Ok, I’ve created a Zenodo community for datasets documenting changes in the content and structure of Trove. Lots more to add… zenodo.org/communiti…
Ok, I’ve created a Zenodo community for datasets documenting changes in the content and structure of Trove. Lots more to add… zenodo.org/communiti…
Coz I love making work for myself, I’ve started pulling datasets out of #GLAMWorkbench code repos & creating new data repos for them. This way they’ll have their own version histories in Zenodo. Here’s the first: github.com/GLAM-Work…
Ahead of my session at #OzHA2022 tomorrow, I’ve updated the NAA section of the #GLAMWorkbench. Come along to find out how to harvest file details, digitsed images, and PDFs, from a search in RecordSearch! github.com/GLAM-Work…
55,633 items digitised by the National Archives of Australia last week. Including:
![A2571, Name Index Cards, Migrants Registration [Bonegilla], 33686 files digitised; B884, Citizen Military Forces Personnel Dossiers, 1939-1947, 10150 files digitised; A2572, Name Index Cards, Migrants Registration [Bonegilla], 8748 files digitised; C610, Australian Women's Land Army - personnel cards, alphabetical series, 961 files digitised; A9301, RAAF Personnel files of Non-Commissioned Officers (NCOs) and other ranks, 1921-1948, 735 files digitised; D874, Still photograph outdoor and studio negatives, annual single number series with N prefix (and progressive alpha infix A-K from 1948-1957), 624 files digitised; B883, Second Australian Imperial Force Personnel Dossiers, 1939-1947, 163 files digitised; J853, Architectural plans, annual single number series with alpha (denoting Papua New Guinea and discipline) prefix and/or alpha/numeric (denoting size and amendment) suffix, 161 files digitised; A14487, Royal Australian Air Force Air Board and Air Council Agendas, Submissions and Determinations - Master Copy, 102 files digitised; A2478, Non-British European migrant selection documents, 21 files digitised; D4881, Alien registration cards, alphabetical series, 18 files digitised; A471, Courts-Martial files [including war crimes trials], single number series, 10 files digitised; A1877, British migrants - Selection documents for free or assisted passage (Commonwealth nominees), 9 files digitised; A13860, Medical Documents - Army (Department of Defence Medical Documents), 9 files digitised; A1196, Correspondence files, multiple number series [Class 501] [501-539] [Classified] [Main correspondence files series of the agency], 9 files digitised; B78, Alien registration documents, 8 files digitised; A712, Letters received, annual single number series with letter prefix or infix, 6 files digitised; A12372, RAAF Personnel files - All Ranks [Main correspondence files series of the agency], 6 files digitised; AP476/4, Applications etc. for registration of copyright of literary, dramatic and musical productions, pictures etc., 6 files digitised; A714, Books of duplicate certificates of naturalization A(1)[Individual person] series, 6 files digitised;](https://cdn.uploads.micro.blog/8371/2022/074b17c896.png)
Newspapers added to Trove last week
Noticed that QueryPic was having a problem with some date queries. Should be fixed in the latest release of the Trove Newspapers section of the #GLAMWorkbench: glam-workbench.net/trove-new… #maintenance #researchinfrastructure
The Trove Newspapers section of the #GLAMWorkbench has been updated! Voilá was causing a problem in QueryPic, stopping results from being downloaded. A package update did the trick! Everything now updated & tested. glam-workbench.net/trove-new…
Some more #GLAMWorkbench maintenance – this app to download a high-res page images from Trove newspapers now doesn’t require an API key if you have a url, & some display problems have been fixed. trove-newspaper-apps.herokuapp.com/voila/ren…
The Trove Newspaper and Gazette Harvester section of the #GLAMWorkbench has been updated! No major changes to notebooks, just lots of background maintenance stuff such as updating packages, testing, linting notebooks etc. glam-workbench.net/trove-har…
Main changes to individual Trove newspapers last week:
+19,862 articles in Daily News (WA)
+10,822 articles in Dalgety’s Review (WA)
+13,352 articles in Manning River News… (NSW)
Changes to Trove newspapers last week:
+86,761 articles
+16,367 articles with corrections
+5,355 articles with tags
+417 articles with comments
42,472 files were digitised by the National Archives of Australia last week.
36,238 of these were migrant registration cards from Bonegilla (A2571 & A2572).
Here’s a screenshot of the top twenty series. More info: github.com/wragge/na…
![A2571, Name Index Cards, Migrants Registration [Bonegilla], 31307 files digitised; B884, Citizen Military Forces Personnel Dossiers, 1939-1947, 4981 files digitised; A2572, Name Index Cards, Migrants Registration [Bonegilla], 4931 files digitised; C610, Australian Women's Land Army - personnel cards, alphabetical series, 566 files digitised; J853, Architectural plans, annual single number series with alpha (denoting Papua New Guinea and discipline) prefix and/or alpha/numeric (denoting size and amendment) suffix, 292 files digitised; A9301, RAAF Personnel files of Non-Commissioned Officers (NCOs) and other ranks, 1921-1948, 188 files digitised; B883, Second Australian Imperial Force Personnel Dossiers, 1939-1947, 56 files digitised; K1145, Certificates of Exemption from Dictation Test, annual certificate number order, 17 files digitised; SP551/1, Log books of HMC [Her Majesty's Colonial], HM [His/Her Majesty's] and HMA [Her Majesty's Australian] Ships, 9 files digitised; F1, Correspondence files, annual single number series [Main correspondence files series of the agency], 7 files digitised; A1196, Correspondence files, multiple number series [Class 501] [501-539] [Classified] [Main correspondence files series of the agency], 6 files digitised; B78, Alien registration documents, 6 files digitised; A12372, RAAF Personnel files - All Ranks [Main correspondence files series of the agency], 4 files digitised; SP1122/1, General correspondence files, multiple number series and annual single number with 'N' (New South Wales) prefix, 4 files digitised; A9300, RAAF Officers Personnel files, 1921-1948, 4 files digitised; MP508/1, General correspondence files, multiple number series, 3 files digitised; C321, Case files, annual single number series with 'N' (NSW) prefix, 3 files digitised; B2458, Army Personnel Files, multiple number series, 3 files digitised; K47, Correspondence files, annual single number series with 'W' prefix, 3 files digitised; PP892/1, Correspondence [client] files, annual single number series with 'W' prefix, 2 files digitised;](https://cdn.uploads.micro.blog/8371/2022/95643c6958.png)
I wrote up something for the #GLAMWorkbook on ‘Empty searches and hacking urls’: glam-workbook.net/url-hacki…
I’ve created a Zotero translator for the Libraries Tasmania catalogue. Using it, you can save metadata and digital resources to your own research database with a single click. Libraries Tasmania actually has three catalogues rolled into one – the main library catalogue, the archives catalogue, and the names index. The translator works across all three. Features include: Select and save items from a page of search results. Save individual items across the full range of formats.
Ok, I’ve submitted my Libraries Tasmania translator to the Zotero repository for inclusion. No doubt a bit of additional tweaking will be required. github.com/zotero/tr…
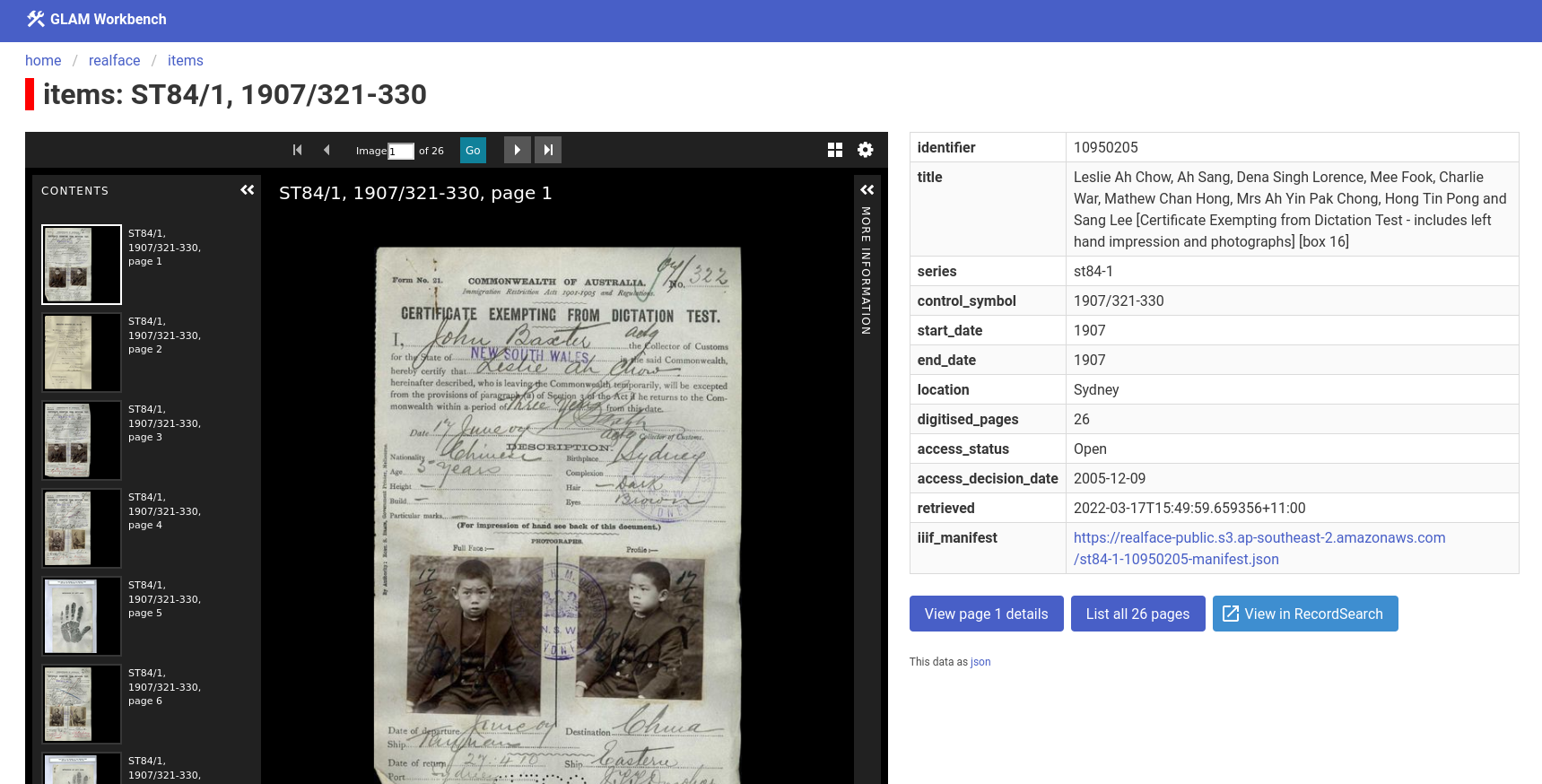
Getting to work migrating the Real Face of White Australia transcription site from scribeAPI (no longer maintained) to Zooniverse Panoptes. First the workflows and config, then the subjects, then the current transcription data…
It’s getting there – new Real Face of White Australia site using Datasette, IIIF, and Universal Viewer…
Ordering some #GLAMWorkbench stickers…

After much faffing about today I’ve got the latest version of the UniversalViewer building locally, and I also know how to listen for changes in the canvas index. Next, I have to do something about the CSS name clashes with Bulma…
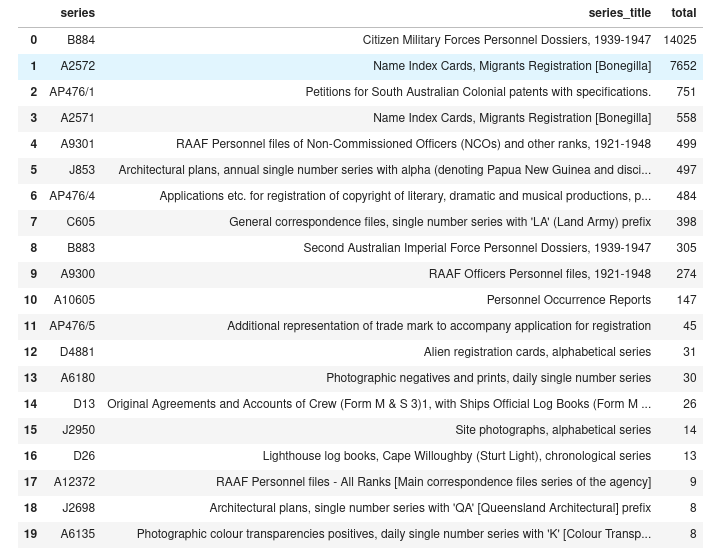
Files digitised by the National Archives of Australia this week: 25,981
Top series:
+14,025 in B884 (CMF personnel dossiers)
+7,652 in A2572 (Bonegilla name index cards)