New in Trove this week:
Berrigan Advocate (NSW)
Tingha Spectator & North Western Journal (NSW)
Tingha Miner & North Western Advocate (NSW)
Boggy Camp Tingha & Bora Creek (NSW)
New in Trove this week:
Berrigan Advocate (NSW)
Tingha Spectator & North Western Journal (NSW)
Tingha Miner & North Western Advocate (NSW)
Boggy Camp Tingha & Bora Creek (NSW)
Major changes to Trove newspaper titles this week:
+30,713 in Queanbeyan Age (NSW, end date now 1944)
+10,014 in Daily News (WA)
+179 in Inverell Argus (NSW)
Added to Trove newspapers this week:
+43,015 articles
+10,263 articles with corrections
+7,499 articles with tags
+243 articles with comments
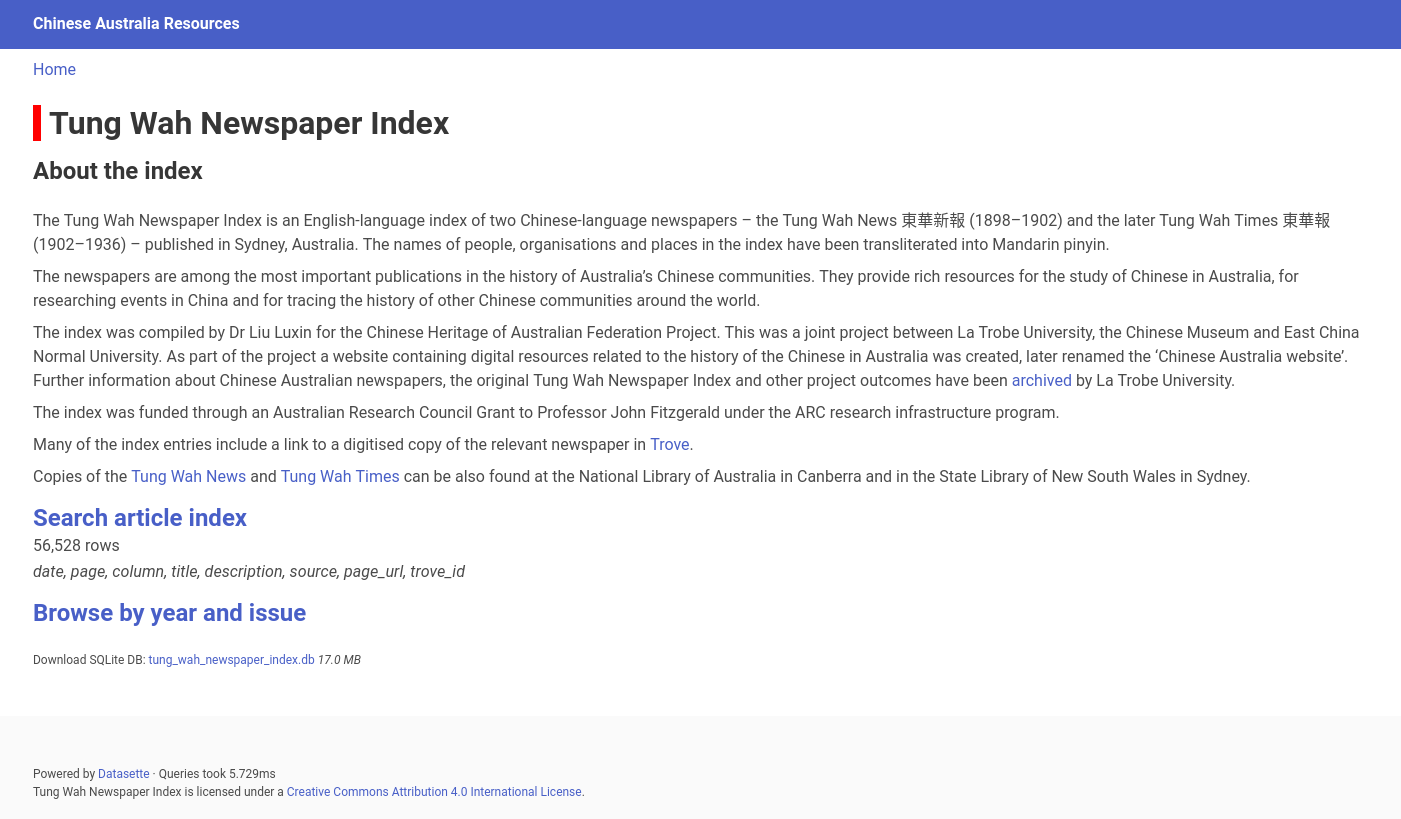
If you have a dataset that you want to share as a searchable online database then check out Datasette – it’s a fabulous tool that provides an ever-growing range of options for exploring and publishing data. I particularly like how easy Datasette makes it to publish datasets on cloud services like Google’s Cloudrun and Heroku. A couple of weekends ago I migrated the TungWah Newspaper Index to Datasette. It’s now running on Heroku, and I can push updates to it in seconds.
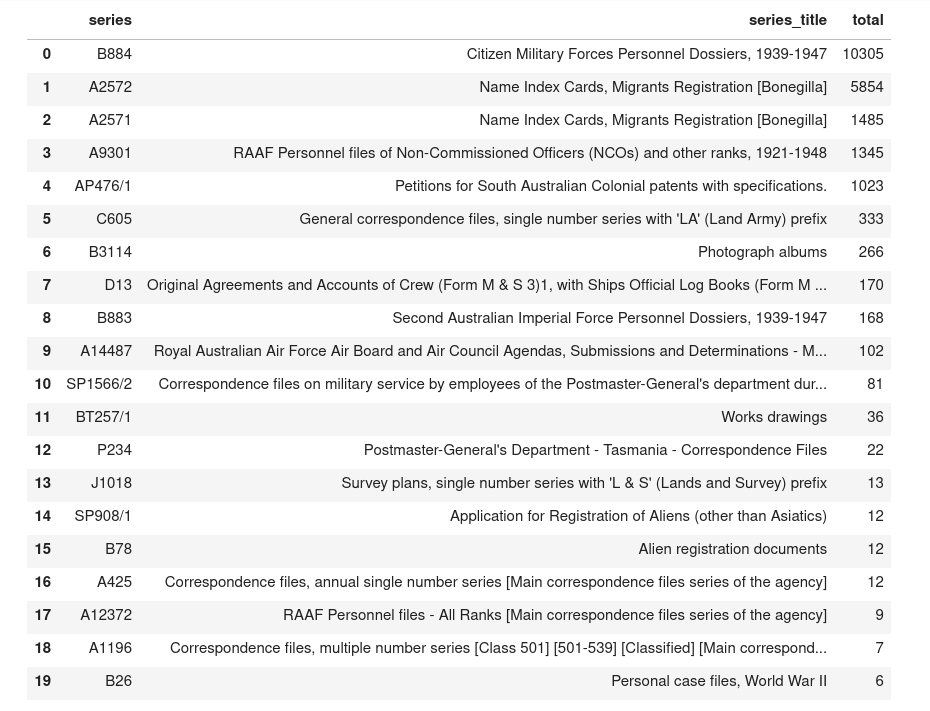
This week the National Archives of Australia digitised 21,488 files:
+10,305 in B884 (CMF personnel dossiers)
+7,339 in A2572 & A2571 (Bonegilla name index cards)
+1,345 in A9301 (RAAF personnel files)
Major changes to individual Trove newspapers this week:
+52,543 articles from The Daily News (WA)
+22,316 articles from Sunraysia Daily (Vic)
Changes to Trove newspapers this week:
+74,859 articles
+15,852 articles with corrections
+8,668 articles with tags
+592 articles with comments
I’m thinking about the Trove Researcher Platform discussions & ways of integrating Trove with other apps and platforms (like the GLAM Workbench). As a simple demo I modifed my Trove Proxy app to convert a newspaper search url from the Trove web interface into an API query (using the trove-query-parser package). The proxy app then redirects you to the Trove API Console so you can see the results of the API query without needing a key.
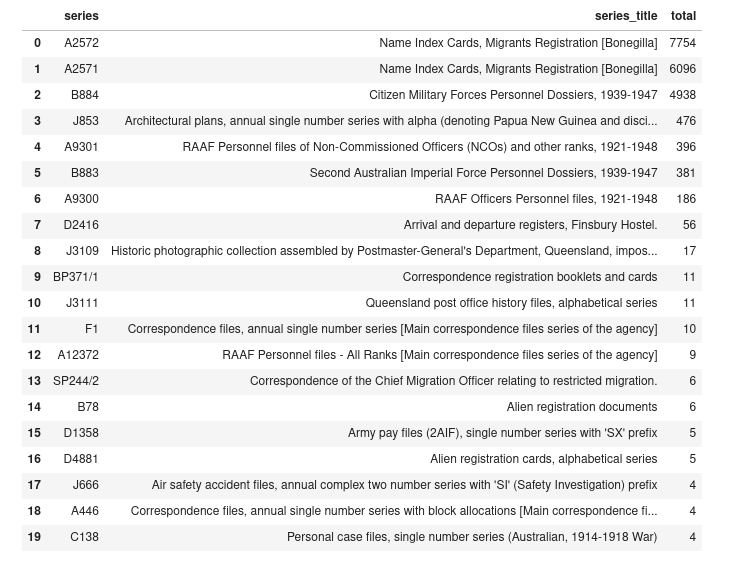
Also on tonight’s episode of ‘In GLAM This Week’, the NAA digitised 20,517 files. Of these:
13,850 were name index cards from the Bonegilla Migrant Camp (Series A2571 & A2572).
4,938 were CMF personnel files (Series B884)
This week’s changes in Trove newspapers:
+7,451 articles
+16,628 articles with corrections
+8,148 articles with tags
+491 articles with comments
Another overdue maintenance task completed! The Tung Wah Newspaper index has been migrated from a custom Django app on a now defunct web host, to a nice, neat Datasette instance on Heroku. https://resources.chineseaustralia.org/tung_wah_newspaper_index
TIL you can do date maths in Trove. Searching for date:[NOW-10YEAR TO NOW] in newspapers & gazettes returns articles from the last 10 years. Try it: trove.nla.gov.au/search/ca…
The ARDC is collecting user requirements for the Trove researcher platform for advanced research. This is a chance to start from scratch, and think about the types of data, tools, or interface enhancements that would support innovative research in the humanities and social sciences. The ARDC will be holding two public roundtables, on 13 and 20 May, to gather ideas. I created a list of possible API improvements in my response to last year’s draft plan, and thought it might be useful to expand that a bit, and add in a few other annoyances, possibilities, and long-held dreams.
Spending the evening updating the NAA section of the #GLAMWorkbench. Here’s a fresh harvest of the agency functions currently being used in RecordSearch… gist.github.com/wragge/d1…
This morning has been all bug hunting. But at least I’ve now found & fixed the problem, & released version 0.0.14 of the RecordSearch Data Scraper! https://github.com/wragge/recordsearch_data_scraper/releases/tag/v0.0.14 Also updated on Pypi.
Changes in Trove newspaper titles in the last week:
+26,731 articles from Daily News (WA)
+88,485 articles from Sunraysia Daily (Vic)
+6,810 articles from Dalgety’s Review (WA)
Changes in Trove newspapers in the past week:
+124,404 articles available
+17,306 articles with corrections
+8,269 articles with tags
+523 articles with comments
Somewhat unexpectedly the US National Archives & Records Administration catalogue includes some historic photos of Tasmania… catalog.archives.gov/search

I’ve got a site, I suppose I need to add some content now… glam-workbook.net #GLAMWorkbook
The ARDC is organising a couple of public forums to help gather researcher requirements for the Trove component of the HASS RDC. One of the roundtables will look at ‘Existing tools that utilise Trove data and APIs’. Last year I wrote a summary of what the GLAM Workbench can contribute to the development of humanities research infrastructure, particularly in regard to Trove. I thought it might be useful to update that list to include recent additions to the GLAM Workbench, as well as a range of other datasets, software, tools, and interfaces that exist outside of the GLAM Workbench.