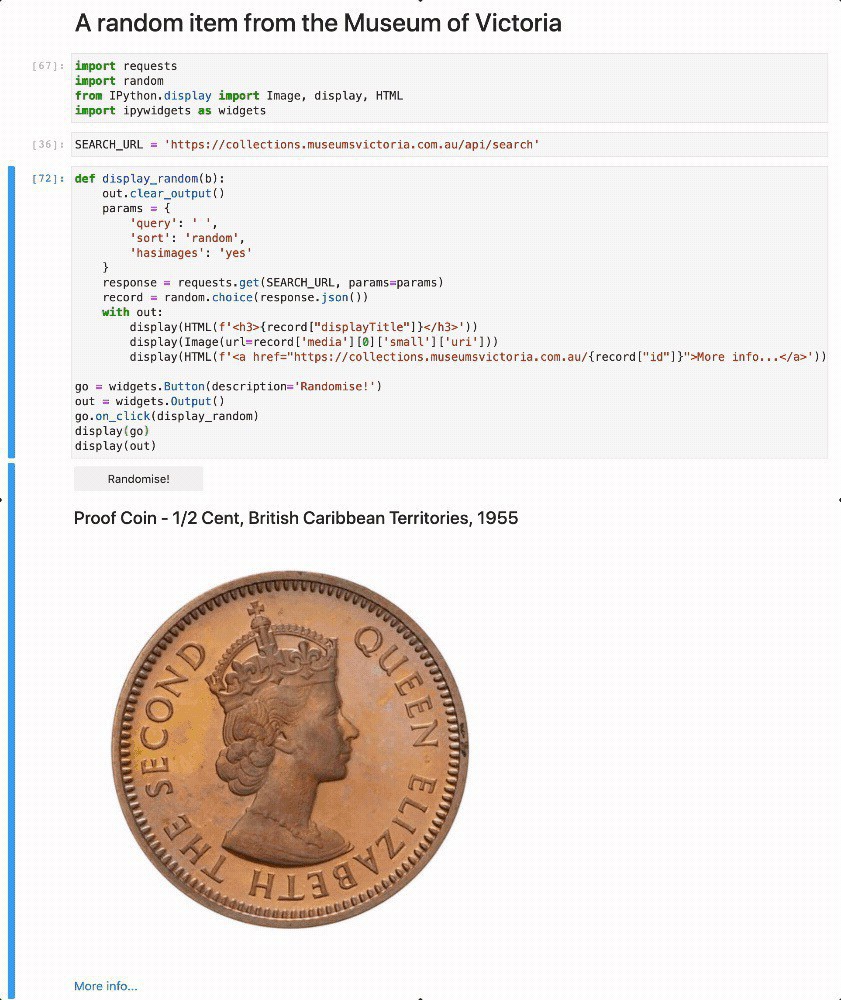
Introducing a brand new section of the #GLAMWorkbench, exploring the @MuseumsVictoria collection API. Harvest species records, display random images, and download ALL THE ANTECHINUSES! glam-workbench.github.io/museumsvi… #dhhacks


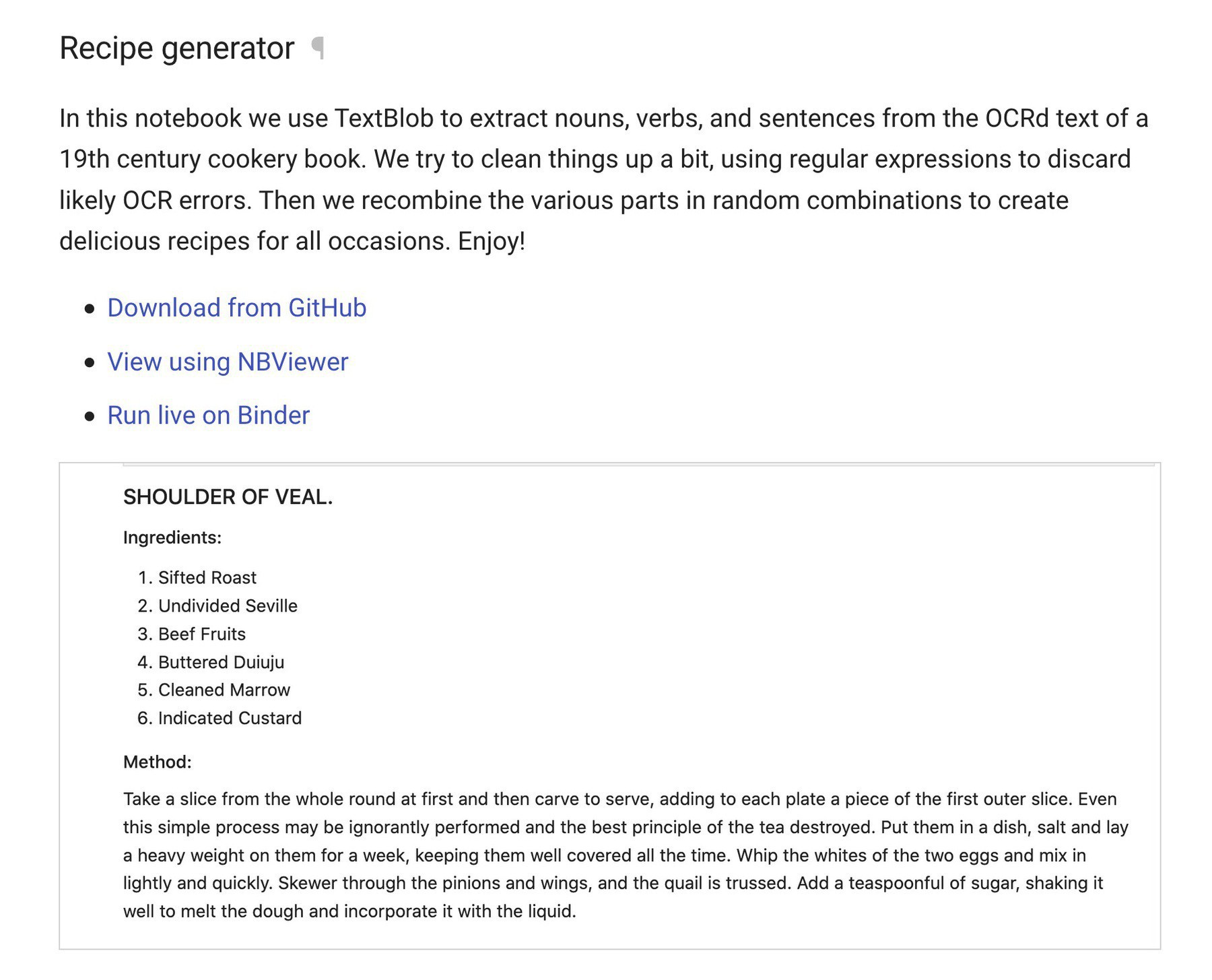
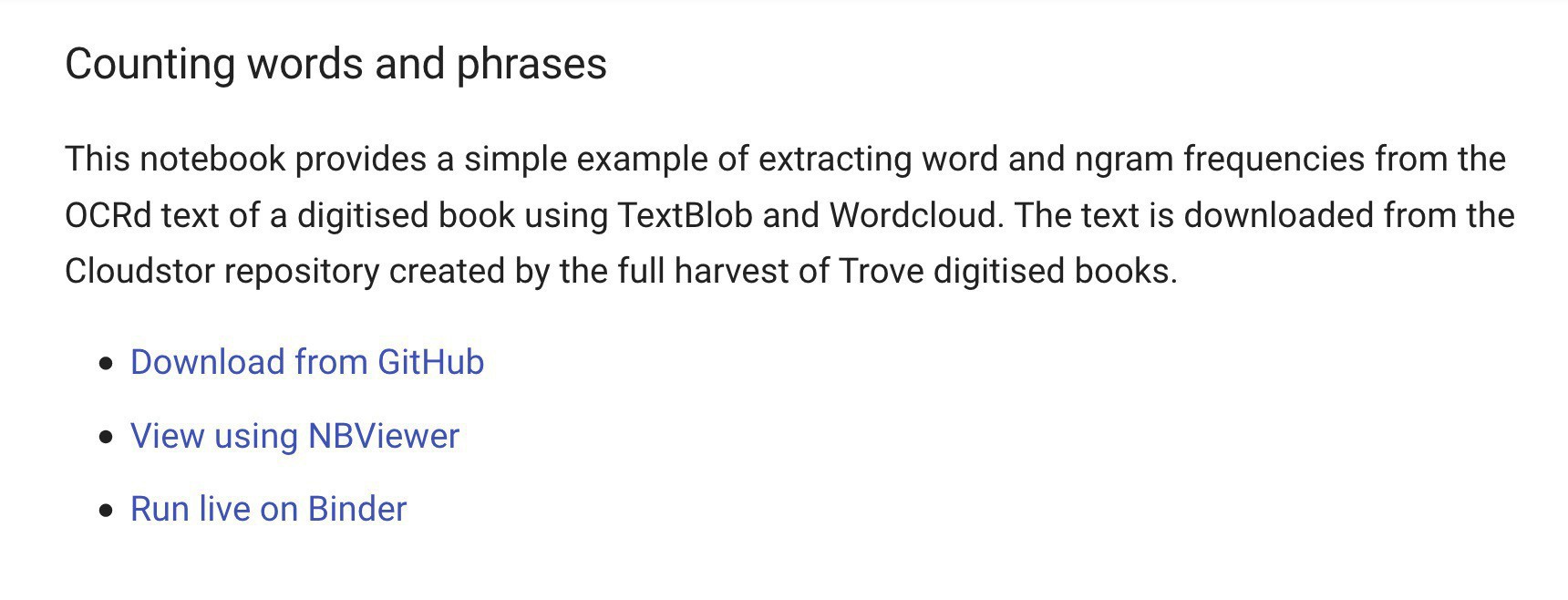
New additions to the @TroveAustralia books section of the #GLAMWorkbench – word frequency examples with OCRd text from digitised books, and a random recipe generator powered by a 19th C cook book! glam-workbench.github.io/trove-boo… #dhhacks
With the recent changes to @TroveAustralia, the Australian Women’s Weekly cover browser was retired. As a low-tech alternative, I’ve harvested all the cover images from the Women’s Weekly and saved them into PDFs for easy browsing, one for each decade. There are 2,566 images from 1933 to 1982.
Just click on the link below each image to explore the complete issue on Trove. You can also download the full collection of images from Cloudstor. There’s a CSV file containing all the issue metadata.
The notebook used to harvest the images is in the Trove newspapers section of the GLAM Workbench. You could easily adapt the notebook to harvest the front pages of any newspaper. #dhhacks

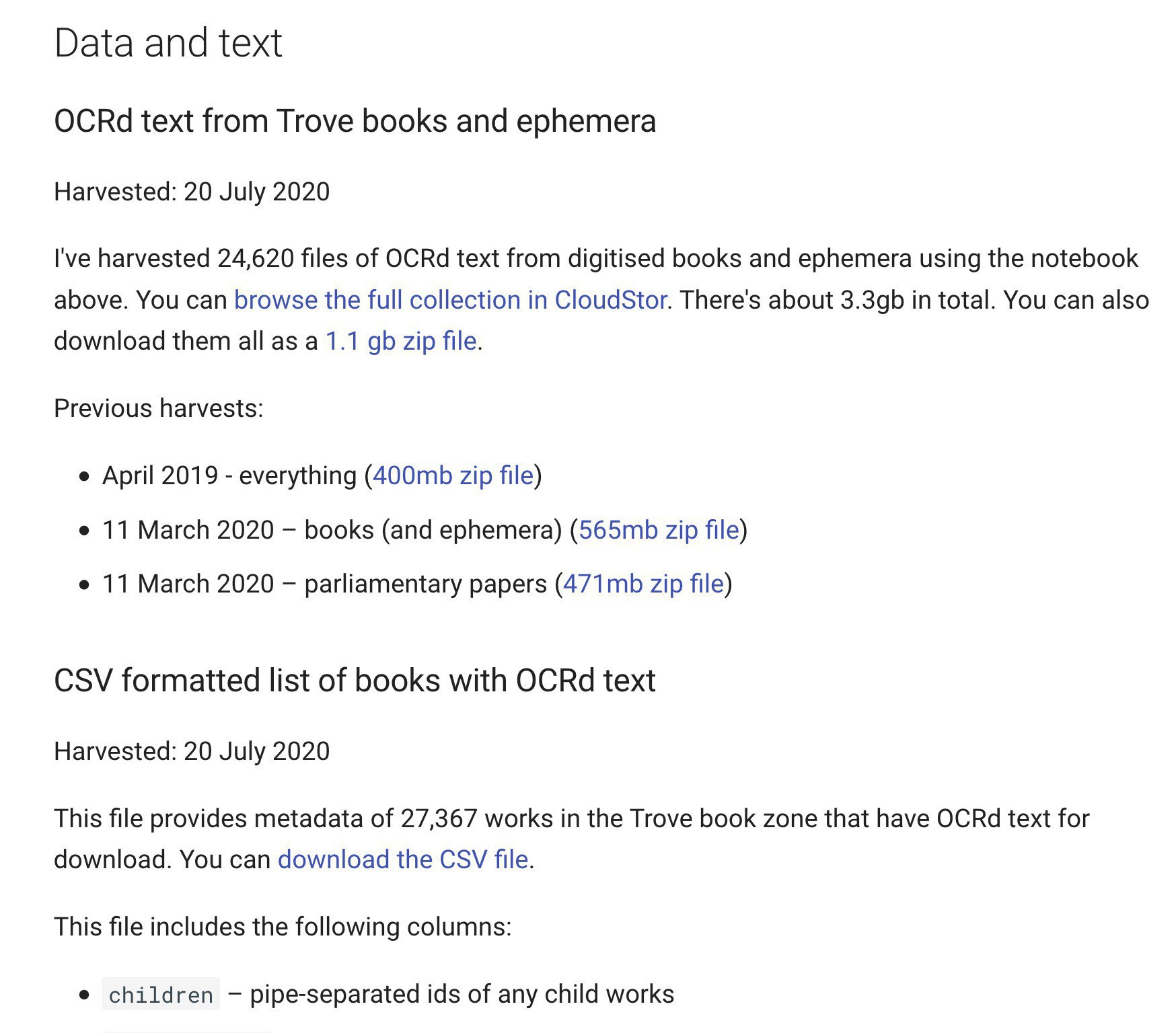
The Trove books section of the #GLAMWorkbench has been updated. There’s a fresh harvest of OCRd text & the notebooks have been changed to work with the new @TroveAustralia interface. Download & explore 24,620 files (3gb) of OCRd text! #dhhacks
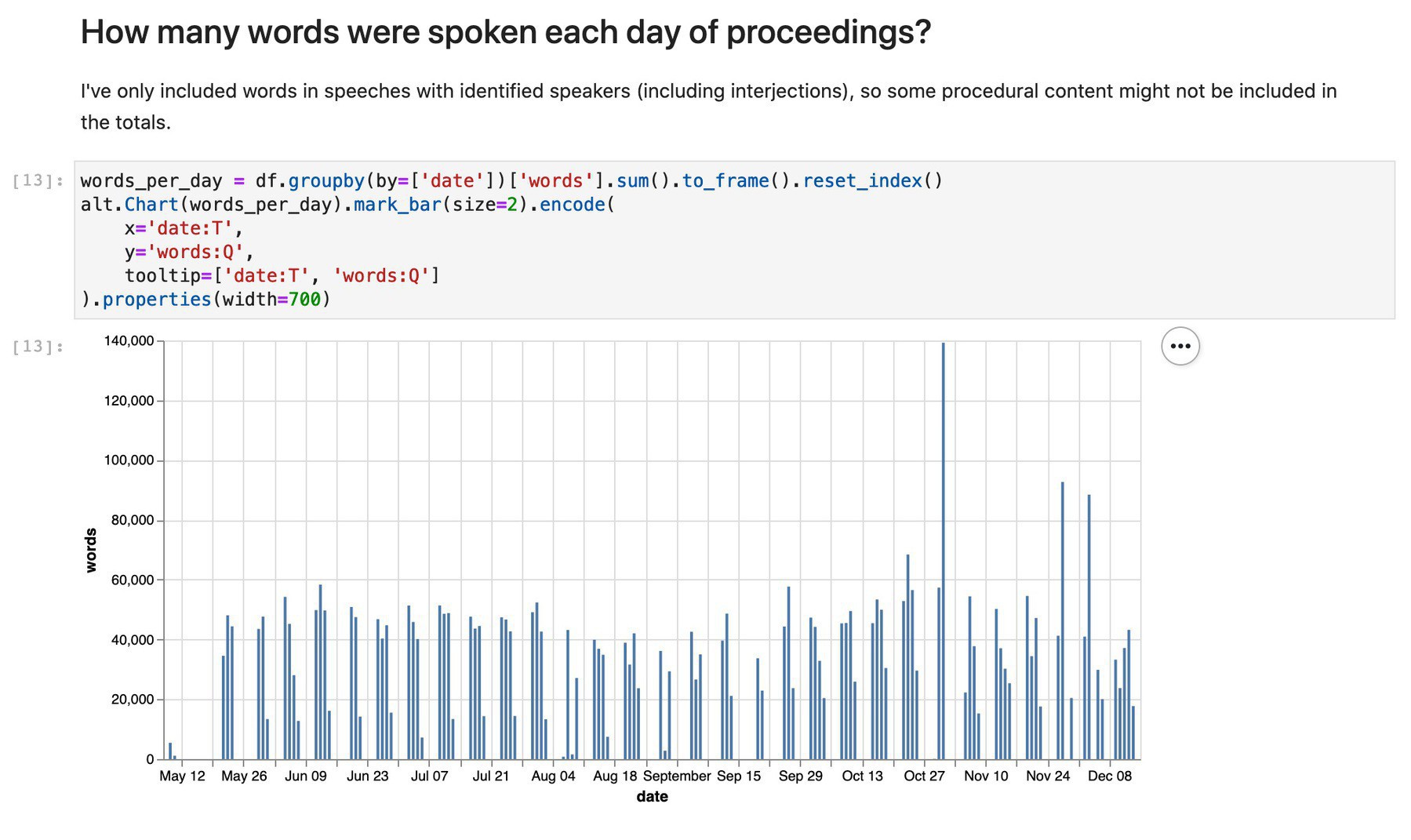
Revisiting my Historic Hansard XML repository & realising how easy it is to load files as needed via the GitHub API & explore with Pandas & Jupyter. This #GLAMWorkbench notebook helps you explore a particular year/house. #dhhacks
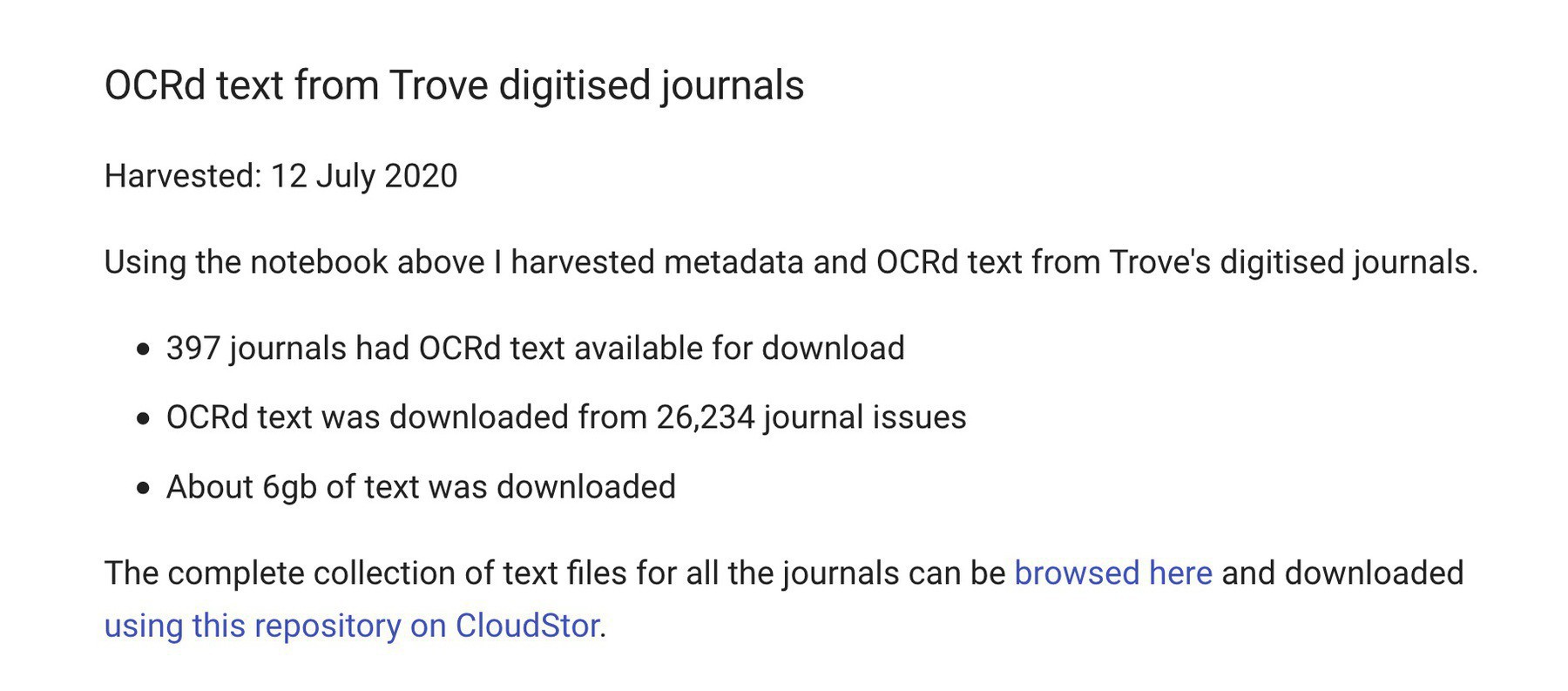
The Trove Journals section of the #GLAMWorkbench has been updated to work with the new @TroveAustralia interface! I’ve also re-harvested ALL the OCRd text from digitised journals — 6gb of text from 397 journals now downloadable in bulk from CloudStor. #dhhacks
New in #GLAMWorkbench! After you’ve used the @TroveAustralia Newspaper Harvester to download lots & lots of articles, try exploring the results in Datasette. This notebook sets everything up, you can even add full text search & images! #dhhacks

Download newspaper articles in bulk! The Trove Newspaper Harvester has been updated to work with the new @TroveAustralia interface. I’ve also added the ability to save articles as .jpg images! The easiest way to get started is via the #GLAMWorkbench. #dhhacks



New GLAM Workbench section on web archives!
Wednesday, May 27, 2020
We tend to think of a web archive as a site we go to when links are broken – a useful fallback, rather than a source of new research data. But web archives don’t just store old web pages, they capture multiple versions of web resources over time. Using web archives we can observe change – we can ask historical questions. But web archives store huge amounts of data, and access is often limited for legal reasons.
Thanks to @NetPreserve, I’ve been spending time lately working on a set of web archive exploration notebooks for the #GLAMWorkbench. Here’s an example to create/compare screenshots of captures. #dhhacks
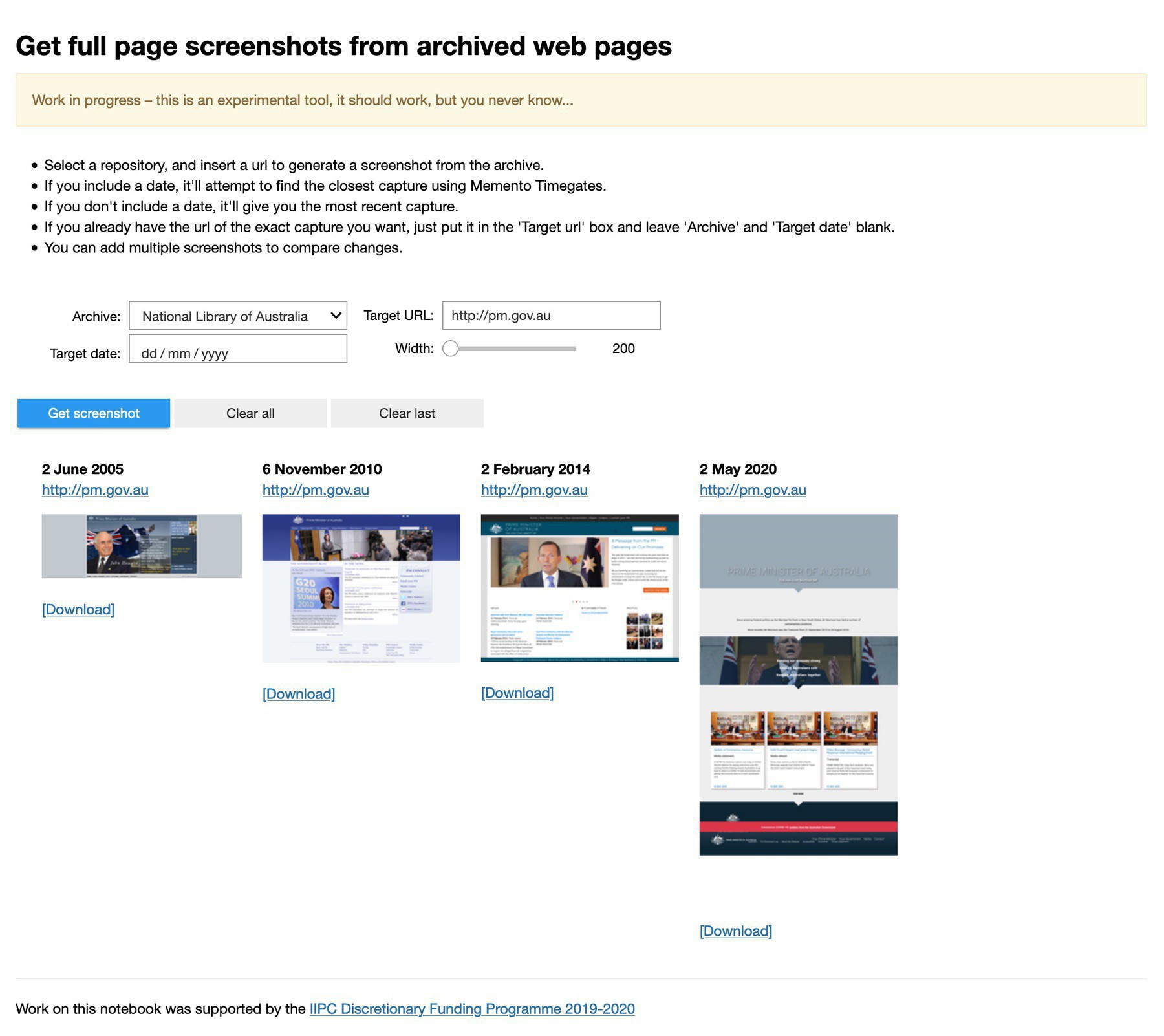
The GLAM CSV Explorer has had a few updates — you can now filter by organisation, and upload your own CSV files! #GLAMWorkbench Try it live on Binder.
Buildings might be closed, but the data is open – explore hundreds of datasets from Australian GLAM organisations!
Tuesday, March 31, 2020
For a couple of years I’ve been harvesting datasets created or published by Australian GLAM organisations through government data portals. I’ve just completed the latest harvest, and there’s now 369 datasets, containing 983 files, from 23 GLAM organisations. 628 of these files are in CSV (spreadsheet) format. There’s a number of ways that you can explore the harvested data. You can browse a big list of datasets, or download a CSV containing all the harvested data or just those formatted as CSVs.
My harvest of OCRd text from @TroveAustralia digitised books, ephemera, and parliamentary papers has been updated! There’s now 19,795 text files (about 3gb) to explore! Harvesting details and links to browse/download files from Cloudstor are in the #GLAMWorkbench. #dhhacks



I’ve added some more documentation to the Trove Newspaper Harvester page in the #GLAMWorkbench. Get your @TroveAustralia newspaper articles in bulk! #dhhacks #collectionsasdata
New section added to the #GLAMWorkbench with examples from @Library_Vic! #slvdata #dhhacks #collectionsasdata
